2017.10.25 Wed |
ImageNet large scale visual recognition challenge(ILSVRC)

今回は、大規模画像認識のコンテストである、ImageNet large scale visual recognition challenge(以後ILSVRC)というものをご紹介します。
このコンテストは、画像認識・画像分類の技術的進歩を定量的に測るためのものです。このコンテストができるまでは、PASCAL Visual Object Classes Challenge(2005~2012年)が、画像認識の技術的進歩を測ってきました。
ただ、PASCAL Visual Object Classes Challengeは、データセットが小規模(2012年で約1万件の画像)で、分類するカテゴリー数も少数(2012年で20クラス)あるという欠点がありました。これでは仮に精度が高くても、元々が容易な課題のため、現実世界で使うのに十分な画像認識(Computer Vision)の精度となってしまう恐れがありました。
たとえば、現実世界の物体の数は、そこらへんにあるものを数えていっても、ビル、車、人、家、空、犬、猫、駅、信号、電灯、、などとすぐに10を越えてしまいます。
たとえば、たとえば自動運転技術を考えた場合、目の前にあるものが、水たまりなのか、倒れている人なのかを認識できることが必要です。
現実世界で画像認識を行うためには、たとえば、分類のカテゴリー数は最低1000種類くらい必要です。1カテゴリーあたり、100枚の画像データを使用するとした場合、合計10万枚のタグ付き画像を学習する必要があります(例として猫画像には、猫というタグをつける)。
そこでImageNetというコンソーシアムにおいて、大量のデータセットを手作業でタグ付けし、ILSVRCというコンテストが行われるようになりました。
ここで少し、ILSVRCの歴史をたどってみます。
ILSVRCは2010年に
Alex Berg ( Columbia Unviversity ),
Jia Deng ( Princeton University ),
Fei-Fei Li ( Stanford Unviersity )
の三人をorganizerとして開始されました。
http://image-net.org/challenges/LSVRC/2010/
コンテスト内容は今のように3つではなく、1つで、
「Image classification annotations」だけでした。そして、コンテスト内容が増えたり内容が変わったりして、
2017年度は、
1,Object localization for 1000 categories.
(画像内で物体がどこにあるのかを推測する)
2,Object detection for 200 fully labeled categories.
(画像内で指定された200カテゴリーの物体を検出する)
3,Object detection from video for 30 fully labeled categories.
(動画内で指定された20カテゴリーの物体を検出する)
の3つのコンテストが開催されました。
詳細は、以下のILSVRC2017のwebsiteにあります(詳細知りたい方向け)。
 http://image-net.org/challenges/LSVRC/2017/
http://image-net.org/challenges/LSVRC/2017/
kaggle competitionにおいてもこのコンテスト(3種類)についてのページがあります。kaggle慣れしている人はこちらからコンテストに参加する方が参加しやすいようです。もう2017年のコンテストは終わっていますが。
ImageNet Object Localization Challenge
 https://www.kaggle.com/c/imagenet-object-localization-challenge
https://www.kaggle.com/c/imagenet-object-localization-challenge
ImageNet Object Detection Challenge
https://www.kaggle.com/c/imagenet-object-detection-challenge
ImageNet Object Detection from Video Challenge
https://www.kaggle.com/c/imagenet-object-detection-from-video-challenge
さて、それでは次に、ILSVRCで優勝してきたモデルについて、振り返ってみたいと思います。
ILSVRCは2010年から始まっていますが、DeepLearningのBreakthroughが起きた2012年の優勝モデルからご紹介します。
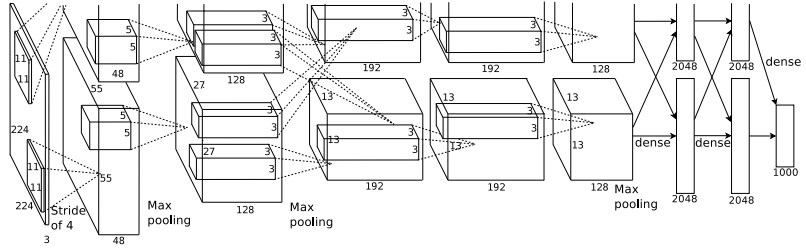
ILSVRC2012では、Tronto大学のAlex Krizhevsky、Ilya Sutskever、Geoffrey E. Hintonにより作成されたAlexNetが優勝しました。
 https://www.nvidia.cn/content/tesla/pdf/machine-learning/imagenet-classification-with-deep-convolutional-nn.pdf
https://www.nvidia.cn/content/tesla/pdf/machine-learning/imagenet-classification-with-deep-convolutional-nn.pdf
AlexNetは、5つの畳み込み層をもち、3つの全結合層を持ちます。
AlexNetのパラメータ数は、約6000万個あります。重回帰だと高々数十個のパラメータしか持たないことと比べるとすごいパラメータ数ですね。
AlexNetでは、DropoutやDataAugmentationなど、局所解に陥らない方法がいくつか用いられています。現在も様々なNeural Networkで多用されている活性化関数であるReLuが使用されたのもAlexNetです。
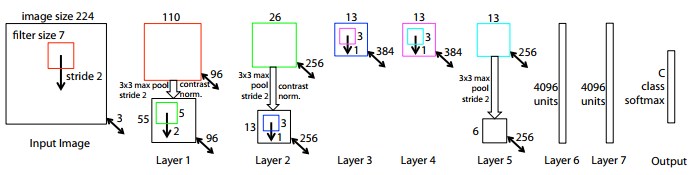
ILSVRC2013では、NewYork大学のMatthew D. Zeiler、 Rob Fergusのチームが優勝しました。
使用されたモデルはZFNetというものです。基本的にAlexNetと同じネットワークです。
 https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
AlexNetとZFNetは、畳み込み層が5層、全結合層が3層というところまでは同じです。
モデルの構造で少し違うのは、
1つ目の畳み込み層でカーネルサイズを、11×11にしているのを、7×7に変更し、stride数が4だったものを2にしたところと、
3,4,5つ目の畳み込み層でカーネル数を、384、384、256だったものを、512、1024、512に変更したところです。
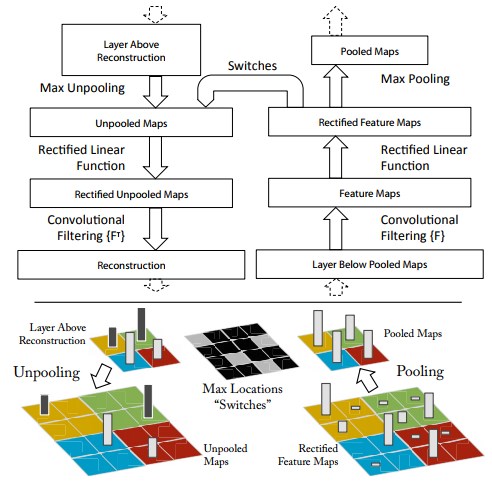
大きく違うのは、各層の重みを可視化する、Deconvolutional Networkを用いて、パラメータ調節のヒントを得たことです。
下図の左にあるのがdeconvolutional networkで、
右にあるのが、convolutional networkです。
 https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
deconvolutional networkを用いた、学習モデルの特徴量は下の灰色のものになります。カラー写真は、学習時に使用した写真です。
 https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
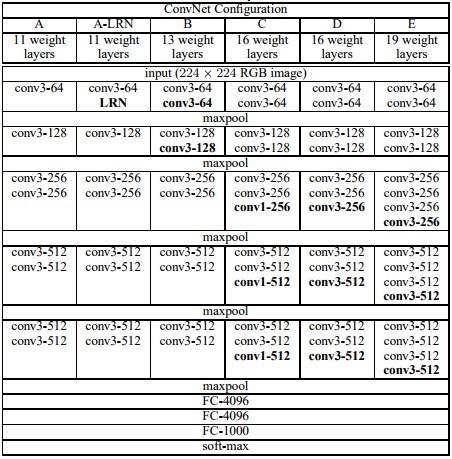
ILSVRC2014で優勝したモデルに行く前に、ILSVRC2014で準優勝したモデルについてご紹介します。VGGNetといって、Oxford大学のKaren SimonyanとAndrew Zissermanにより作成されました。
VGGNetは、AlexNet(8層)よりさらに深い構造(19層)であり、パラメータの数は約1億4千個あります。下の図には、Model AからEまでが試されていますが、Model Eが最も精度が良かったようです。
 https://arxiv.org/pdf/1409.1556.pdf
https://arxiv.org/pdf/1409.1556.pdf
ここで考案されたVGGNetは、現在でもいろいろな分野で使用されています。たとえば、semantic segmantation(画像内の物体のクラスの推定と、その輪郭の推定を行うもの)を行う、SegNetはVGG16を使用しています。
さて、次にILSVRC2014で優勝したモデル、GoogLeNetをご紹介します。GoogleNet(22層)は、VGGNet(19層)と同様に層を深くすることで精度を上げること可能にしたモデルです。
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/43022.pdf
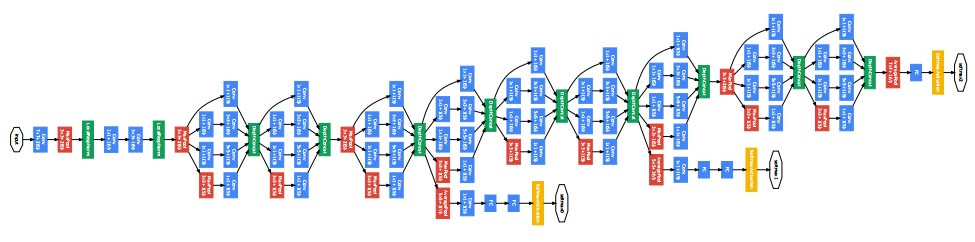 https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/43022.pdf
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/43022.pdf
一見かなり複雑なモデルですね。
実は見かけほど複雑ではありません。まずモデルで多用されている、inceptionモジュールについてご説明します。
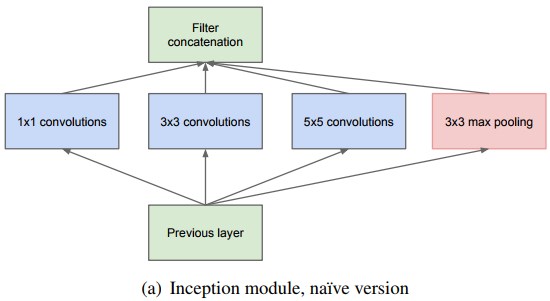
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/43022.pdf
これが、一番初めに提唱された、Inception moduleです。さまざまなカーネルサイズ(1×1,3×3,5×5)で畳み込みして(maxpoolingで位置ずれも考慮している)その結果を積み重ねて次の層に渡すため、より多様な特徴量取得が期待できます。ただ、入力情報の深さの次元が大きいため、計算コストが高くつくデメリットがありました。そのデメリットを解消したInception moduleが以下です。
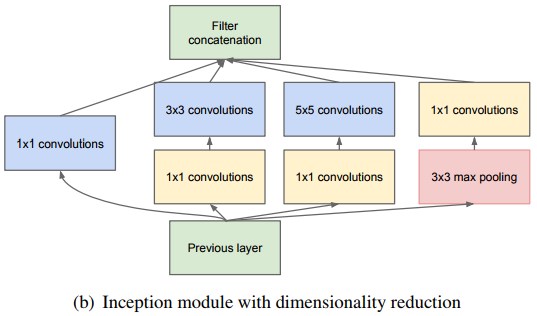
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/43022.pdf
3×3 convolutionと5×5 convolutionの前に、1×1 convolutionが追加されているのがわかると思います。これは、カーネルサイズは1×1なんですが、このカーネルには入力データと同じだけの深さがあり、カーネルを掛けた結果として、深さが1となり、そのあとに続く3×3 convolutionと5×5 convolutionの計算コストが劇的に低下します。つまり、1×1 convolutionには次元削減の効果があります。3×3 max poolingのあとの1×1 convolutionも同じ次元削減の意味合いです。ただ、max poolingの性質上、max poolingの後に1×1 convolutionがあります。ちなみに、Inception module内では、strideの数を同一にします。出力サイズ(output size)をそろえるためです。
またモデルをよく見ると出力が3つあります。
青で囲ったところがメインで、赤で囲った二つの部位でも損失関数を計算し、誤差逆伝播を行うことで、勾配消失を防ぐことに成功しています。
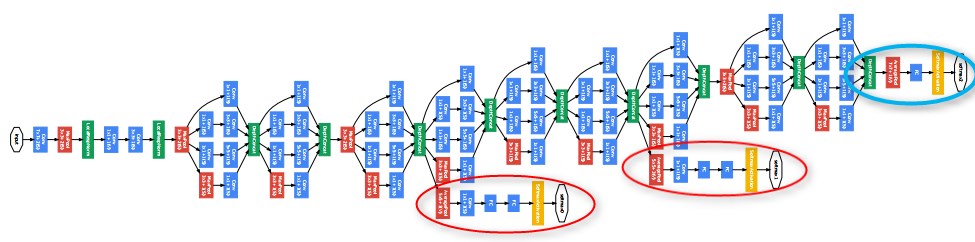
https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/43022.pdf
青い丸で囲ったところを見ていただくとわかりますが、全結合層は1層しかありません。このことが、モデル全体のパラメータ数を減らすことに貢献しています。また出力の前のPoolingとして、MaxPoolingでなく、AveragePoolingを行っていることも特徴の一つです。
ILSVRC2015で優勝したモデルは、ResNetです。このモデルは、152層あり、層を深化させることに関して、Breakthroghを引き起こしました。精度もさらに劇的に向上しました。ResNetは、MicrosoftResearchAsia(MSRA)のKaiming He,Xiangyu Zhang,Shaoqing Ren,Jian Sunにより開発されました。
ResNetは、以下のような「入力と出力を接続する経路を持つ誤差ユニット」を積み上げて作成されました(右の迂回路をidentity mappingと呼びます)。
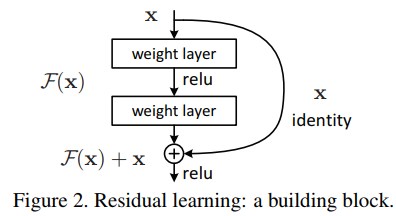
https://arxiv.org/pdf/1512.03385.pdf
ResNetは以下のような構造を持ちます。一番右の152-layerが最も精度が高いものです。
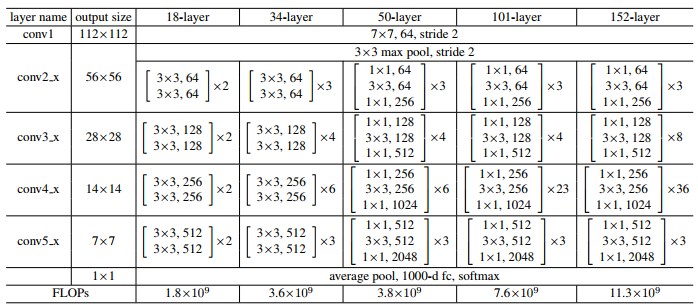 https://arxiv.org/pdf/1512.03385.pdf
https://arxiv.org/pdf/1512.03385.pdf
今までは、構造を深くすると、勾配が消失・発散してしまい、下層のパラメータの学習が進まなくなる問題がありました。ResNetは152層の構造をもっており、これは、VGG19の8倍の深さです。
ダウンサンプリングをするときに、MaxPoolingを使用するのではなく、畳み込み時のstrideを2にしていることも特徴の一つです。
また、過学習を抑制するためのDropoutも使用していないところも新規です。
全結合層がなく、MaxPoolingも一つしかなく、出力の時は、Average Poolingから直で1000個のneuronにoutputしているため、パラメータ数が少なく、パラメータ数はVGG19の18%に抑えられています。
ResNetでもっとも重要な誤差ユニットの特徴として以下のようなものがあります。
・追加のパラメータが必要ない。
・計算の複雑性も増えない。
・誤差逆伝播法で最適化可能。
ResNetは、現在では、画像認識のGold Standardとなり、有名どころだと、Inception moduleとResNetを組み合わせた、Inception-ResNetがあります。

https://arxiv.org/pdf/1602.07261.pdf
ちなみに、ResNet-Inceptionの基本moduleは以下です。
中心にidentity mapping、右側にinception moduleがあるのがわかるかなと思います。
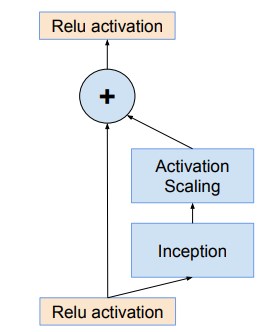
https://arxiv.org/pdf/1602.07261.pdf
ということで、今回は、ILSVRCのご紹介と、ILSVRCの過去の優勝チームのモデル紹介を行いました。
今回はここまで。
鈴木瑞人
東京大学大学院新領域創成科学研究科 メディカル情報生命専攻 博士課程
NPO法人Bizjapan テクノロジー部門BizXチームリーダー