2018.01.19 Fri |
テキスト解析入門その6(Tweet情報取得と用例索引と共起語の分析)

今まで、5回にわたってテキストマイニングを行ってきましたが、今回もその続編です。
今までの記事をまだ見ていない方はぜひご覧ください。
テキスト解析入門その1
http://ritsuan.com/blog/8035/
テキスト解析入門その2
http://ritsuan.com/blog/8138/
テキスト解析入門その3
http://ritsuan.com/blog/8164/
テキスト解析入門その4
http://ritsuan.com/blog/8178/
テキスト解析入門その5
http://ritsuan.com/blog/8195/
今回は、TwitterAPIを使用して、用例索引を行ってみたいなと思います。
TwitterAPIを使用するためには、
1,Twitterアカウントを作成する(すでに持っていれば作成不要)。
2,Twitterアカウントに電話番号を登録する。
3,TwitterDevelopersでの設定を行う。
の3つのステップが必要になります。
まず、1のTwitterアカウントの取得ですが以下のリンクから行ってください。
https://twitter.com/signup?lang=ja
次に、2の電話番号登録ですが、以下のリンクを参照して行ってください。
https://help.twitter.com/ja/managing-your-account/how-to-add-a-phone-number-to-your-account
最後に、3のTwitterDevelopersでの設定ですが、
まず、下記リンクのTwitter Developers Documentationに移動して、一番下までスクロールして、Manage my appsを選択してください。
https://dev.twitter.com/web/sign-in
次に、Create New Appを選択。
Name,Description,Websiteに適当な記述をいれて、Developer Agreementにチェックマークを付けます。そのチェックマークの下にある、Create your Twitter applicationのボタンをクリックしてください。
Keys and Access Tokensのタブを選択。
そこに、
この部分に、
Consumer Key (API Key)
Consumer Secret (API Secret)
があるのでメモしておいてください。
さらに下にスクロールすると、create my access tokenがあるのでそれをクリックしてください。
そこで、
Access Tokenと
Access Token Secret
の内容をメモしてください。
以上でTwitterAPIを使う準備は整いました。
次に、Rコンソールを開いていただき、パッケージのロードを行います。
install.packages(“twitteR”,dependencies=T)
library(twitteR)
先ほど取得した情報を使用して変数を作成します。
consumerKey = “ここにConsumerKeyをいれる”
consumerSecret = “ここにConsumerSecretをいれる”
accessToken = “ここにAccessTokenをいれる”
accessSecret = “ここにAccessSecretをいれる”
たとえば、イメージですが以下のように入力することになります。
consumerKey = “MRAEWapCkaOWEbymlhE”
consumerSecret = “aXPCuPKEtly34IEIfBOPya6djxpNhYx8SEi5Dy9dQ”
accessToken = “1403149378-2hUkCXxoXcj2ER9EIFI8FDwoQXFZU7imOYQ”
accessSecret = “SwjV6WsiKB3EIWGRFTXMSGDERTzOvWvAyj5″
そして、TwitterAPIにアクセスするための認証を行います。
options(httr_oauth_cache=T)
setup_twitter_oauth(consumerKey,consumerSecret,accessToken,accessSecret)
次にTweetの取得を行いたいと思います。
キーワード「自然言語処理」として、「自然言語処理」とつぶやいているTweetを取得してみましょう。
まずキーワードを指定します。
keyword=”自然言語処理”
次にWindowsの方のみ文字コードをSHIFT-JISからUTF-8へ変更します。
keyword=iconv(keyword, to=”UTF-8″)
searchTwitter関数でTweetを取得し、
結果を、twListToDF関数でデータフレームへ変換します。
result = twListToDF(searchTwitter(keyword,n=100))
取得した、Tweet情報を見てみましょう。
head(result$text)

このTweet情報を用例索引で可視化したいと思います。
まず前処理用のパッケージをロードします。
library(stringr)
Tweet内容だけ抽出します。
text = result$text
半角文字を除去します。
text = str_replace_all(text,”\\p{ASCII}”,””)
結果の頭出し
head(text)
 次にから要素を削除します
次にから要素を削除します
text = text[text != “”]
以下で、Windowsの人だけ文字コード変換してください。
text = iconv(text,from = “UTF-8”,to = “CP932”)
文字列をすべて結合します。
text = paste(text, collapse = “”)
データをテキストデータとして保存します。
write(text,”tweet-text.txt”)
これで、tweet-text.txt というファイルがワークディレクトリに保存されたはずです。
次にファイルを読み込んで形態素解析を行いたいので、RMeCabパッケージをロードしましょう。
library(RMeCab)
日本語テキストの読み込みと形態素解析を行います。
result = RMeCabText(“tweet-text.txt”)
結果の頭出し
head(result)
 次に今の結果の各成分の第一成分を抽出するために、purrrパッケージとmagrittrパッケージをロードします。
次に今の結果の各成分の第一成分を抽出するために、purrrパッケージとmagrittrパッケージをロードします。
library(purrr)
library(magrittr)
形態素解析された結果の、各単語要素のみ抽出します。
result2 = map_chr(result,extract(1))
結果の頭出し
head(result2,n=30)

dataという変数に結果を格納します。
data = result2
今回は、「自然」の前後の単語を列挙することにします。
word_position = which(data == “自然”)
「自然」の前後6単語まで表示させるとしましょう。
k = 6
n = length(word_position)
d = data.frame(before = rep(0,n),keyword = rep(0,n),after = rep(0,n))
for(i in 1:length(word_position)){
a = word_position[i]
b = max(a-k,1)
e =min(a+k,length(data))
f = min(a+1,length(data))
d[i,1] =paste(data[seq(b,(a-1))], collapse = “”)
d[i,2] = paste(data[a], collapse = “”)
d[i,3] = paste(data[seq(f,e)], collapse = “”)
}
head(d, n = 15)
 これをcsvで保存しましょう。
これをcsvで保存しましょう。
write.csv(d,”new-tweet.csv”,row.names=F)
そして、Google Spread Sheetで開いてみます。
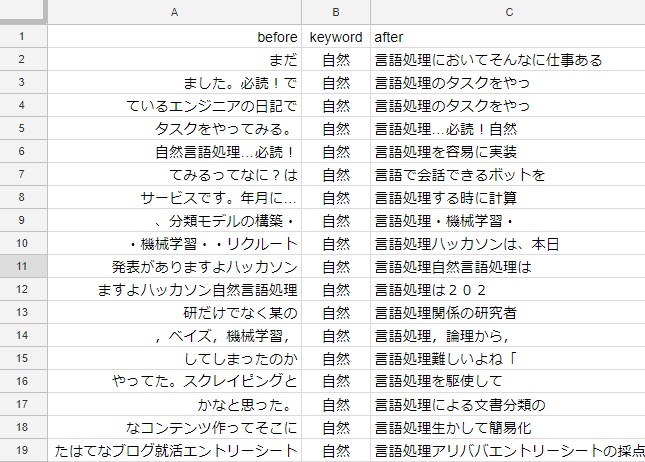
これを眺めていくと、「自然言語処理」という単語がどのような文脈で使われているかわかりますね。今回は。前後6単語を表示させましたが、10くらい表示させてもよかったですね。
データサイズが大きな場合は、これに共起語解析を組み合わせて使うとよいでしょう。
軽く共起語解析を行ってみます。
中心語は「自然」、前後いくつの単語まで見るかに関して前後それぞれ7個を選択しています。
result = collocate(“tweet-text.txt”, node = “自然”, span = 7)
集計結果の確認
head(result, n = 10)

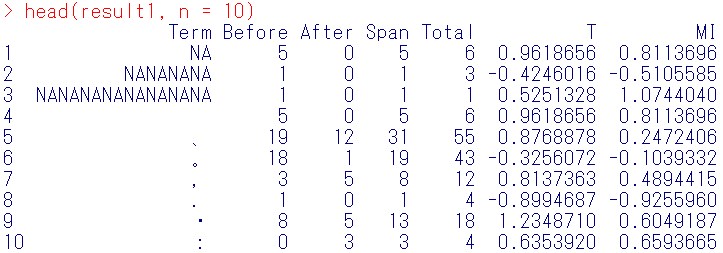
この結果の見方ですが、
Term:共起語
Before:中心語の前の5個単語の中に共起語が何回現れるかを表したもの。
After:中心語の後の5個単語の中に共起語が何回現れるかを表したもの。
Span:中心語の前5単語と後5単語の中に合計いくつ共起語が現れたかどうか(Before+After)
Total:文書中で何回その共起語が現れたか。
となっています。
ただ、collocate関数では、
共起強度の指標(T score(T), Mutual Information(MT))は、算出されません。これらを算出したい場合は、collocate関数の結果に対して、
collScores関数を適用します。
result1 = collScores(result, node = “自然”, span = 7)
集計結果の確認
head(result1, n = 10)
 T値が大きい共起語を抽出して可視化してみましょう。
T値が大きい共起語を抽出して可視化してみましょう。
library(dplyr)
T値が大きい順に共起語を並び替え
result2 = arrange(result1,desc(T))
結果の頭出し
head(result2, n = 20)
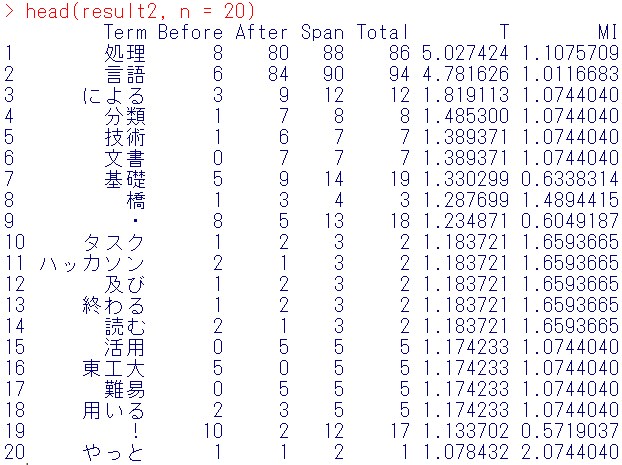
T値は純粋に中心語と多く共起する共起語を知りたい時に参照する指標でした。
今回は、分類・技術・文書・基礎・橋などがT値が大きいですね。
“tweet-text.txt”を開きながらファイル内検索(Windowsでは、Ctrl+F)それぞれ、どのように使われているか見てみると、
分類は、「分類モデルの構築」「文書分類」
技術は、「言語処理の基礎技術」「言語処理技術を活用」
文書は、「文書分類」
基礎は、「基礎、トピックモデルを学ぶ」「基礎研究」
橋は、「黒橋教授」
という使われ方をしており、個人的には、
放送大学テキスト「自然言語処理(著:黒橋教授)」という教科書が話題になっており、今後の自然言語の勉強の参考になりました。
この本はAmazonにおいて、「放送大学テキスト」というカテゴリで、ベストセラー1位になっているみたいですね。
出現がまれでも重要な共起語の抽出を行う、MI値も求めておきます。
MI値が大きい順に共起語を並び替え
result3 = arrange(result1,desc(MI))
結果の頭出し
head(result3, n = 20)
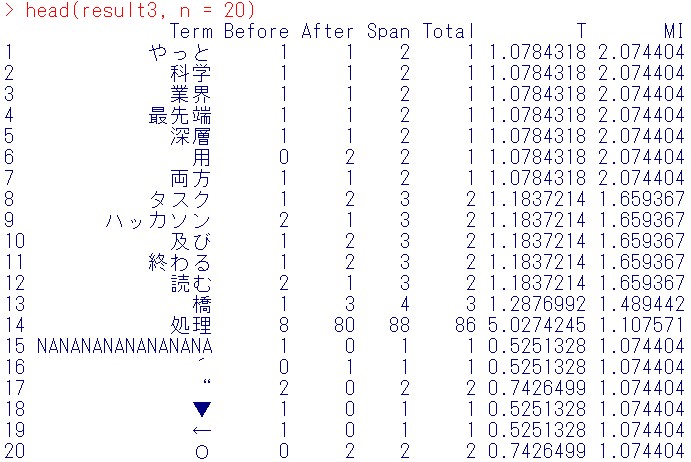 ここでは、科学、業界、最先端、深層、ハッカソンという単語がでてきます。
ここでは、科学、業界、最先端、深層、ハッカソンという単語がでてきます。
それぞれの使われ方は、
科学は、「言語学と自然科学系」
業界は、「特許公報を用いた自然言語処理による業界分析」
最先端は、「自然言語処理と深層学習の最先端自然言語処理。言語処理のための機械学習入門自然言語処理シリーズ高村大也」
深層は、「自然言語処理と深層学習の最先端自然言語処理」
ハッカソンは、「リクルート自然言語処理ハッカソン」
と出てきました。
MI値は、まれでも重要な共起語の抽出を行いますが、今回は個人的には、評判分析で使用する辞書の作成者である高村先生の著書「言語処理のための機械学習入門自然言語処理シリーズ」が出てきたことが参考になりました。本の存在自体は知っていたのですが、高村先生の著作だったとは少し驚きです。ぜひ後ほど読みたいです。
「リクルート自然言語処理ハッカソン」も抽出されましたが、今がちょうど成果発表会みたいですね。
Twitterから得られる情報で何でもできるわけではないんですが、タイムリーな口コミを収集できることは示せたかなと思います。
今回はここまで。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻博士課程
実践的機械学習勉強会 代表
株式会社パッパーレ 代表取締役社長
NPO法人Bizjapan テクノロジー部門BizXチームリーダー