2016.11.04 Fri |
Rでwebscraping2

以前Rでのwebscrapingについて、入門記事を書きましたhttp://ritsuan.com/blog/4425/ が、
今回はその続編を書きたいと思います。
前回の内容を踏まえているので、まだ前回の記事をご覧になっていない方はそちらからご覧ください。
webscprapingの目的は、csvファイルやexcelファイルなどに整形されていないネット上のデータをとってきて、マーケティング、データ解析、リサーチ報告書などに生かすことを目的に行うものです。
それでは、実際にwebscrapingを実行して、ネット上から、データ解析に使うデータを取ってきましょう。
Rをまだダウンロードインストールしていない方はこちらをご覧ください。
まだ、rvestパッケージをダウンロードしていない方は以下コマンドをRのコンソール画面にコピペまたは手打ちして実行してください。
install.packages(“rvest”,dependencies=T)
それでは始めます。
まずメモリ上へのロードを行います。
library(rvest)
今回は、アメリカの各年のSocial Security Number保持者の数を性別ごとに集計した表データのwebpageをscrapingします。
https://www.ssa.gov/oact/babynames/numberUSbirths.html
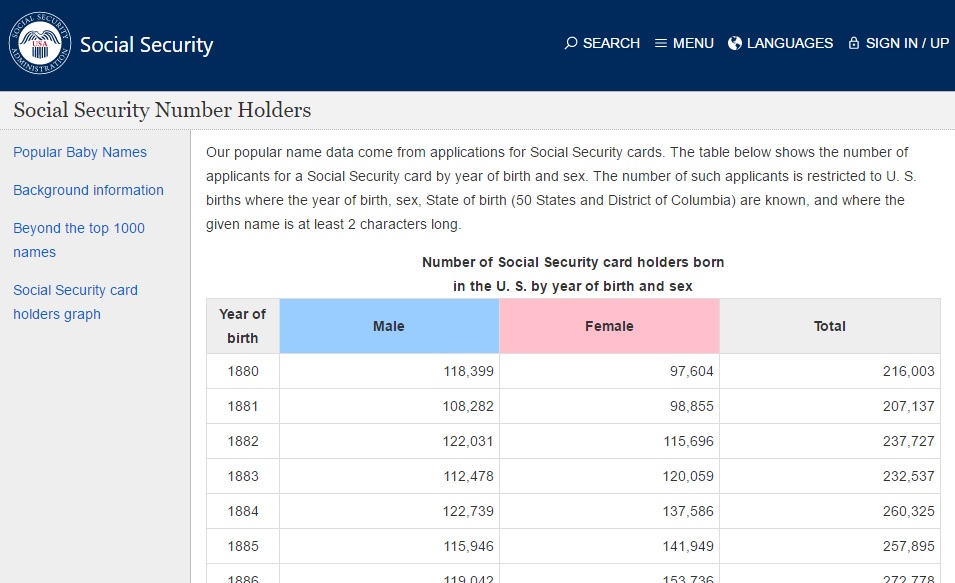
まず、このhtml文章を読み込んで、birthsという関数に読み込みましょう。
births <- read_html(“https://www.ssa.gov/oact/babynames/numberUSbirths.html”)
それでは、このbirthsの中身を確認してみましょう。

1,2の2クラスあるのが分かります。
今回は表データをとってくるので、やり方は前回とは異なり、html_node関数を使用した後、html_table関数を使用します。
births1 <- html_nodes(births, “table”)
births1
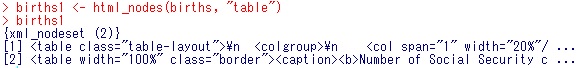
html_table(births1[[1]])
html_table(births1[[2]])
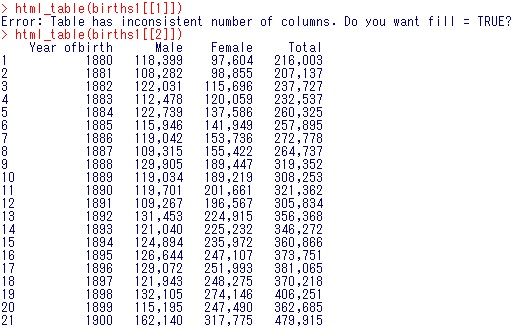
html_table(births1[[2]])の方にほしい表が取得できたのが分かりますね。
あとはこれをcsvファイルとして出力すれば完了です。
ちなみにhtml_table(births1[[1]])の実行結果ですが、ここには、tableデータ(表データ)は入っておらず、エラー文としてfill=TRUEにしたいかと聞かれますが、ここで、そうしてももともとtableデータが入っていないので、中身がいみのないNA(欠損値)だらけの表が得られるだけなので、births1[[1]]は使用しません。
では、csvファイルへのbirths1[[2]]の内容をcsvファイルに出力してみましょう。
まず先ほどの結果をresultという変数に格納します。
result=html_table(births1[[2]])
次に、write.csv関数でcsvファイルとして出力します。
write.csv(result,”result1.csv”,row.names=F)
(環境によってはrow.names=Tの方がよい場合もあります。出力結果がここでご紹介しているのと違えばrow.names=Tでやってみてください。)
しっかり書き出せたかどうか確認するために、できたファイルを読み込んでみます。
read.csv(“result1.csv”, header=T)
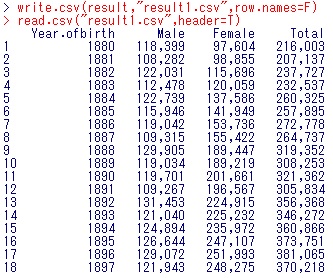
これでうまく書き出せているのが確認できました!
次にスキー競技のデータを取ってきましょう。
http://data.fis-ski.com/dynamic/results.html?sector=CC&raceid=22395
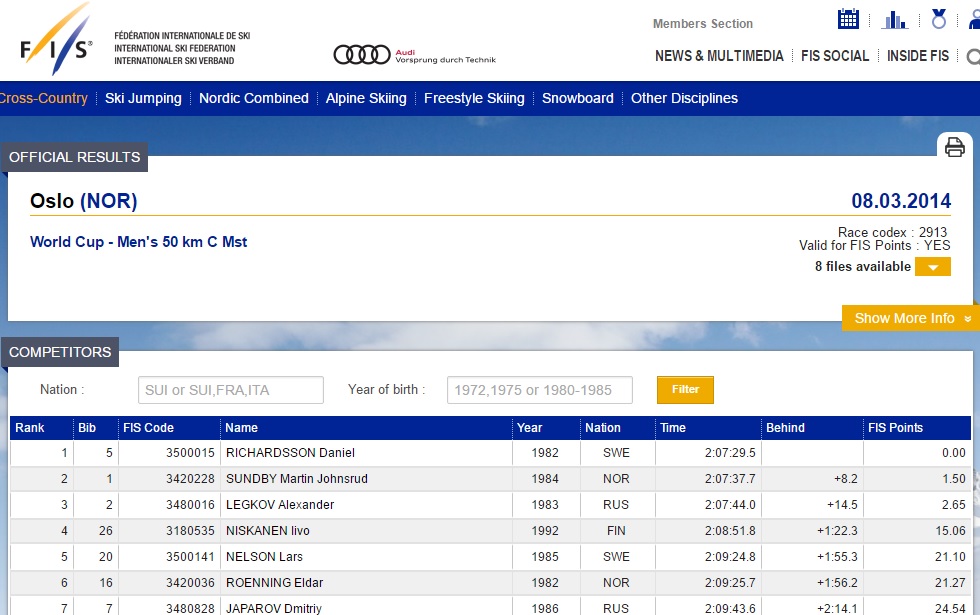
この表データを取ってきましょう。
手順は上のものを再度使用してみましょう。
skiing <- read_html(“http://data.fis-ski.com/dynamic/results.html?sector=CC&raceid=22395”)
skiing

skiing1 <- html_nodes(skiing, “table”)
skiing1
 html_table(skiing1[1])
html_table(skiing1[1])
html_table(skiing1[2])

inconsistent numberと怒られてしまいました。。fill=Tにしますかと聞いてきています。
rvestのレファレンスマニュアルにも書いてありますが、誤って各列の行数が異なるように表が作られてしまった場合、各列の行数が一番多いものに合わせて、足りないところが欠損値になるようにtableデータが作成されます。なので、fill=Tでやってみましょう。
html_table(skiing1[2], fill=T)

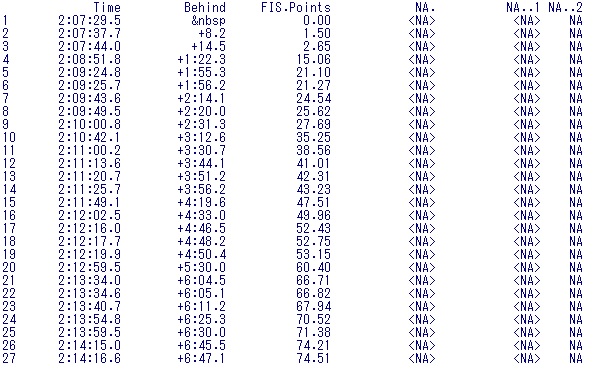
できました!
ただ下の方を見てみると、、

と欠損値がはいっているのが分かると思います。NAはNot Availableの略です。
これがfill=Tの効果ですね。
元データはどうなっているのでしょうか?もう一度webpageの方を見てみましょう。
http://data.fis-ski.com/dynamic/results.html?sector=CC&raceid=22395
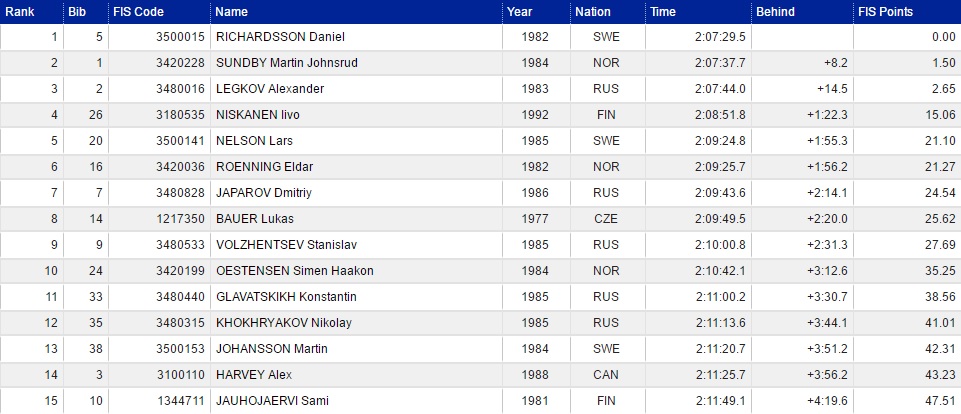
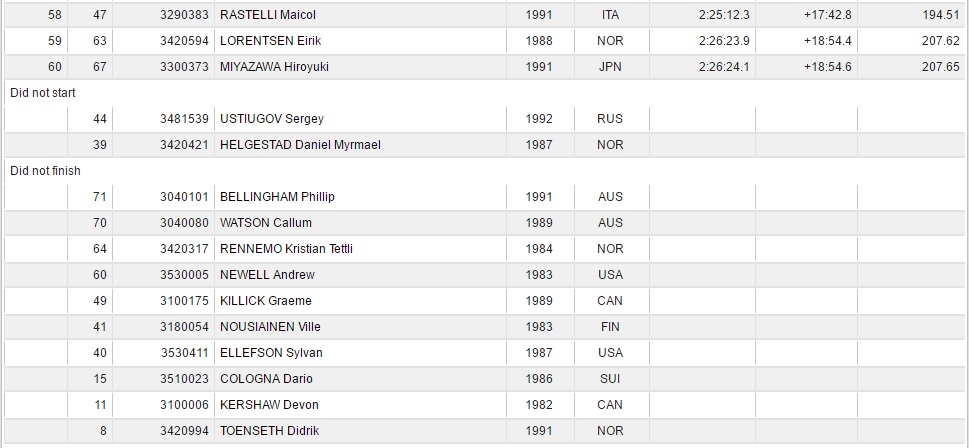
Behind列の1行目に欠損値があるのと、下から11,14行目にDid not startとDid not finishがありますね。あと、下の方には、Time,Behind,FISPointがないですね。たしかにきれいな表データではなかったですね。本来は9列のデータです。
とりあえず今回できたものを出力して、再度読み込んでみます。
skiing <- read_html(“http://data.fis-ski.com/dynamic/results.html?sector=CC&raceid=22395”)
skiing1 <- html_nodes(skiing, “table”)
result2<-html_table(skiing1[2], fill=T)
write.csv(result2,”result4.csv”,row.names=F)
result<-read.csv(“result4.csv”,header=T)
これで出力から読み込みまで終わったので、読み込んだ中身を見てみましょう。
str(result)
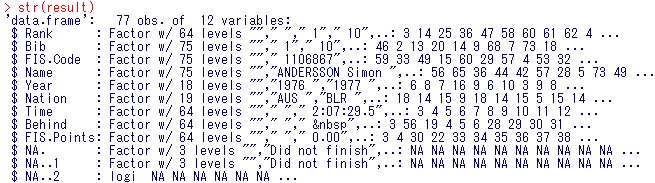
result

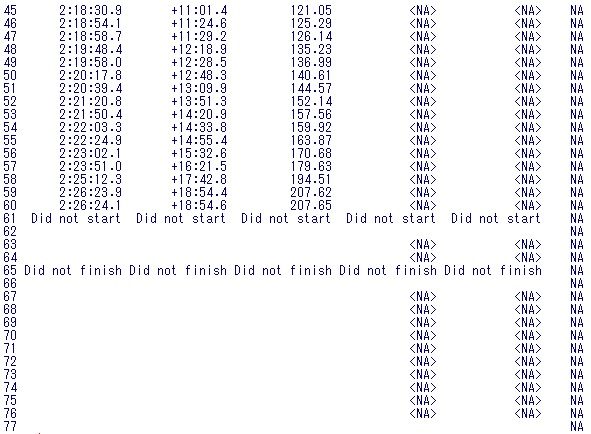
下の方まで見ていくと、どうやら、後3列は不要なことが分かります。
result<-result[,1:9]
str(result)
write.csv(result,”ski.csv”,row.names=F)
read.csv(“ski.csv”,header=T)

これで無事読み込めましたね。
フォーマットがずれている場合は、少し大変です。
しかし、定期的にあるサイトが更新されて、毎回コピペでとってくるのが面倒な場合、自動化したいですよね?
URLだけ指定して、頻繁に表データを取得したい場合、このような作業は避けて通れません。
またデータをとってくるべきURLが数百個以上ある場合、自動化はせざるを得ないですね。
普通の人は直面しない問題かもしれませんが、コンサル業務やリサーチ業務ではよく発生するタスクです。なので、将来それらの職種につきたい人はぜひ早いうちにwebscrapingをやっておきましょう。Rでのwebscrapingができると、その後スムーズにRでのデータ解析ができるのでオススメです。
今日はこの辺で終わりにします。
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程1年
一般社団法人Bizjapan(http://bizjapan.org/en/)
東京大学機械学習勉強会(http://www.machine-learning-r.com/)