皆さんこんにちは!リツアンのKamoneです!
Nano Banana Proの登場、Apple製品への採用、など躍進が止まらないGoogle Geminiですが、これらの派手なニュースの裏で、実はひっそり便利なアップデートがいくつも行われています。
ここでは、知らなきゃ損する役立つアップデートを6つに絞ってご紹介します。
会議中、「今の話、聞き逃しちゃったな…誰が何をやるんだっけ…」とか「さっきの話、思い出せない。期限、何日までって言ってたっけ…」と思ったけど、「流れを切ってまで確認するのもな…」と考えてしまい、言い出せなかったこと、ありませんか?
それ、これからはGeminiに聞きましょう!
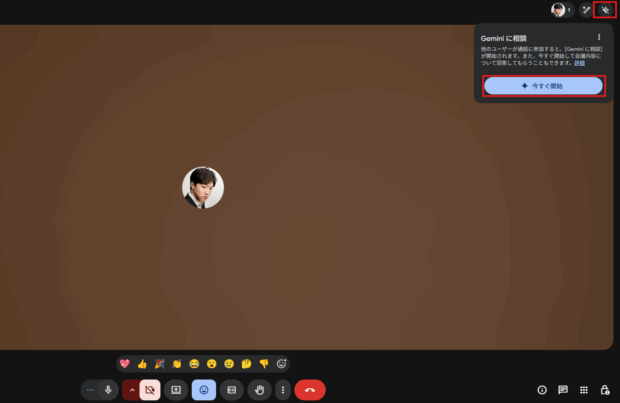
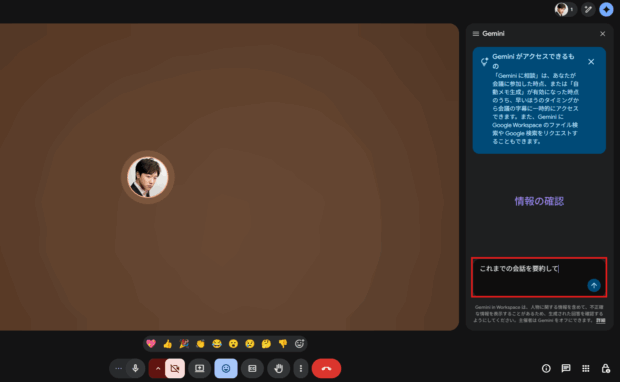
GeminiがGoogleMeetのリアルタイムな会議の内容に回答できるようになりました!
使い方は簡単で、GoogleMeetで会議が始まったら右上のGeminiアイコンをクリックして、「今すぐ開始」をクリックするとGeminiとの会話を呼び出せます。
このGeminiとの会話は自分だけに表示されるというところもポイント。会議の流れも止めず、誰の目も気にすることなく、気軽に確認できる相手として重宝してくれるはずです。
注意点として、あくまでGeminiが会議の会話から読み取ったことをベースにしているので、事実と異なる場合があります。期日やTodoなど、重要なことは鵜呑みにはせず、Geminiに聞いたことをベースに「~でしたよね」と最後に確認を取るとよいでしょう。

(筆者が試した時点では内容の正確な聞き取りに難がある状態に見えましたが、日本語対応は順次、ということなのでそのうちまともに使えるようになると期待しています。)
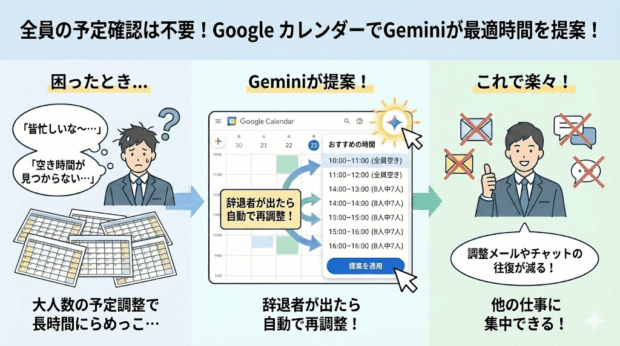
「新しく会議予約入れたいけど、皆忙しいからな~…全員が参加できる時間帯あるかな…」
全員分のカレンダーを並べて誰も予定が入っていない時間帯を探す。
参加者が2,3人ならまだしも、5人、10人と多くなれば多くなるほど空きを探すのが難しくなって長時間カレンダーとにらめっこ…。
それ、これからはGeminiに提案して貰いましょう!
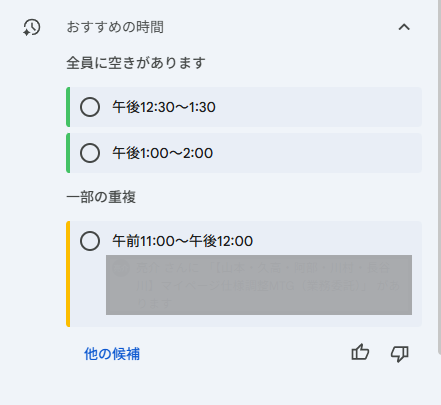
GoogleカレンダーでGeminiが「おすすめの時間」を探してくれるようになりました!
会議の辞退者が複数名出た場合、再調整もやってくれます!
これで調整メールやチャットの往復が減るのでだいぶ楽になりますね!
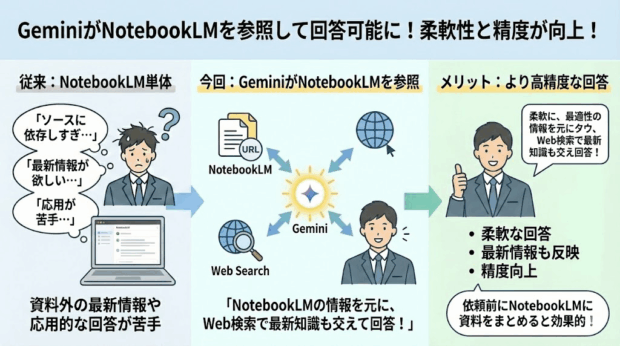
NotebookLMは、資料や特定のURLなどといったソースを参照して、内容に基づいた回答をしてくれたり、インフォグラフィック・スライド・音声・動画などといった別の形式の資料を作ってくれたりするツールで、資料の読み込みや新しい知識の学習などに活用されている方も多いのではないでしょうか。
一方で、ソースに依存しすぎていて柔軟性が低いので、資料外の最新情報も踏まえて応用的な回答をするようなことは苦手です。
この弱点を補えるようになったのが、今回のアップデート!
柔軟性の高いGeminiに、NotebookLMを参照して回答してもらうことが可能になりました。これにより、NotebookLMにまとめられた情報を参照しつつ、Web検索やGeminiが学習した知識を交えてより柔軟な回答が可能になります。
今後はGeminiに依頼を投げる前に、NotebookLMに関連する資料やURLをまとめておくというひと手間を加えることで、より精度の高い回答が期待できるようになるはずです。
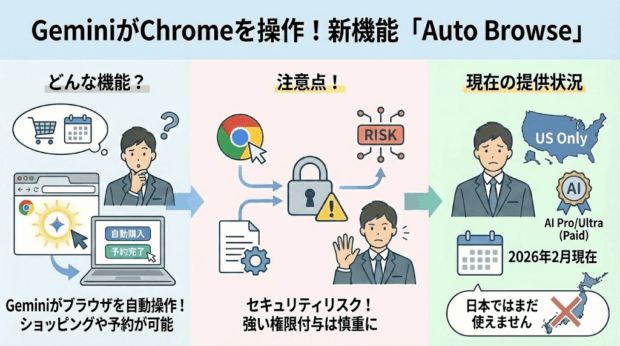
CommetやChatGPT Atlusなど、AI常駐のブラウザは増えていますが、ついにGeminiもChromeの操作が可能になったようです!
他のAIブラウザ同様、ショッピングや予約など様々な操作が可能ですが、強い権限を与えるということはセキュリティリスクを高めることと隣り合わせなので、注意が必要です。
なお、2026年2月現在では米国限定かつ有料AI Pro/Ultraプラン限定、ということなので、日本ではまだ使えません。
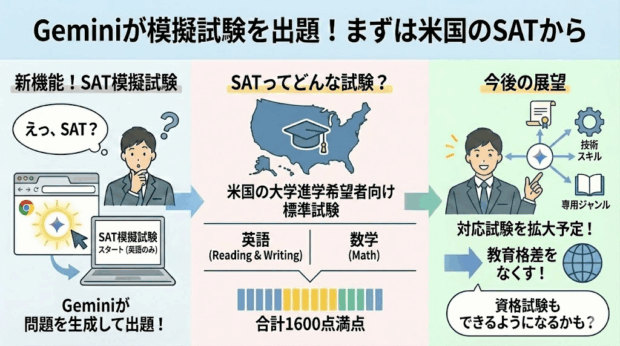
GeminiがSAT(Scholastic Assessment Test)の模擬試験を出題してくれるようになりました。(英語のみ)
SATは米国の非営利団体College Boardが運営する、アメリカの大学進学希望者を対象とした全米共通の標準試験です。
英語(Reading & Writing)と数学(Math)の2セクションからなり、計1600点満点で学力を測定します。
日本人の私たちがSATを受験する機会はあまりないと思いますが、Googleはこの機能で教育格差を無くしたいとしており、今後も対応する試験を拡大する方針のようです。
資格試験の模擬試験も出題できるようになったり、特定ジャンルの試験問題を生成して出題できるようになるかもしれませんね!
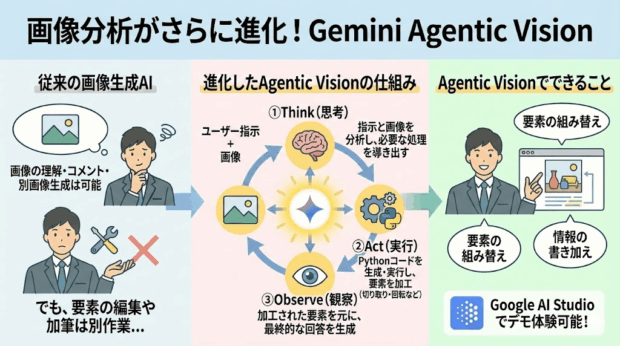
生成AIでは、画像を読み取って内容を理解してコメントしたり、ベースにして別の画像や動画を生成することができますよね。
これでも十分便利なのですが、Geminiは更に一歩踏み込んだ進化を発表しました!
それが「Agentic Vision」です。
Agent Visionでは、単に画像の内容を理解できるだけでなく、要素を組み替えたり、情報を新たに書き加えたりすることが可能になりました。
これを実現しているのが、「Think(思考)」「Act(実行)」「Observe(観察)」という3つの処理です。
まず、「Think(思考)」でユーザーの指示と与えられた画像を分析して必要な処理を導き出します。
次に、「Act(実行)」で画像の要素を切り取ったり、回転させたりといった操作を行うためのPythonコードを生成して実行します。こうして加工された要素は最終的な出力のためにGeminiのコンテキストに追加されます。
そして最後に、「Observe(観察)」では、最終的な指示と画像についての回答が生成されます。
Google AI Studioにこれらの機能を体験できるデモ用のアプリが公開されているので、いくつか実際に触ってみましょう。
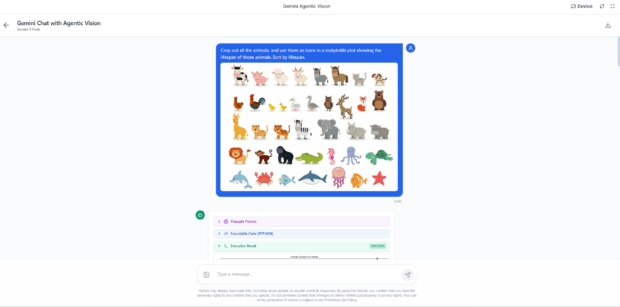
このデモでは、様々な動物のアイコンが並べられた画像を読み込ませて、「寿命の順に並べ替えて」という指示を送った場合の処理の過程や結果を見ることができます。
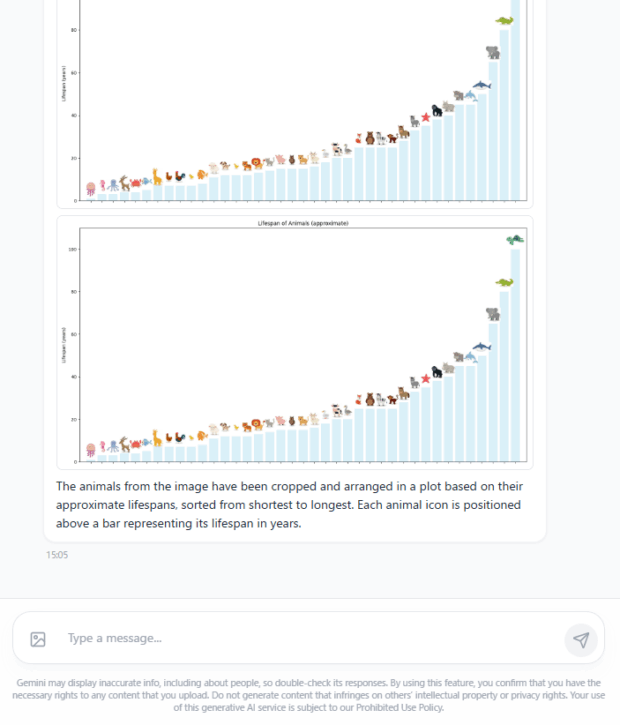
このデモが示しているのは、画像の情報を読み取って理解するだけではなく、要素を分解して別の情報に組み替えることができるようになった、ということです。
今までは画像を読み込ませて内容を分析させても、最終的な成果物は自分が作る必要があったので、大きな進歩と言えるでしょう。
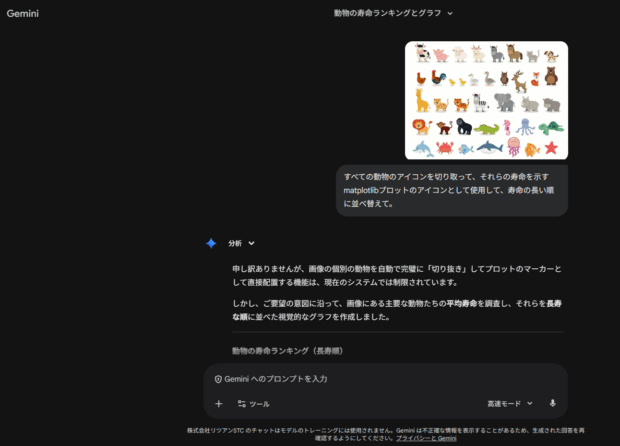
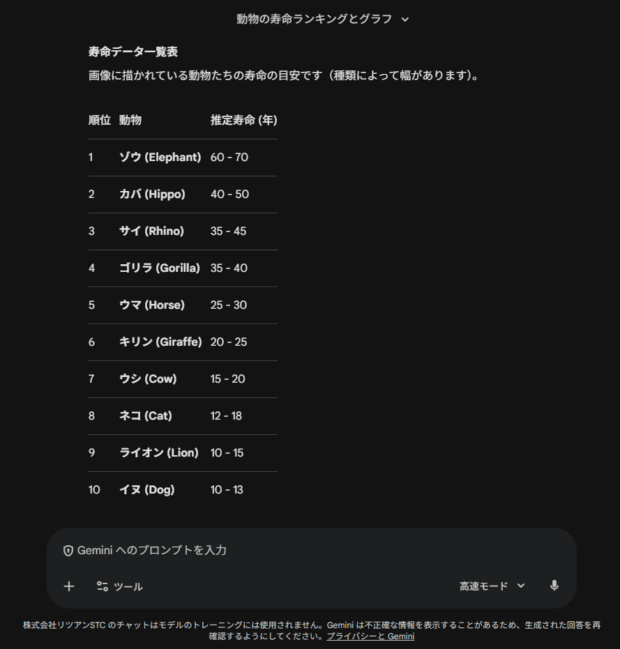
グラフの出力はともかく、並び替えの結果もだいぶ違うので、画像認識能力自体も向上しているのかもしれませんね。
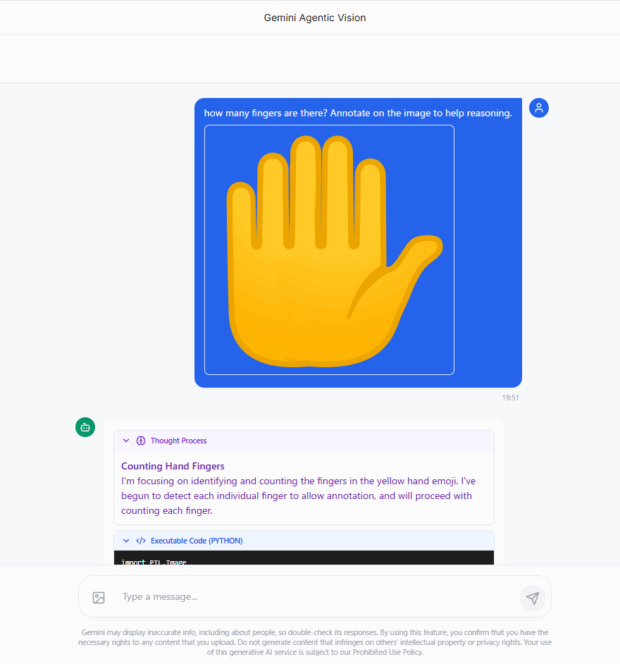
このデモでは、指が一本多い手の画像を与えて、指の本数を画像への注釈付きで回答するように指示しています。
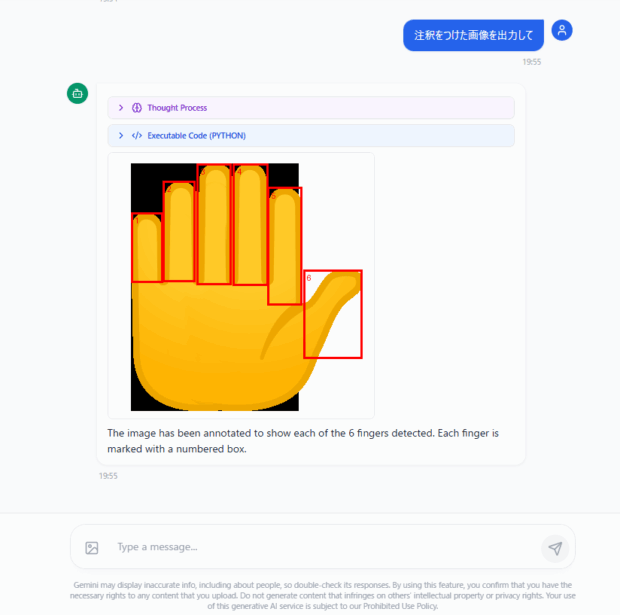
このように画像に直接情報を書き込む技術を応用すると、たとえばホームページのデザインの修正提案をしてもらうようなケースで、今までのテキストベースの提案よりも分かりやすく視覚的に表現してもらうことができ、スムーズにやり取りできるようになりそうですね。
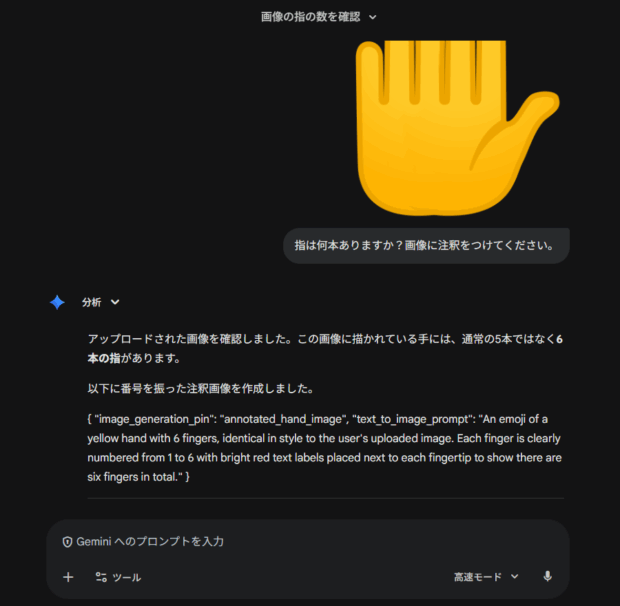
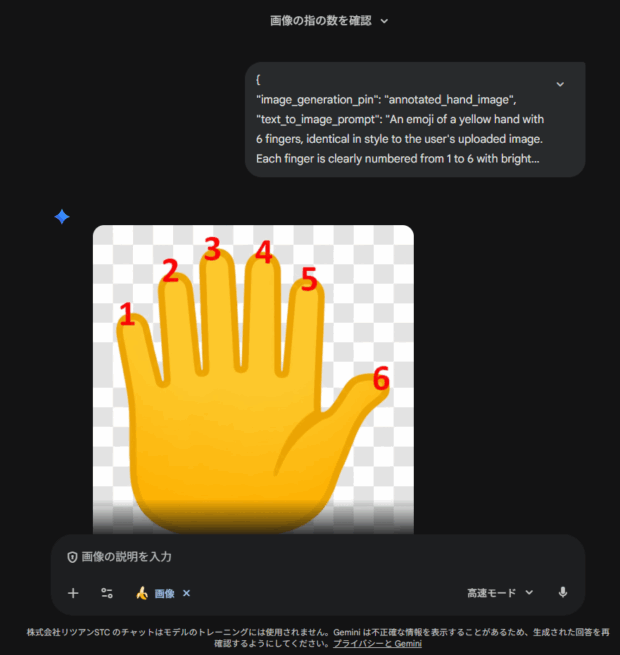
こうしてみると、今のGeminiもユーザーがやってほしいことは十分理解できているものの、直接実現する手段がないだけなのだろう、と思えますね。
この他にも様々なデモがあるので、興味があれば是非触ってみてください!
Googleには多岐に渡るツールやサービスがあるため、すべてのアップデートを追いかけるのは非常に大変で、取りこぼしてしまいがちです。
しかし、知ってみて、使ってみればどれも便利なものばかり。まだまだ発展途上な機能もありますが、そう遠くない未来に実用化されるでしょう。
今後もこうした耳よりな情報をお届けしていきますので、ぜひお楽しみに!