1. はじめに:Kaggleに取り組む意義
Kaggleは実務直結型のAIスキルを証明できる場
Kaggleは世界最大級のデータ分析・機械学習コンペで、実務に近い形でモデル構築を行う。獲得したメダルや称号(Kaggle Expertなど)は、「実際にAIを使って成果を出せる人材」であることの強い証明となり、採用や案件参画で高く評価される。
資格よりも「実践力」を示せるのがKaggleの強み
E資格などの試験型資格と違い、Kaggleは
- データ理解
- モデル設計
- 精度改善
AI・LLM分野に入りたい人にとって最も分かりやすい登竜門
AI案件の経験がない人でも、
- Kaggleで継続的に取り組む
- メダルなどの成果を出す
今回はLLM系Kaggleコンペにフォーカス
Kaggleにはテーブル・画像・時系列など多様な分野があるが、近年はLLM(大規模言語モデル)関連の仕事・案件が急増しているため、本研修ではLLM系コンペの攻略思考・実践方法・メダル獲得までの考え方を中心に解説する。
実際にメダル獲得経験者の思考プロセスを学べる
単なる理論説明ではなく、
- どのようにコンペを選ぶか
- どう考えてモデルを改善するか
- メダル獲得まで何を意識するか
2. コンペティションの選び方と初期分析
題材と目的
実際にメダルを獲得したLLM系Kaggleコンペ(Jigsaw Agile Community Rules Classification)を例に、どのようにコンペを選び、どう考えて参加・攻略したか を解説。
コンペ内容の本質
Redditのコメントが、各コミュニティ(サブレディット)のルールに違反しているかを判定する二値分類タスク。
LLMを使って「ルール違反か否か」を予測するのがテーマ。
コンペ説明文の読み方
- 参加を決める前:Google翻訳などで ざっくり理解
- 参加を決めた後:ChatGPT / Geminiなどを使い 正確に理解
コンペ選定の基準
- LLM系コンペは複数あるため、全てに出る必要はない
- 以下を重視して判断:
- 上位に金・赤ランクの有名Kagglerが多いか
- リーダーボードや順位が信頼できそうか
- コンペ設計がしっかりしていそうか
参加タイミングの考え方
- 必ずしも開始直後から参加する必要はない
- 終了1か月前に:
- リーダーボード上位(例:上位20)
- 公開ノートブック(Codeタブ)
参加判断のポイント
- 公開コードを見て
- 再現できそうか
- 少し工夫すれば上を狙えそうか
→ ゼロからの挑戦は上級者向け。既存解法を土台にできるかが重要。
まとめ(Kaggle初心者向け指針)
- コンペは「有名Kagglerが集まる質の高いもの」を選ぶ
- 最初は完璧理解より全体像把握
- 終盤1か月で参戦し、公開コードから改善余地を探す
- 「自分が伸ばせそうかどうか」を基準に参加を決める
3. データセットの理解と評価指標
コンペ内容の把握方法
まずはコンペページを開き、GeminiやChatGPTなどで概要を日本語化して全体像を掴む。最初から細部まで理解しようとせず、概要→データ→コード→再度概要、という往復で理解を深める。
最初に必ず確認すべきポイント
- 評価指標(Evaluation)
- 提出形式(Submission)
今回の評価指標の要点
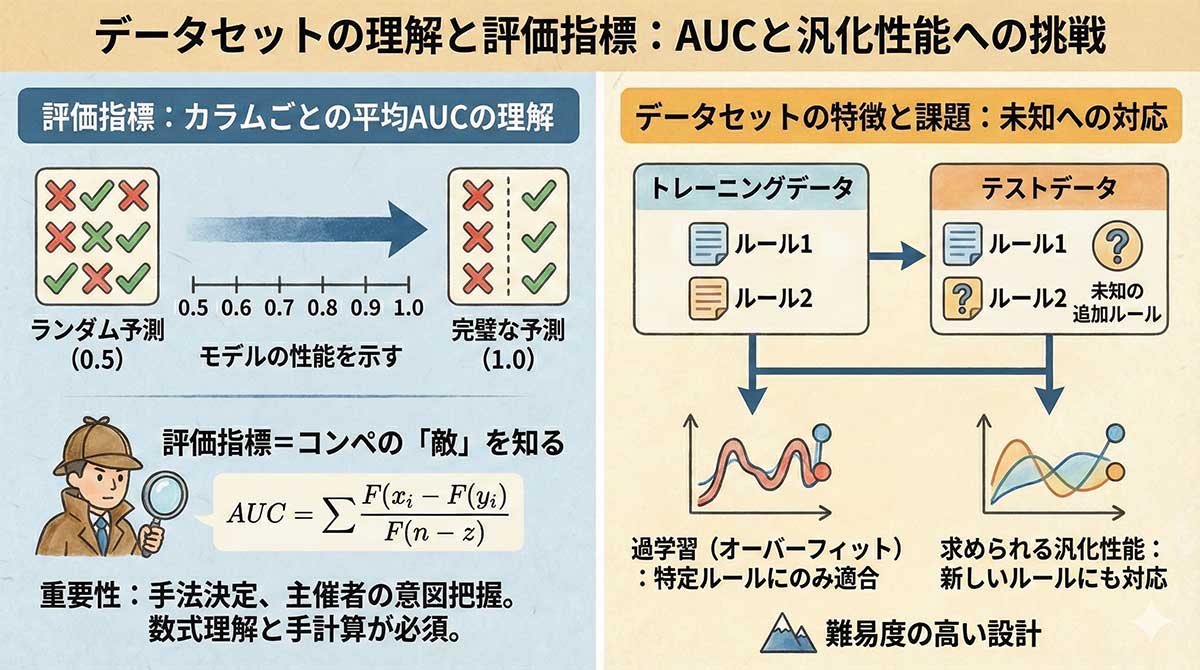
- タスクは 二値分類
- 指標は ルールごとのAUCを平均
- 単一ルールに強いだけのモデルは評価されにくい
評価指標の理解レベル
- AUCのような基本指標は性質と意味を理解する
- 複雑な指標は数式レベルまで理解が必要な場合もある
- 実際にCSVを作り、手元でスコア計算して挙動を確認するのが有効。
データ構造の重要ポイント
- トレーニングデータには 2つのルールのみ
- テストデータには 未知の追加ルールが含まれる
データの主な構成要素
- コメント本文(テキスト)
- ルール情報
- サブレディット(コミュニティ/ジャンル)
- ルール違反例・非違反例(エグザンプル)
- 予測対象:ルール違反かどうかの 確率
コンペ設計の意図
- 既存ルール専用ではなく、新しいルールにも対応できるモデルを作れるかを評価
- そのため、学習データとテストデータの条件が意図的にずらされている。
Kaggle攻略の基本スタンス
- 初期段階では「完璧理解」より「構造理解」
- 評価指標とデータ設計の意図を読み取ることが最優先
- 「主催者は何を測りたいのか」を常に考える
メールアドレスを登録いただくと、
本講義のすべての書き起こしと
録画を見ることができます。