「プロンプトを構造化したり、指示を具体的にしているのにいまいち伝わっていない気がする…」
「できれば作りこみをせずに精度を上げたい…」
ここ数年で生成AIの性能や機能は大幅に強化されましたが、それでもあと一歩、かゆい所に手が届かないということはあるかもしれません。
追加学習やRAGの開発、外部ツールとの連携など調整方法はいくつか知られていますが、そこまでの予算や労力はかけられないことが多いでしょう。
ですが、もし、簡単なプロンプトの工夫だけでより良い成果が得られるとしたら…?
今回ご紹介するのは、Googleの研究チームが2025年末に発見したプロンプト手法です。
そのテクニックは驚くほど簡単で、「同一の入力をそのまま2回繰り返す」だけ。
同じQUERY(クエリ)を2回繰り返すことから、「QQメソッド」と呼ばれています。
本稿では、Google ResearchがarXiv(アーカイブ)で公開した “Prompt Repetition Improves Non-Reasoning LLMs” を一次情報として参照しつつ、使いどころと注意点を整理します。
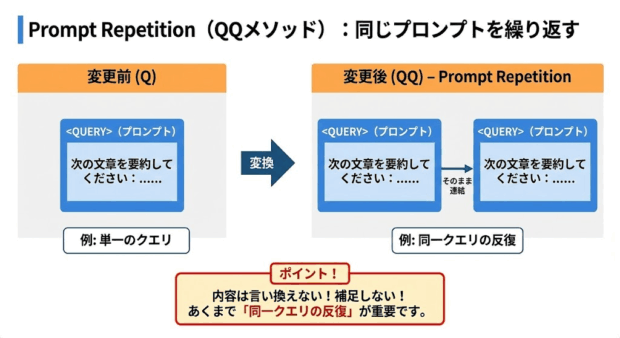
手法はシンプルで、同じプロンプトをそのまま連結して2回入力するだけです。
論文では、入力を次のように変換すると説明されています。
<QUERY><QUERY><QUERY>例えば、下記のようなイメージです。
(Q)
次の文章を要約してください:......
(QQ / Prompt Repetition)
次の文章を要約してください:......
次の文章を要約してください:......
ポイントは、2回目に内容を言い換えたり、補足したりしないことです。
あくまで「同一クエリの反復」になっていることが重要です。
論文が主に主張しているのは、推論(reasoning)を使わない設定において、プロンプトの反復が幅広いモデル・ベンチマークで精度を高めた、という点です。
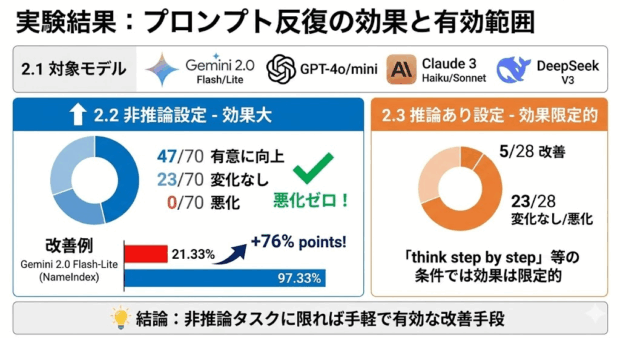
論文の実験では、評価対象として主要LLMプロバイダの公式APIで動作する7モデルが使用されています。
論文では、ベンチマークとモデルの組み合わせを70通り用意して、推論を行わない条件でプロンプト反復による性能の変化を確認したとしています。
その結果として、47のケースで統計的に有意な改善が見られ、性能が悪化したケースは皆無だったというのです。
さらに、特定のカスタムタスクでは大幅な改善例も提示されています。
例えば、NameIndex(人物名・固有名詞の識別、関連付け、記憶保持能力を測るテスト)においてGemini 2.0 Flash-Liteの正答率が 21.33%→97.33% に上がった、と記載があります。
「think step by step」のように推論を促す条件では、効果は限定的で、28ケース中で改善が見られたのは僅か5ケースに留まったと報告されています。
これらの実験結果から、プロンプトの反復は「何にでも効く魔法のテクニック」とまでは言えませんが、非推論タスクに限れば手軽で有効な改善手段だと言えるでしょう。
なぜ、全く同じプロンプトを繰り返しただけで性能が向上するのでしょうか。
論文では、言語モデルの性質によるものと考察されています。
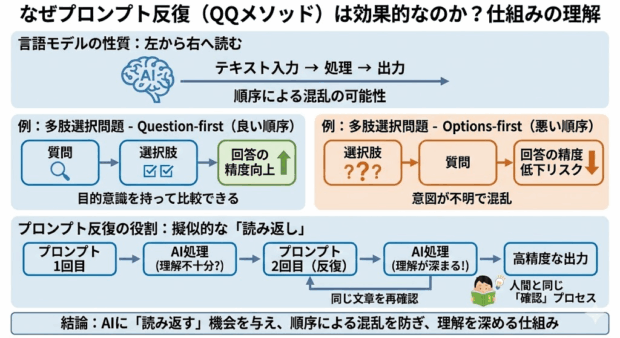
言語モデルは基本的に左から右へと文章を読み込んで処理するため、同じ内容でも、単語や文章の順序によって、読み取り方や優先順位が変わってしまうことがあります。
例えば、多肢選択問題では、質問と選択肢の順序を変えただけで回答の精度が変わることがあります
プロンプトの反復は、「同じ文章をもう一度読ませることで、順序による混乱を防ぐ仕組み」ということができます。
二回目の読み込み時には同じ内容を一度読み込んでいるので、一回目を読み込んだ時より正確に理解できるということです。
人間で例えると、文章を読んで一度で理解しきれなかった時、確認のために同じ文章をもう一度読み直すことがあると思います。
生成AIは「左から右に順番に読む」という性質上、一度通り過ぎた文章を読み直すことが難しいので、同じプロンプトの中に「同じ文章を読み返して理解を深める」ポイントを設定してあげる必要があるのです。
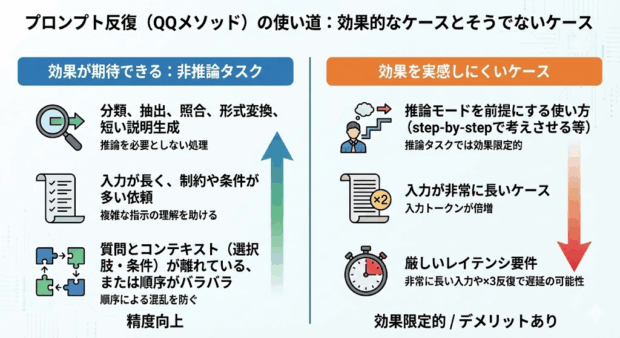
論文の結論から考察すると、プロンプトの反復テクニックは、次のようなケースで効果が期待できます。
一方で、以下のようなケースでは効果を実感しにくいでしょう。
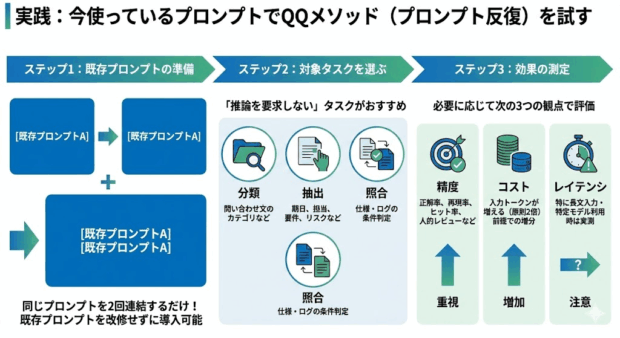
QQメソッドの強みは、同じプロンプトを2回貼り付けるだけなので、既存プロンプトを改修せずに導入できる点です。
ぜひ、気軽に試してみましょう。
「推論を要求しない」タスクがおすすめです。
例:
必要に応じて次の3つの観点で評価しましょう。
QQメソッドは精度を重視するテクニックですが、API利用の場合はコスト増加も見逃せないポイントです。
QQメソッドは、同じプロンプトを2回繰り返すだけという極めて簡単な工夫で、生成AIの精度を向上させることができるテクニックです。
一方で、推論を前提とした使い方では効果が限定的であり、長文入力ではコスト増と、一部モデルで遅延増の例外も指摘されています。
しかし、作りこみの必要なくすぐに試せる精度向上のテクニックとして覚えておくと、役に立つ場面は多いでしょう。