2018.02.10 Sat |
POSデータ解析1(来店回数と顧客属性からの来店予測)

みなさん、POSデータというものをご存じでしょうか?
POSデータとは、Point Of Salesの頭文字をとった、基本的に小売店での顧客の購買データのことを言います。さらに詳しく言えば、顧客がいつ・どこで・何を・いくつ買ったかというデータですね。
以前よりPOSデータは、さまざまな小売店で取得・解析され、在庫数の最適化や、商品のリコメンデーション、小売店での商品の配置最適化、顧客の来店予測などに使用されてきました。
今回は、顧客の来店予測を行ってみたいと思います。
使用するPOSデータについてですが、
上級のデータサイエンティストであればほとんどの人が読んだことのある書籍、
データ分析プロセス(金 明哲編・福島 真太朗著)
http://www.kyoritsu-pub.co.jp/bookdetail/9784320123656
に付属しているデータセットを使用してみます。この書籍は、Python言語でなくR言語を勉強することのメリットとしても過言ではない本です。この本の内容をカバーしているPythonの書籍は、2018年2月現在存在しないと認識しています。ぜひ購入しましょう!
データのダウンロード方法ですが、上記リンク先へ移動後、
「本書掲載のプログラムおよびダウンロードして利用するデータ」をクリックすると、ダウンロードが始まります。ダウンロードしたフォルダを解凍後、DataProcess.20151001の中のsrcフォルダの中の、dataフォルダの中の、Tafengフォルダの中の、圧縮ファイルTafengを解凍してください。その中のTafeng_datasetフォルダの中にあるTafeng.csvが目的のファイルです。
著作権に関してですが、
以下よく読んでください。
Copyright (c) 2004, Chun-Nan Hsu, All rights reserved.
1. Redistributions must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
2. Neither the names of the copyright holders nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
3. Publications based on this data set must cite this article: DOI: 10.1023/B:MACH.0000035471.28235.6d
http://link.springer.com/article/10.1023/B%3AMACH.0000035471.28235.6d
データセットの配布形式とライセンスについて以下よく読んでください。
This Tafeng dataset is distributed under the BSD Licence.
The distributed files are as follows:
1. orig/{D11, D12, D01, D02} Original Tafeng dataset.
Each file contains the POS data in 11/2000, 12/2000, 1/2001, 2/2001, respectively.
2. Tafeng.csv This file is made by combining these four files.
それぞれ、目的のファイルである、Tafeng.csvと同じフォルダにある、README.txtとLICENSE.txtの内容を張り付けたものになります。
それでは、解析を始めていきましょう。
まずは、データの読みこみから行います。
readrパッケージを使うのでロードします。
install.packages(“readr”, dependencies = T)
library(readr)
データセットがあるディレクトリに変更して、データを読み込みます。
d = read_csv(“Tafeng.csv”)
読みこんだ結果を見てみます。
d
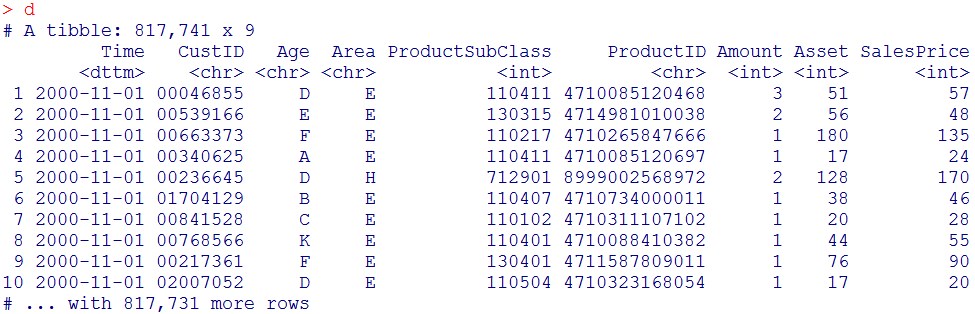 今回使うのは、
今回使うのは、
Time列:いつ商品を買ったか、
CustID:顧客ID、
Age:顧客の年齢(層別化されて各カテゴリーにはランダムなアルファベットが割り当てられています)
Area:顧客の居住地
の4変数になります。
まず、顧客の属性情報を抽出します。
初めに必要なパッケージをロードします。
library(dplyr)
#パッケージが入っていなければ以下一行実行
install.packages(“dplyr”, dependencies = T)
customer = d %>% select(CustID, Age, Area) %>% unique()
customer
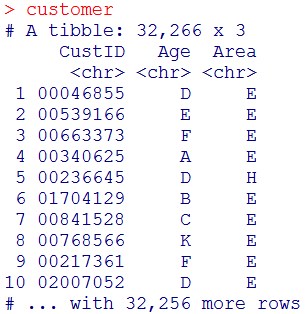 これで、顧客の属性データベースが作成できました。
これで、顧客の属性データベースが作成できました。
次は、来店履歴情報を作ります。
まずは、dから、Time列とCustID列を抽出します。
visit = d %>% select(Time, CustID)
visit
 ここで、これから使う、year列、month列、day列を作成します。
ここで、これから使う、year列、month列、day列を作成します。
時系列変数を扱うので、lubridateパッケージをロードします。
library(lubridate)
#パッケージが入っていなければ以下一行実行
install.packages(“lubridate”, dependencies = T)
visit1 = visit %>% mutate(Year = year(Time), Month = month(Time), Day = day(Time))
visit1
 これを、CustID列、Year列、Month列に関して、グループ化して、各グループにおいて、日付の重複を取り除いた後に、何個ユニークな日付があるかを数えます。
これを、CustID列、Year列、Month列に関して、グループ化して、各グループにおいて、日付の重複を取り除いた後に、何個ユニークな日付があるかを数えます。
visit2 = visit1 %>%
group_by(CustID, Year, Month) %>%
summarise(Freq=length(unique(Time)))
visit2
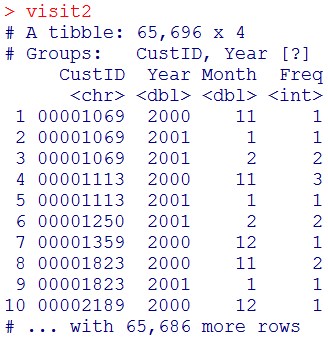
これで、顧客が、何年の何月に何回スーパーを訪れたかがわかりました。
これをできたら、各行が各顧客、各列が各月に顧客がスーパーを訪れた回数という風にしていきます。
そのために、まず、新しい列ymを作成します(あとでこの意味がわかります)。
その前に、今回使用するパッケージをロードします。
library(stringr)
#パッケージが入っていなければ以下一行実行
install.packages(“stringr”, dependencies = T)
visit3 = visit2 %>% mutate(ym = str_c(“x”,Year,”_”,Month))
visit3
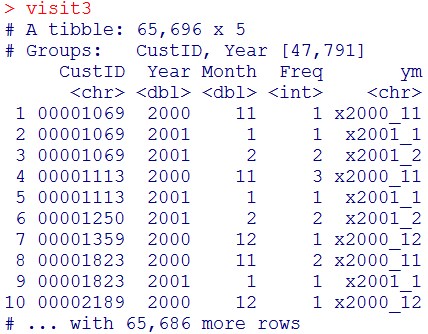 これを、グループ化を解き、Year列とMonth列を消去します。
これを、グループ化を解き、Year列とMonth列を消去します。
visit4 = visit3 %>% ungroup() %>% select(-Year, -Month)
visit4
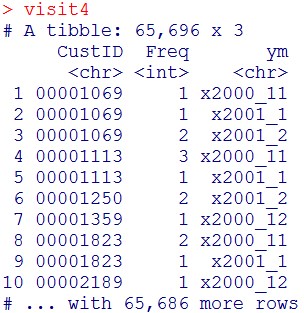 ここで、ymの成分を列名、その内容をFreq列にします。
ここで、ymの成分を列名、その内容をFreq列にします。
それには、tidyrパッケージのspread関数を用います。
まずパッケージをロードします。
library(tidyr)
#パッケージが入っていなければ以下一行実行
install.packages(“tidyr”, dependencies = T)
long型からwide型へ変換します
visit5 = visit4 %>% spread(key=ym, value=Freq, fill=0)
visit5
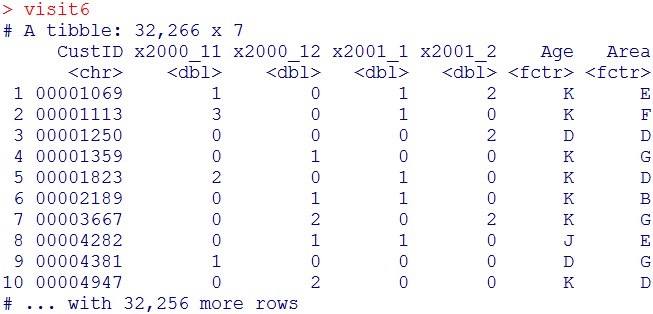
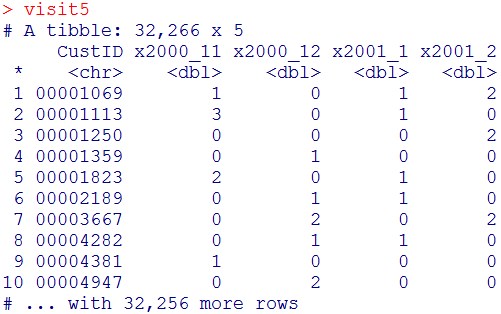 次に各行に顧客の属性情報(Age列(年齢)、Area列(居住地域))を追加します。
次に各行に顧客の属性情報(Age列(年齢)、Area列(居住地域))を追加します。
visit6 = visit5 %>% left_join(customer, key=”CustID”)
visit6
 今後教師有機械学習ランダムフォレストによる回帰を行うため、Age列と、Area列をFactor化します。
今後教師有機械学習ランダムフォレストによる回帰を行うため、Age列と、Area列をFactor化します。
visit6$Age = as.factor(visit6$Age)
visit6$Area = as.factor(visit6$Area)
visit6
さらに、CustIDは不要なので削除します。
visit7 = visit6 %>% select(-CustID)
visit7

これで、「各行が各顧客、各列が各月に顧客がスーパーを訪れた回数と顧客の属性」となりました。
さて、これから来店予測を行いますが、まず、タスクとしては、
顧客の年齢と居住地域と2000年11月と2000年12月と2001年1月の来店回数から、2001年2月の来店回数を予測する、ということを行います。
データセットを、学習用8割、テスト用2割に分割します。
#再現性確保のために乱数の種をまきます。
set.seed(123)
#整数1~nrow(visit7)の中から、
#ランダムにnrow(visit7)*0.8個選択
ind = sample(nrow(visit7), nrow(visit7)*0.8)
#学習用データセット
train = visit7[ind,]
#テスト用データセット
test = visit7[-ind,]
#結果
str(train)
str(test)
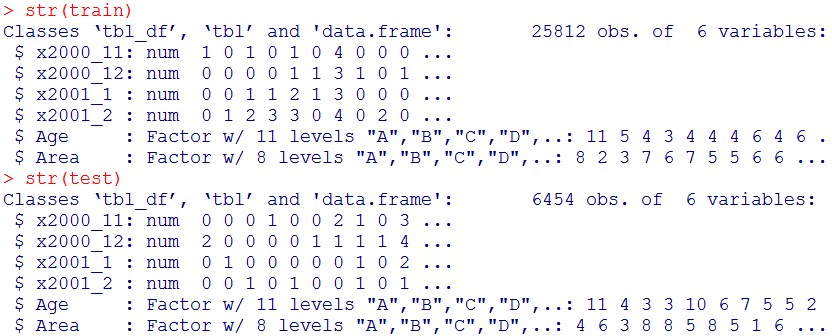 確かに、80:20に分割されました(25812:6454)
確かに、80:20に分割されました(25812:6454)
それでは、ランダムフォレストによる回帰を行っていきます。
存在するCPUコアをすべて使いたいので、doParallelパッケージをロードします。
library(doParallel)
#パッケージが入っていなければ以下一行実行
install.packages(“doParallel”, dependencies = T)
存在するCPUをすべて使えるようにします。
Cl = makeCluster(detectCores())
registerDoParallel(Cl)
ランダムフォレストパッケージをロードします。
library(randomForest)
#パッケージが入っていなければ以下を実行
install.packages(“randomForest”, dependencies=T)
ハイパーパラメータmtry(何個の変数を決定木の作成に用いるか)のtuningを行います。
tuneRF(train[,-4], train$x2001_2)
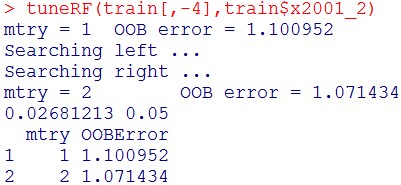 mtry = 2 がOOBErrorが小さく、mtry = 2 でよいと言えます。
mtry = 2 がOOBErrorが小さく、mtry = 2 でよいと言えます。
それでは、モデルの構築に移りましょう。
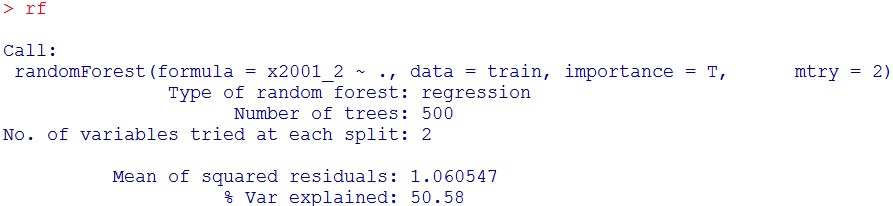
rf = randomForest(x2001_2 ~., data = train, importance = T, mtry = 2)
結果
rf
ハイパーパラメータntreeのplot
plot(rf)
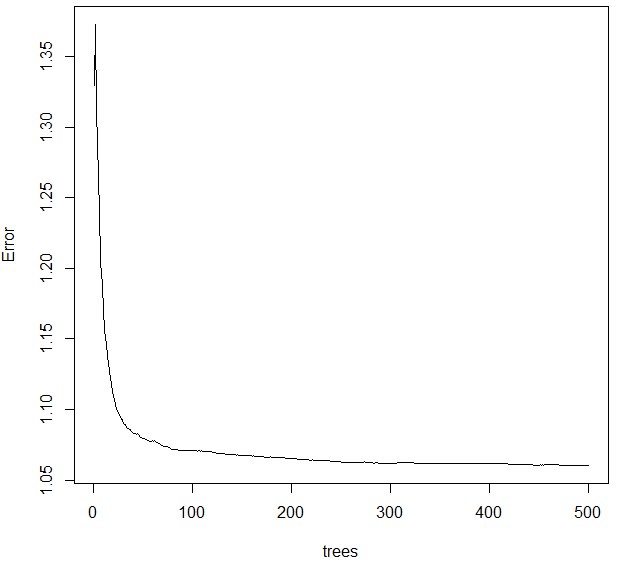 ntree=500で十分収束していることが分かります。
ntree=500で十分収束していることが分かります。
なので、ハイパーパラメータntreeのtuningはこれ以上行う必要はないです。
重要な説明変数のplot
varImpPlot(rf)
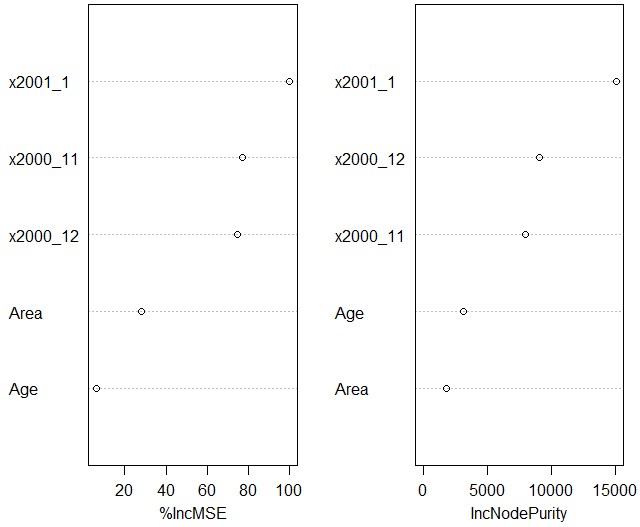 今回予測したのは、2001年2月に何回顧客が店を訪れるかで、その説明変数として最も重要なのは、前の月に何回来店したかであることが分かります。
今回予測したのは、2001年2月に何回顧客が店を訪れるかで、その説明変数として最も重要なのは、前の月に何回来店したかであることが分かります。
次に重要なのは、2000年12月と11月の来店回数です。顧客の居住地域や年齢は相対的に重要でないことがわかります。
ちなみに、今回最も重要な説明変数とわかったx2001_1と、目的変数x2001_2の散布図を取ってみると、
plot(train$x2001_1,train$x2001_2)
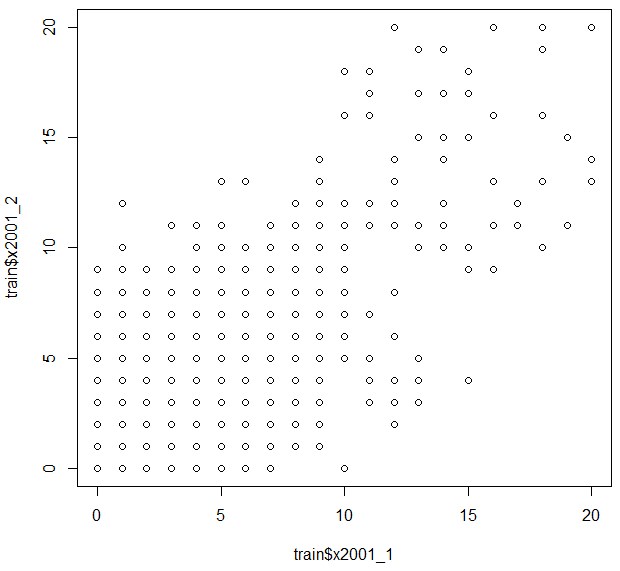 一応大雑把に比例関係にあることがわかります。
一応大雑把に比例関係にあることがわかります。
ちなみに、二番目以降に重要な説明変数とわかったx2000_12と、目的変数x2001_2の散布図を取ってみると、
plot(train$x2000_12,train$x2001_2)
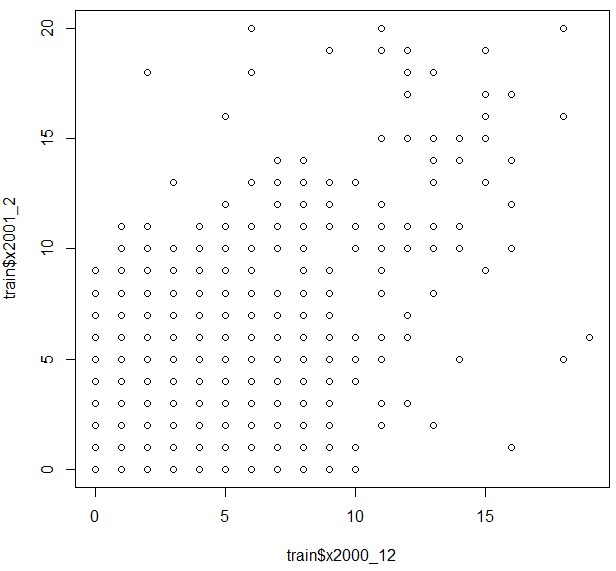 先ほどよりも、右下と左上にある点が増え、比例関係が若干薄れたことがわかります。
先ほどよりも、右下と左上にある点が増え、比例関係が若干薄れたことがわかります。
テストデータでの予測
pred = predict(rf, test[,-4])
予測結果
head(pred)
 可視化用のデータフレームの作成
可視化用のデータフレームの作成
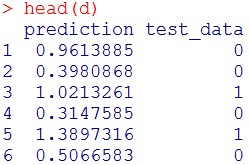
d = data.frame(prediction = pred, test_data = test$x2001_2)
予測結果の頭出し
head(d)
 可視化用パッケージのロード
可視化用パッケージのロード
library(ggplot2)
#パッケージが入っていなければ以下一行実行
install.packages(“ggplot2”, dependencies = T)
#予測値と実際の値の散布図作成
ggplot(d)+
geom_point(aes(x = test_data, y = prediction))+
geom_abline(intercept = 0, slope = 1)
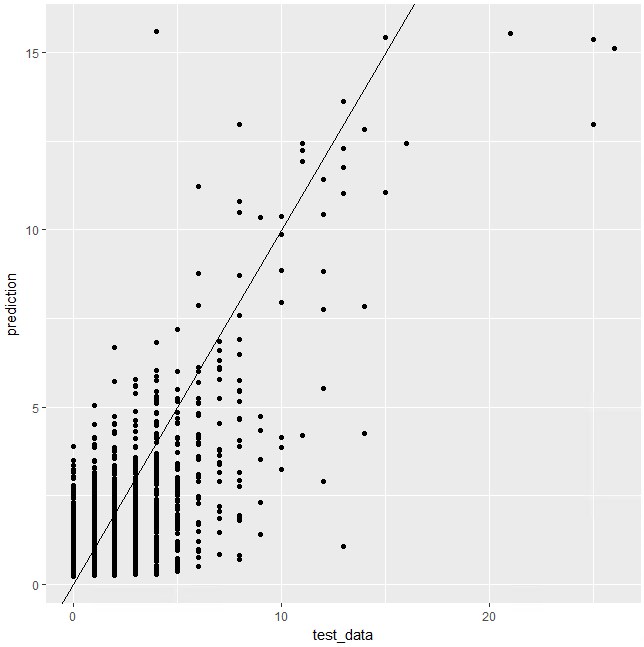
横軸がテストデータの目的変数で、縦軸が、作成したモデルを用いて、テストデータの説明変数から予測した目的変数(2001年2月の各顧客の来店回数)。
直線は、y = x を表し、予測値と実際の値が一致していると直線状に点がのり、直線に近い点ほど、実際の値が予測値に近いです。
全体として、点の分布は直線に沿っているため、予測は大雑把に的を得ていることがわかります。
RMSEを計算してみると、
二乗平均平方根誤差(RMSE)
RMSE = sqrt(mean((pred – test$x2001_2)^2))
RMSE
![]() よって、予測の際の誤差は、±1以内であることがわかります。
よって、予測の際の誤差は、±1以内であることがわかります。
機械学習のところは一瞬ですが、それまでのデータの整形にコツがあることが分かりますね。。
コツをつかむまで少々時間がかかるかもしれません。
今回はここまで。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻博士課程
実践的機械学習勉強会 代表
株式会社パッパーレ 代表取締役社長
NPO法人Bizjapan テクノロジー部門BizXチームリーダー