2026年2月5日、Anthropic社はClaudeの新たなフラッグシップモデル「Claude 4.6」をリリースしました。
新モデルの発表はベンチマークの成績など「性能向上版」ばかりフォーカスされがちですが、Claude 4.6の真価はそれだけではありません。
特にAIエージェントとして自律的に課題を解決する能力が大幅に向上しているとされており、エージェントチームを組んで複雑なタスクをこなすといった使い方ができるようになっています。
本記事では、Claude 4.6の性能や新機能について、旧モデルや競合モデルとの比較を交えて解説します。
Claude 4.6には複数の新機能が実装されていますが、最大の特徴と言えるのが、「Adaptive Thinking Mode」です。
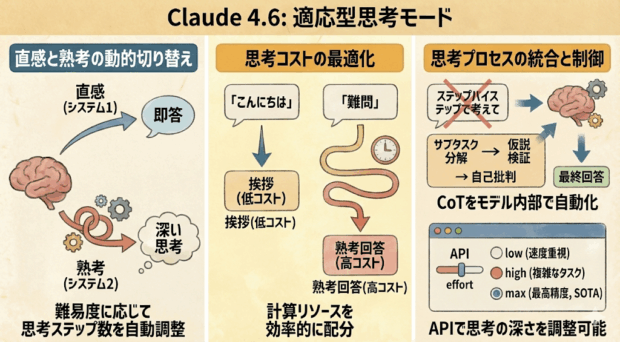
これは、人間が行っている認知プロセスの切り替えを模倣したモードで、「システム1(直感的・高速)」と「システム2(論理的・熟考)」を切り替えられるようになっています。
従来のLLM(Large Language Model)は、”こんにちは” という一言の挨拶に対しても、”フェルマーの最終定理の証明を分かりやすく説明して”という高度な思考が必要なプロンプトに対しても、トークン生成ごとにおおよそ一定の計算コストをかけていました。
これに対し、Claude 4.6のAdaptive Thinkingは、入力されたプロンプトの難易度を初期層で評価し、推論に必要な「思考ステップ数(Thinking Budget)」を動的に決定します。
つまり、先ほどの例に挙げた「こんにちは」のような定型的な挨拶に対しては計算せずに回答し、「フェルマーの最終定理の証明を分かりやすく説明して」のような深い思考を必要とするプロンプトに対してはしっかりと計算リソースを割いて熟考してから回答するようになったということです。
単にチャットで会話するだけのユーザー視点ではあまり実感が沸かない部分かもしれませんが、API利用ではコストに直結するためビジネス観点では大きな進歩と言えるでしょう。
ご存じの方も多いかもしれませんが、回答の精度を高めるテクニックとして、「ステップバイステップで考えて」という指示を含める「Chain of Thought(CoT)」という手法が知られていました。
これは、LLMに思考のプロセスを段階的に出力させることで、複雑な問題に対する推論能力を向上させるものです。
Claude 4.6では、このCoTプロセスがモデル内部に統合されています。つまり、ユーザーが明示的にCoTを指示しなくても、モデルは自発的に問題をサブタスクに分解し、仮説検証を行い、自己批判を経て最終回答を生成するのです
ユーザー視点では地味な変更ではありますが、性能を引き出すハードルが下がるのと、プロンプトの入力を省略できるのは嬉しいポイントです。
開発者向けの変更ですが、API利用で「思考の深さ」を制御するパラメータが追加されました。
速度重視でチャットボットやリアルタイム翻訳などに適した「low」から、複雑なコーディングや戦略立案などに適した「high」、通常の10倍以上のレイテンシが発生する可能性があるものの、SOTA(State-of-the-Art)の推論精度を提供する「max」が指定できます。
これにより、より細やかな使い分け、コントロールができるようになります。
AIとの対話において、コンテキストウィンドウの制限は大きな課題でした。コンテキストとは、AIが一度に処理できる情報の量のことです。
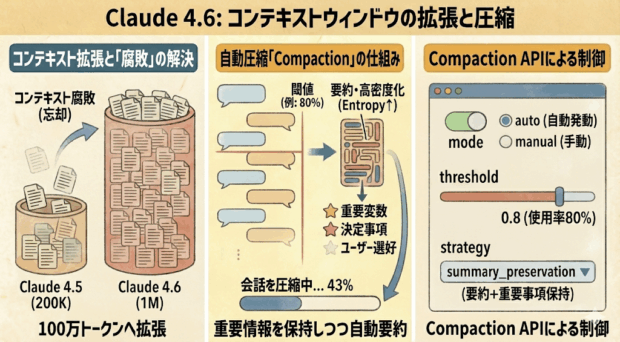
例えば、Claude 4.5のコンテキストウィンドウは200K(20万)トークンでした。
生成AIは一定のコンテキストを超えると、「コンテキスト腐敗(Context Rot)」と呼ばれる現象が発生し、過去の会話履歴や参照ドキュメントの重要な情報を忘れてしまいます。
この状態になると、ユーザーの意図通りの会話ができなくなるため、会話履歴をハンドオーバーして、新しいチャットに切り替える必要がありました。
Claude 4.6はこの問題を解決するために、1M(100万)トークンのコンテキストを提供すると同時に、「Compaction」を導入しました。
Compactionは日本語で「圧縮」という意味です。つまり、コンテキストを圧縮することで、より多くの情報を保持できるようにしたということです。
会話履歴が指定した閾値(例えばコンテキスト上限の80%)を超えた段階で、過去のやり取りを自動的に要約し、情報の密度(Entropy)を高めた状態でコンテキストに再注入する仕組みです。
単純なトランケーション(切り捨て)とは異なり、重要な変数の定義や決定事項、ユーザーの選好といったクリティカルな情報は保持され、「なんとなく話が通じなくなる」現象を防ぎます。
すべての情報が保持されるわけではない点に留意する必要がありますが、生成AI自身が過去の会話履歴の重要な部分が失われないように保持してくれるため、会話の継続が容易になります。
これはユーザー視点で一番嬉しい変更ではないでしょうか。
実際に大量のコンテキストを消費するようなチャットを試してみると、「チャットを続けられるように会話を圧縮しています。これには約1〜2分かかります。」のようなメッセージが表示されます。
CompactionはAPIレベルで提供されています。
modeは自動で発動するか、手動で発動するかを表す値で、autoを指定することで、自動で発動します。
threasholdはコンテキストの使用率を表す値で、0.8を指定することで、コンテキストの80%使用で発動します。
strategyは要約と重要事項の保持を表す値で、summary_preservationを指定することで、要約と重要事項の保持を表します。
この機能により、例えば「1週間継続してデバッグを行うBot」や「プロジェクトの全ミーティングログを記憶し続けるPMアシスタント」などが現実的なコストとパフォーマンスで実現可能になります。
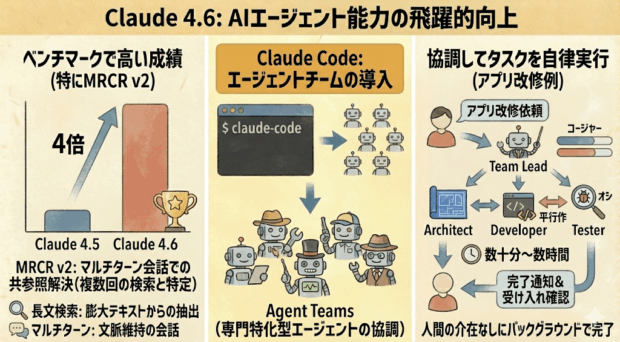
Claude 4.6は、AIエージェントのターミナル操作性能を評価する複数のベンチマーク指標で高い成績を叩き出しました。特に、MRCR v2では、前モデルの4倍のスコアを記録しました。
MRCR(Multi-Round Coreference Resolution)v2は、Google DeepMindが提案したタスクを基にOpenAIが公開した評価手法で、長い会話ログ内で類似した「needle」(検索対象の情報)を複数回繰り返し、最終的に「N番目のneedle」に関する正しい情報を特定する能力をテストします。
これは単なる文字列検索ではなく、マルチターン会話の共参照解決(co-reference resolution)を求め、干渉の多い長文(数十万〜100万トークン)でモデルの精度低下を定量的に測ります。
Claude 4.6のリリースに合わせて、CLIツール claude-code も大幅アップデートされています!
具体的には、新機能として「Agent Teams」が導入されました。
これは、1つのタスクに対して複数の専門特化型エージェント(Role-Based Agents)が立ち上がり、協調して作業を進めるものです。
たとえば、Claude CodeのAgent Teamsでアプリの機能を改修するように依頼すると、以下のような役割を持つエージェントチームが編成され、自律的にプロジェクトが進行します。
【アプリ改修タスクのエージェントチーム編成例】
これらのエージェント同士が役割に応じて連携し、人間の介在なしに、バックグラウンドで数十分〜数時間かけてタスクを完了させます。依頼者である人間は、完了の通知を受け取って、最終的な受け入れ確認を行うだけです。
Claude 4.6は思考モードの切り替えとコンテキストの圧縮、階層型チームなどAIエージェントとして複雑かつ長時間のタスクを実行できるように進化しています。
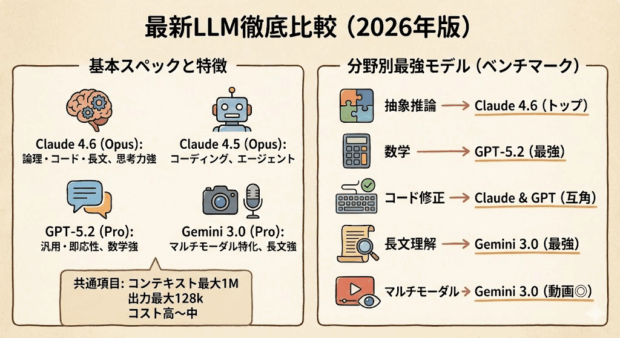
しかし、どのモデルを選ぶべきかは用途によって異なるというのが結論です。
競合モデルと比較すると、数学ではGPTが優秀ですし、長文理解やマルチモーダルではGeminiに軍配が上がります。
また、旧モデルと比較するとClaude 4.5の方が文章センスが高いという評価もあり、完全上位互換というわけではなく、使い分けが発生する関係だと言えます。(これはあくまで感覚的な話ですし、今後改善される可能性があります)
Claude 4.6の登場は、開発プロセスの自動化を一歩先に進めるインパクトがあります。
設計から実装、テスト、デプロイまでをAIが半自律的に行えるようになると、エンジニアの仕事は「コードを書くこと」から「AIエージェントチームをマネジメントすること(AI Director)」へと変化していくでしょう。
それどころか、エンジニアに限らず、多くの人が作業者からマネージャーに移行していくことになるかもしれません。
AIと共に働く世界を受け入れる準備として、Claude Codeでエージェントチームを組み、自分の仕事を教え込んで引き継げるか試してみるのはいかがでしょう。





