RAGとは?
では、RAGの全体像という話に入っていきます。
まず、RAGとは何かというと、一言でいえば、右の図のようなアーキテクチャのことです。
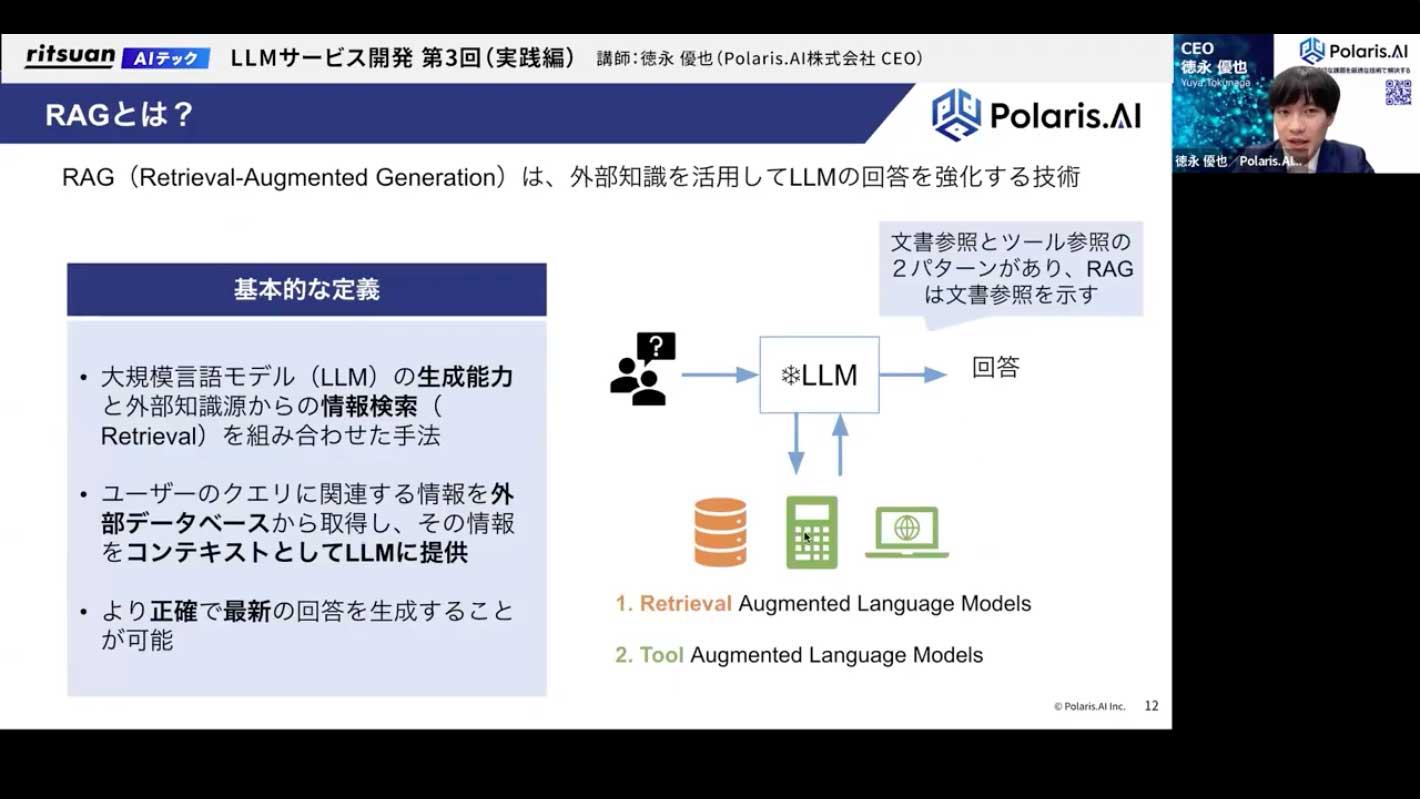
LLMは、基本的に学習したデータや知識しか答えることができません。
そのため、社内ドキュメントや業界特有の専門的な内容には答えづらいという弱点があります。
その弱点をどう補うか、という技術がRAGです。基本的な定義としては、LLMが回答を生成する際に、社内のデータベースや文書などを参照させ、その情報をもとに答えさせることで、より正確で最新の回答を生成させる技術です。
分かりやすい図で示すと、このようになります。
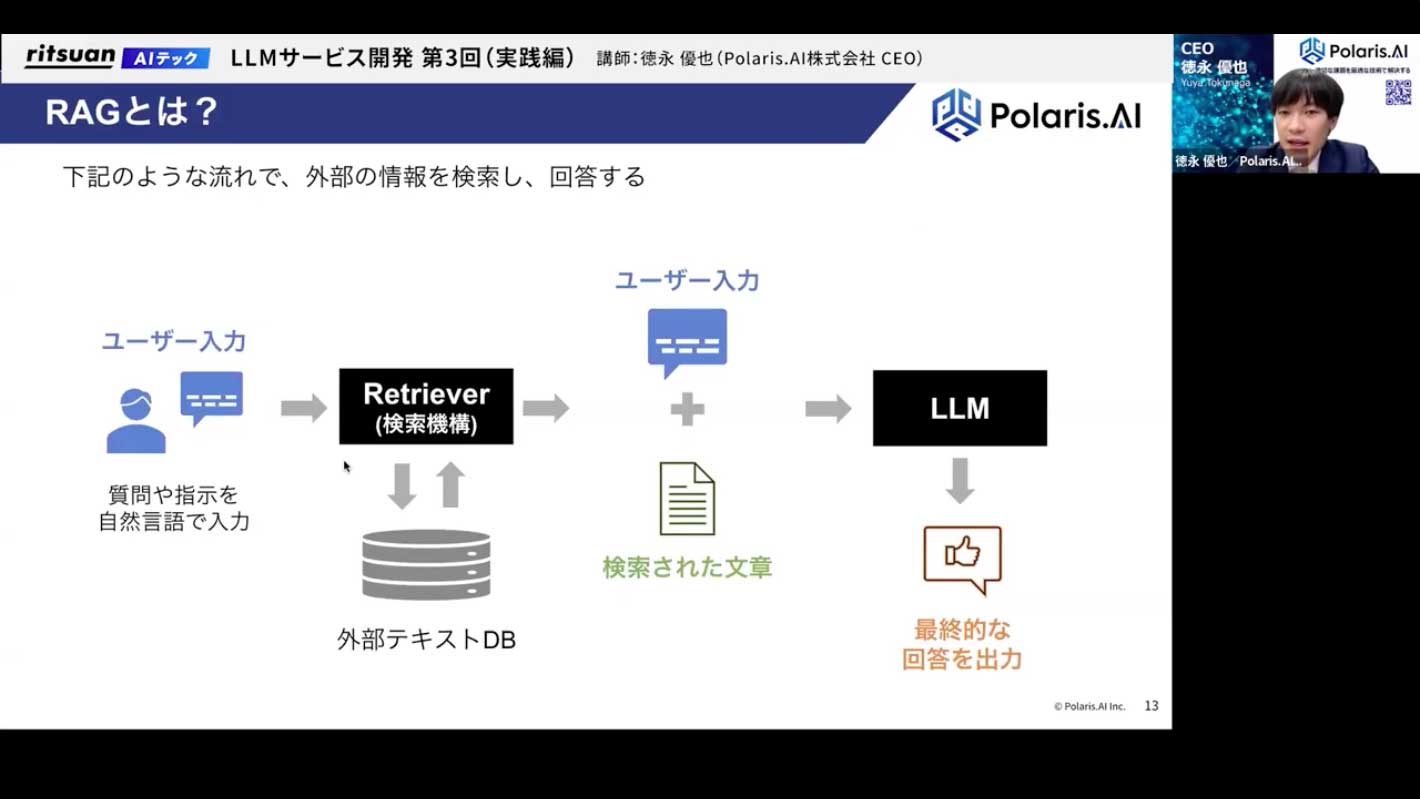
- ユーザーが何か質問を入力します。
- 「レトリバー」と呼ばれる検索機構が、外部のテキストDB(社内ドキュメントなどが格納されている場所)から、ユーザーの質問に答えられそうな情報を探しに行きます。
- 見つけてきた情報を、ユーザーの入力(質問)と一緒にLLMに渡します。
- LLMは、与えられた最新かつ正確な情報をもとに、ユーザーの質問に対してより質の高い回答を生成します。 この一連の流れ、アーキテクチャ全体を「RAG」と呼びます。
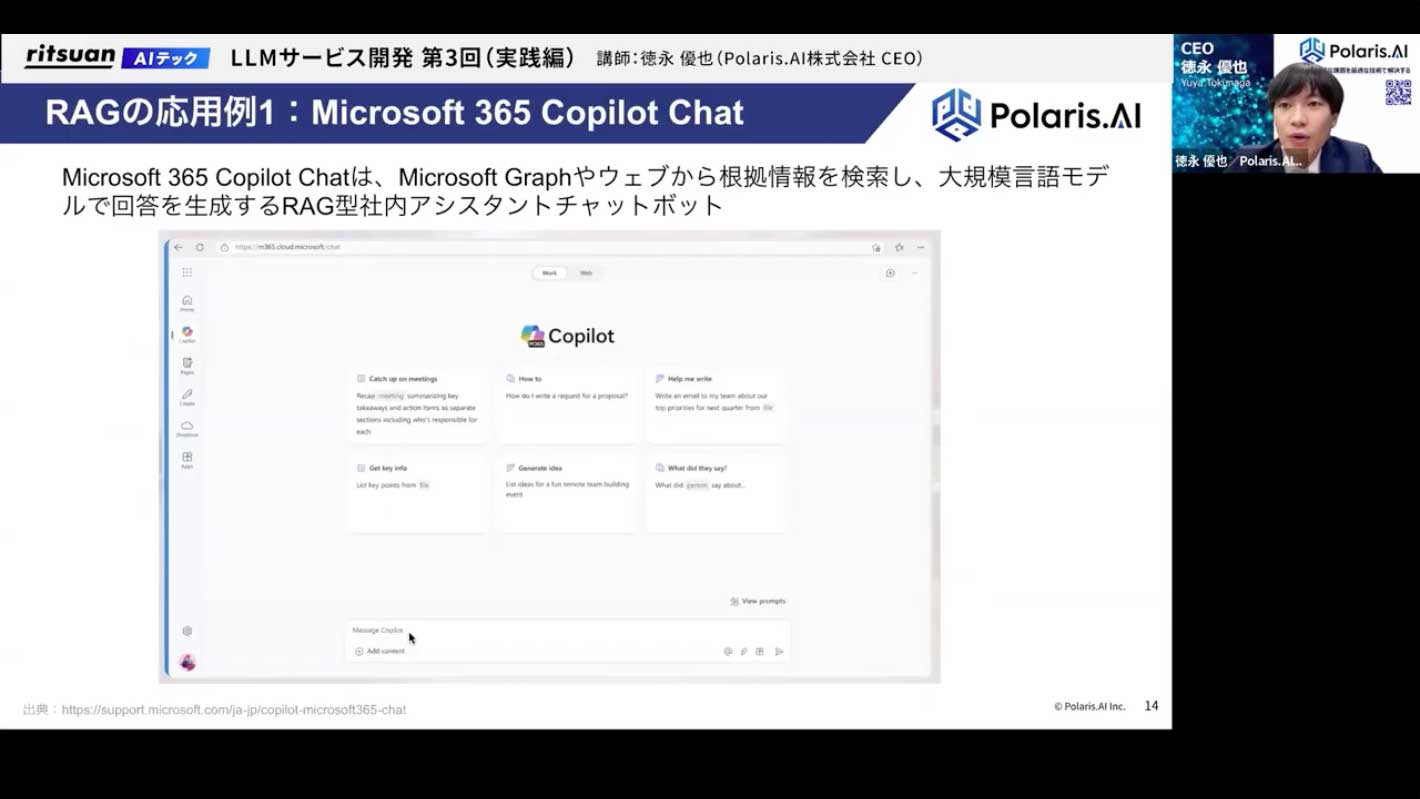
よくあるユースケースとしては、Microsoft 365 Copilotが有名です。導入されている会社も多いかと思いますが、チャット形式で様々な質問に答えてくれます。これは、連携された社内情報やウェブ上の情報を基に応答しており、まさにRAG技術を応用したチャットボットです。
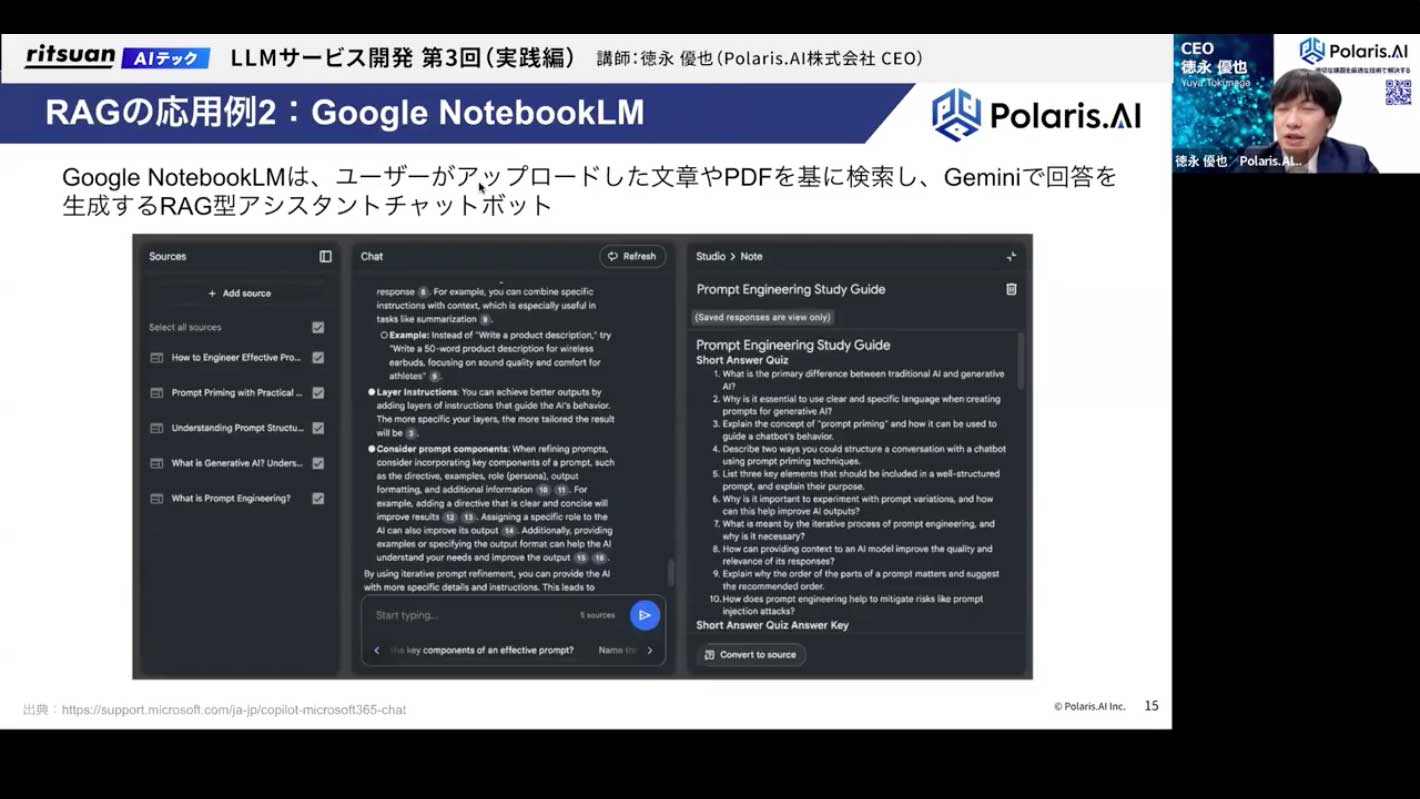
後ほど体験していただくGoogleの「NotebookLM」も、RAGをうまく応用した非常に便利で使いやすいツールです。
ユーザーがアップロードした文書、PDF、YouTubeのリンク、Googleスライドなどを情報源として、その内容に関する質問に答えてくれます。例えば、1時間の面白そうな動画があったとして、それを全部見るのではなく、NotebookLMにURLを投げて質問すれば、内容を要約して教えてくれる、といった使い方ができます。これも、YouTubeの動画を文字起こしし、それをうまく検索してLLMに渡し、回答を生成させるという、RAGの技術が使われています。
また、Notionを使っている方は、課金すると使える「Notion AI」も同様です。
Notion内のページを基に質問に答えてくれるこの機能も、RAGを使ったツールの一種です。
何が言いたいかというと、昨今よく使われているツールのほとんどは、RAGを応用したものである、ということです。それぐらい、RAGは応用範囲の広い技術であり、弊社が受託する案件の中でも、ニーズの高さは一、二を争う技術分野です。
RAGは難しそうに聞こえるかもしれませんが、アーキテクチャは先ほど示した通りで、実はそれほど複雑ではありません。
これをコードベースで見てみると、さらにそのシンプルさが分かると思います。
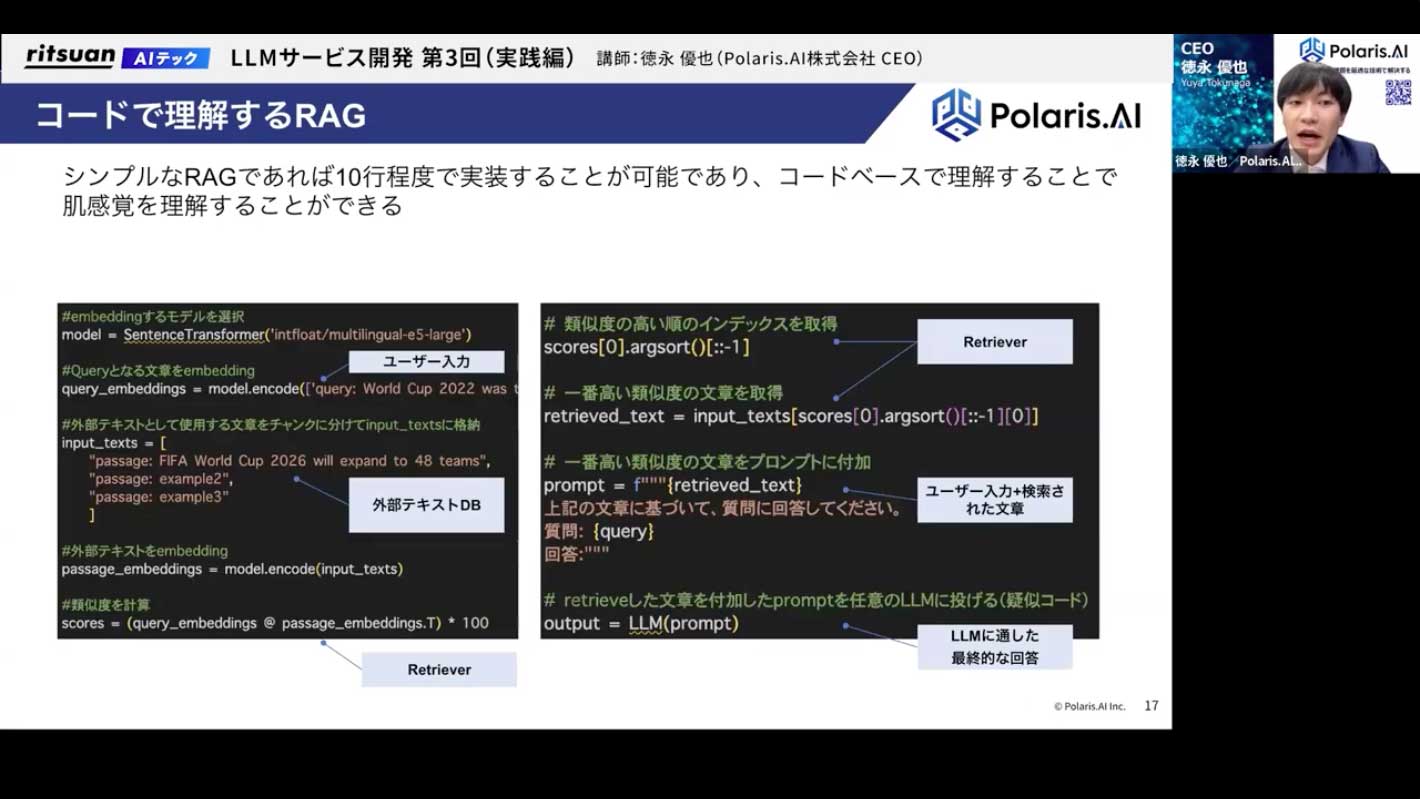
これはミニマムなRAGのコード例ですが、わずか10行程度で表現できてしまいます。
図と対応させて説明します。
- まず、ユーザーの入力(クエリ)があります。これをembedding、つまり数値のベクトル形式に変換します。
- 同様に、外部テキストDB(ここでは3つの文章を持つリスト)の各文章も、あらかじめベクトル化しておきます。
- 次に、レトリバーの処理です。ユーザー入力のベクトルと、DB内の各文章のベクトルの「類似度」を計算します。ここでは内積を計算しており、ベクトルが似ていればいるほど値が1に近づくため、最も値が大きいものが、最も質問に関連性の高い文章であると判断できます。
- この計算によって、DB内から最も関連性の高い文章のインデックス(場所)が特定されます。
- 最後に、特定された文章をプロンプトに埋め込み、LLMに渡すことで、精度の高い回答が得られます。
これがRAGの基本的な仕組みです。
そして、この仕組みは精度向上を考える上でも基礎となります。
例えば「精度が悪い」となった場合、問題は「ユーザー入力」「検索機構(レトリバー)」「DBのデータ」「プロンプト」「LLM本体」のどこにあるのか、というように問題を分解し、ボトルネックを特定して潰していくことで、精度は向上していきます。
なぜ外部知識を使いたいのか?
では、なぜ外部知識を使いたいのか、RAGを使うと何が良いのかを深掘りします。
一言でいえば、LLMが抱える問題点を解決できるからです。

- 知識の限界: LLMは学習データ以外のことを知らないため、最新情報や、非常に専門的なドメインの知識が欠けています。
- 学習コストの高さ: 新しい知識をLLMに覚えさせる「ファインチューニング」は、高品質なデータセットが必要な上、学習コストも非常に高額です。
- ハルシネーション: LLMは統計的にそれらしい回答を生成するため、事実に基づかない誤った情報を生成してしまうリスクが常に伴います。
RAGは、これらの課題をうまく解決します。
- 外部DBから最新・正確な情報をその都度引っ張ってくるため、最新性・専門性を担保できます。
- LLM自体のパラメータをいじる必要がないため、ファインチューニングに比べてはるかに低コストで、学習と同様の効果が得られます。
- 回答の根拠となった外部ソースを明示できるため、ユーザーは情報の正しさを確認でき、信頼性が向上します。
こうした利点から、RAGは社内ナレッジ活用、カスタマーサポート、研究開発など、非常に幅広い分野で応用されています。

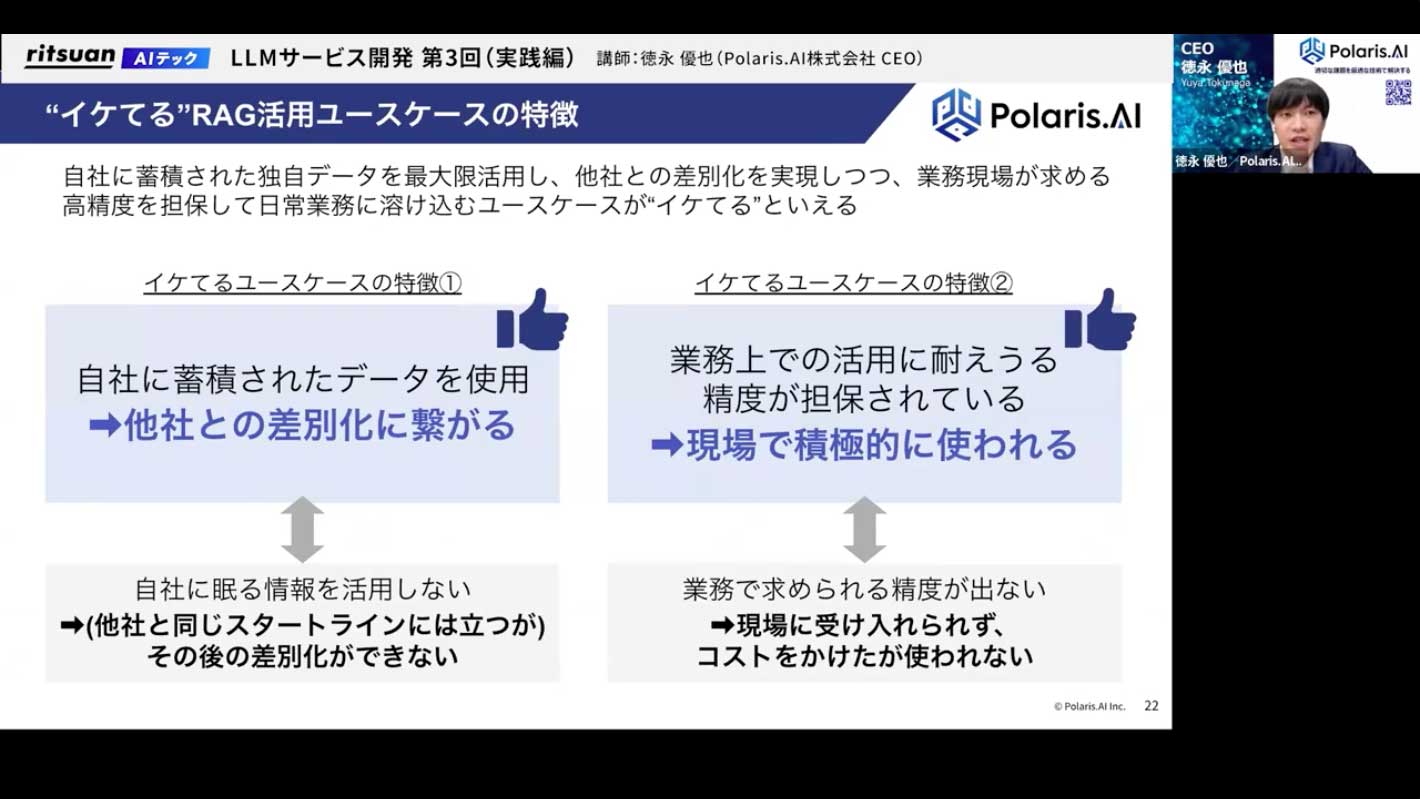
特に、社内に蓄積された独自のデータをきちんと整理し、RAGに活用することで、属人化していた知識を誰もが自然言語で引き出せるようになり、業務の省人化に大きく貢献します。ただし、そのためにはデータをきちんと整理し、精度を上げていくことが非常に重要です。
リツアンと面談していただくと、
すべての書き起こしと録画を見ることができます。