2018.01.17 Wed |
テキスト解析入門その2(形態素解析・集計・可視化)

前回に引き続きテキストデータ解析を行っていきたいと思います。
今回は、日本語テキストを処理していきたいと思います。
R言語での日本語処理には、形態素解析ツールのMeCabとRMeCabパッケージが必要です。
MeCabのダウンロード・インストールに関してですが、
【Windowsの方】
以下URLに飛んだあと、
http://taku910.github.io/mecab/
ダウンロード→MeCab 本体→Binary package for MS-Windows→mecab-0.996.exe:ダウンロードの”ダウンロード”をクリックして、あとは普通にインストールしてください(文字コードはShift-JIS)。
【Macの方】(以下ダブルクオテーションを半角に変えて使ってください(WordPressの仕様で全角になっいるため))
xcode入っていない方は、xcodeをインストールしていただき、
ターミナルに以下のコマンドを入力
xcode-select –install
homebrewが入っていない方は、以下コマンドをターミナルに入力してhomebrewをいれ、
/usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
その次に、
brew install wget
と入力。
その後以下コマンドを、一行ずつ入力してください。
cd /tmp
wget -O mecab-0.996.tar.gz “https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE”
tar xzf mecab-0.996.tar.gz
cd mecab-0.996
./configure
make
sudo make install
cd ..
wget -O mecab-ipadic-2.7.0-20070801.tar.gz “https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM”
tar xzf mecab-ipadic-2.7.0-20070801.tar.gz
cd mecab-ipadic-2.7.0-20070801
./configure –with-charset=utf8
make
sudo make install
cd ..
rm -rf /tmp/mecab-*
ダウンロード・インストールが終わったら、
以下のコマンドで、RMeCabパッケージをダウンロード・インストールしてください。
install.packages(“RMeCab”,repos=”http://rmecab.jp/R”)
さて環境の準備は終わりました。
今回は、青空文庫にある、吉田茂の「私は隠居ではない」を例として解析していきたいと思います。
http://www.aozora.gr.jp/cards/001924/card58230.html#download
これから、RMeCabパッケージを使用していきますが、このパッケージで重要な関数は以下のものです。
RMeCabC() :文字列を形態素解析する。
RMeCabText():ファイルデータを読み込み、形態素解析の結果をリストとして返す。
RMeCabDF():データフレームから、単語の頻度表を作成。
RMeCabFreq():ファイルデータを読み込み、単語の頻度表を作成。
docMatrix(),docMatrix2():フォルダ語と読み込み、単語文書行列を作成。
docMatrixDF():データフレームを読み込み、単語文書行列を作成。
collocate():ファイルデータ読み込み、共起の頻度表を作成。
collScores():共起頻度オブジェクトを受け取り、共起スコアを算出。
Ngram():データファイルを読み込み、Nグラムの頻度表を作成。
NgramDF()、NgramDF2():データファイルを読み込み、Nグラムを独立した列とした頻度表を作成。
docNgram()、docNgram2():フォルダを読み込み、Nグラム情報の行列を作成。
docDF():データフレーム、ファイル、フォルダのいずれかを受け取り、形態素あるいは、文字の頻度表を作成。
いろいろありますが、いくつか試していきたいと思います。
まず、パッケージをロードします。
library(RMeCab)
RMeCabC()関数から試してみましょう。
x = RMeCabC(“明日は雨が降るでしょう。”)
x
 リストで返されると、縦で見にくいのでベクトルに変換しましょう。
リストで返されると、縦で見にくいのでベクトルに変換しましょう。
unlist(x)
 これで、見やすくなりました。
これで、見やすくなりました。
RMeCabC()関数は、大雑把な品詞情報だけつけて返してくれるところがポイントです。
それでは次に、RMeCabText()関数を使ってみましょう。
この関数はファイルを読みこませる必要があります。
先ほどの、吉田茂の「私は隠居ではない」のデータファイルがあるところまで移動しましょう。(Rコンソールの左上の「ファイル」のところに「ディレクトリの移動」があります)
ここで、テキストファイル中の本文以外の情報は削除してしまいます。
それでは、読みこんでいきます。
x = RMeCabText(“watashiwa_inkyodewa_nai.txt”)
#結果の頭出し
head(x)
 先ほどは、単語の大雑把な品詞しか取り出せていませんでしたが、今回は、さらに細かい品詞と各単語の原型候補も取り出せているのが分かるかと思います。
先ほどは、単語の大雑把な品詞しか取り出せていませんでしたが、今回は、さらに細かい品詞と各単語の原型候補も取り出せているのが分かるかと思います。
もしここでこのリストの各成分の第一成分を取りだしたいとしましょう。purrrパッケージとmagrittrパッケージが必要になります。
library(purrr)
library(magrittr)
#もしまだ入っていなければ以下を実行
install.packages(“purrr”,dependencies=T)
install.packages(“magrittr”,dependencies=T)
#以下ではpurrrパッケージのmap_chr関数と
#magrittrパッケージのextract関数を使用しています。
x2 = map_chr(x,extract(1))
結果の頭出し
head(x2, n=30)
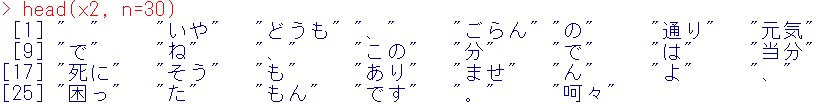 ここから単語の数を集計してもいいのですが、他にdocDFという便利な関数があるのでそちらを使います。
ここから単語の数を集計してもいいのですが、他にdocDFという便利な関数があるのでそちらを使います。
引数として、typeがあり、デフォルトだとtype=0で形態素解析は行わず、1-gramを行ってしまうので、今回は、type = 1として、形態素解析を実行させます。すると各単語の頻度を集計して返してくれます。
x = docDF(“watashiwa_inkyodewa_nai.txt”,type = 1)
頭出しを見てみましょう。
head(x, n = 20)
 4列目が頻度となっています。
4列目が頻度となっています。
4列目の名前をFreqに変更しましょう。
colnames(x) = c(“TERM”,”POS1″,”POS2″,”Freq”)
結果確認
head(x)
 POS1列が記号のものと、POS2列が数のものを消去する。
POS1列が記号のものと、POS2列が数のものを消去する。
まず、dplyrパッケージをロードする。
library(dplyr)
x1 = filter(x,POS1 != “記号”)
x2 = filter(x1,POS2 != “数”)
結果確認
head(x2,n=20)
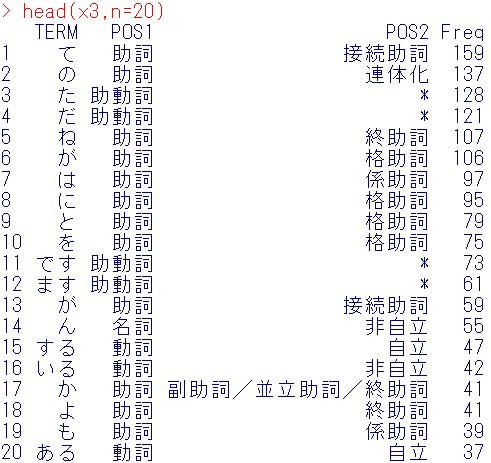
 次に、Freq列が多い順に並び替える
次に、Freq列が多い順に並び替える
x3 = arrange(x2,desc(Freq))
結果確認
head(x3,n=20)
x4 = filter(x3,!POS1 %in% c(“助詞”,”助動詞”))
結果の頭出し
head(x4,n=20)
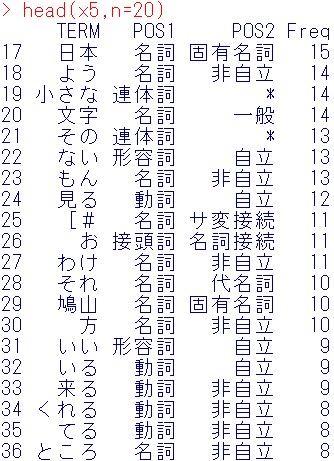
 1行目から、16行目は、この文章の特徴をあらわす単語としては、不適切(どの文章にも出てくる)ので、消去します。
1行目から、16行目は、この文章の特徴をあらわす単語としては、不適切(どの文章にも出てくる)ので、消去します。
x5 = x4[-c(1:16),]
結果の頭出し
head(x5,n=20)
 可視化パッケージのロード
可視化パッケージのロード
library(formattable)
もし入っていなければ以下を実行
install.packages(“formattable”,dependencies=T)
formattable関数による可視化
formattable(x5, list(Freq= color_bar(“lightblue”), align = “l”))
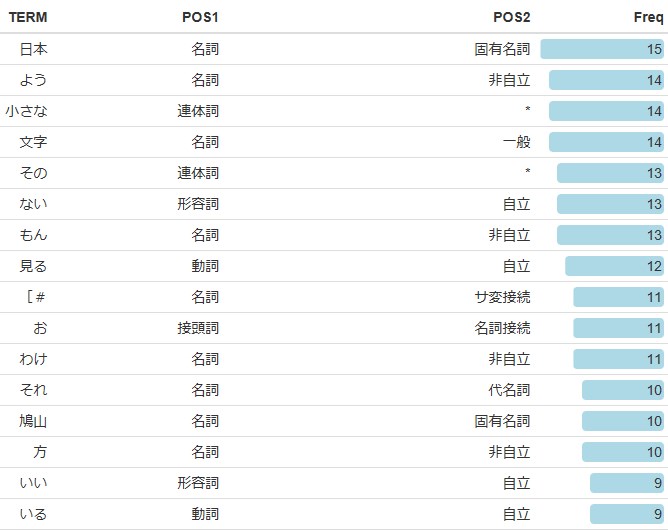 これで可視化した感じだと、今回は、名詞と形容詞以外は、必要ないと感じたので、名詞と形容詞以外を消去します。
これで可視化した感じだと、今回は、名詞と形容詞以外は、必要ないと感じたので、名詞と形容詞以外を消去します。
x6 = filter(x5,POS1 %in% c(“名詞”,”形容詞”))
結果の頭出しをしてみます。
head(x6,n=20)
 次に名詞の非自立を消去します。
次に名詞の非自立を消去します。
x7 = filter(x6,!(POS1 == “名詞”& POS2 == “非自立”))
結果の頭出し
head(x7, n=20)
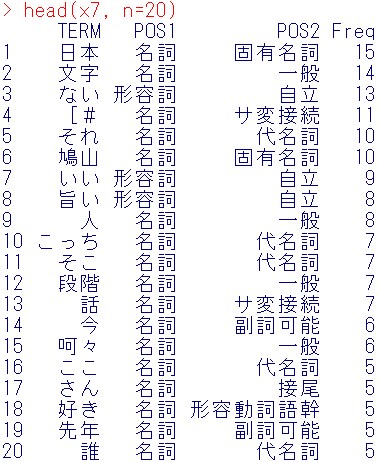 次に名詞のサ変接続を消去して、wordcloudを作ってみましょう。
次に名詞のサ変接続を消去して、wordcloudを作ってみましょう。
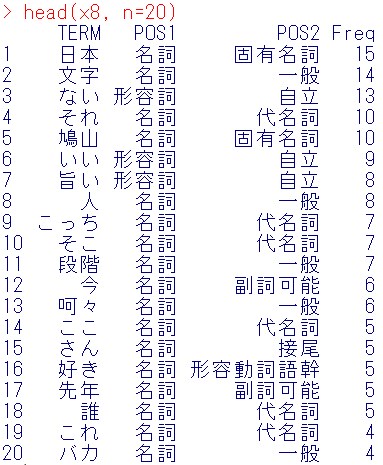
x8 = filter(x7,!(POS1 == “名詞”& POS2 == “サ変接続”))
結果の頭出し
head(x8, n=20)
 wordcloudパッケージのロード
wordcloudパッケージのロード
install.packages(“wordcloud”,dependencies=T)
library(wordcloud)
wordcloud(x8$TERM, x8$Freq, min.freq=4, scale=c(10,1), colors=rainbow(10))
 頻度が小さな文字が表示されなかったので、表示されるようにしましょう。
頻度が小さな文字が表示されなかったので、表示されるようにしましょう。
wordcloud(x8$TERM, x8$Freq, min.freq=4, scale=c(6,1), colors=rainbow(10))
 日本、日本人、陛下といった国に関する単語や、鳩山、吉田といった政治家の名前が抽出されているのが分かるかと思います。
日本、日本人、陛下といった国に関する単語や、鳩山、吉田といった政治家の名前が抽出されているのが分かるかと思います。
また、果物、旨い、という単語があることから、食に関する記述があることが想像できます。
実際の今回の文章は内容は多岐にわたっており、数回しか出現していなくても重要な役割をしている単語は存在し、単語の頻度を集計することで必ずしも文章の特徴がすべて抽出できるわけではありませんが、古典的な方法として、形態素解析→単語の集計→可視化、というフローがあることはぜひ覚えておいてください。
今回はここまで。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻博士課程
実践的機械学習勉強会 代表
株式会社パッパーレ 代表取締役社長
NPO法人Bizjapan テクノロジー部門BizXチームリーダー