2017.05.13 Sat |
Kaggleデータ探索(McDonald’s Menu Data)

今回は、KaggleDataで、マクドナルドのメニューの栄養素データを見つけたのでそれで何ができるか試してみようかなと思います。
 https://www.kaggle.com/datasets
https://www.kaggle.com/datasets
このデータセットは、朝食、牛肉ハンバーガー、鶏肉と魚サンドイッチ、フライドポテト、サラダ、ソーダ、コーヒーと紅茶、ミルクシェイク、デザートなど、米国のマクドナルドメニューの各メニュー項目の栄養の量に関するデータをMacdonaldのwebsiteからとってきたものだそうです。
このデータを活用することで、たとえばカロリーをとりすぎないように、卵黄抜きで料理してもらったり、商品を買いすぎないようにしたり、逆にカロリーや何らかの栄養素が足りない場合、何かを追加注文することで、それらを満たすことが、データの活用方法として想定されているとのことです。
データをダウンロード・解凍すると、menu.csvというファイルが入っています。
早速読み込んでみましょう。
d=read.csv(“menu.csv”,header=T)
str(d)
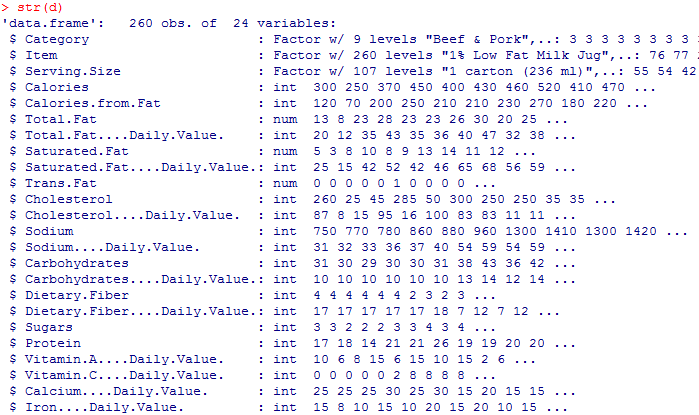 データ数が260件、変数24列とは、扱いやすくて非常にうれしいです。
データ数が260件、変数24列とは、扱いやすくて非常にうれしいです。
#データの頭出しも見てみましょう。
head(d)
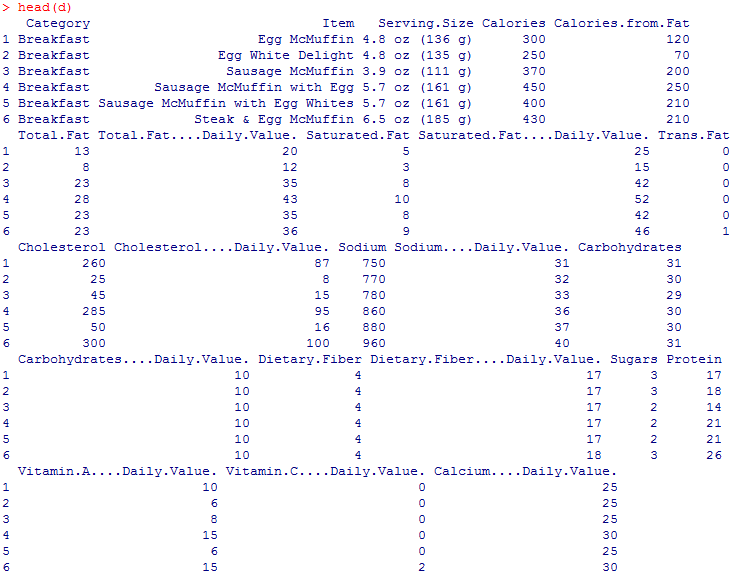 見た感じ前処理が必要なのは、3列目のServing.Sizeだけですね。
見た感じ前処理が必要なのは、3列目のServing.Sizeだけですね。
ここで、Serving.Size列の詳細を見てみましょう。
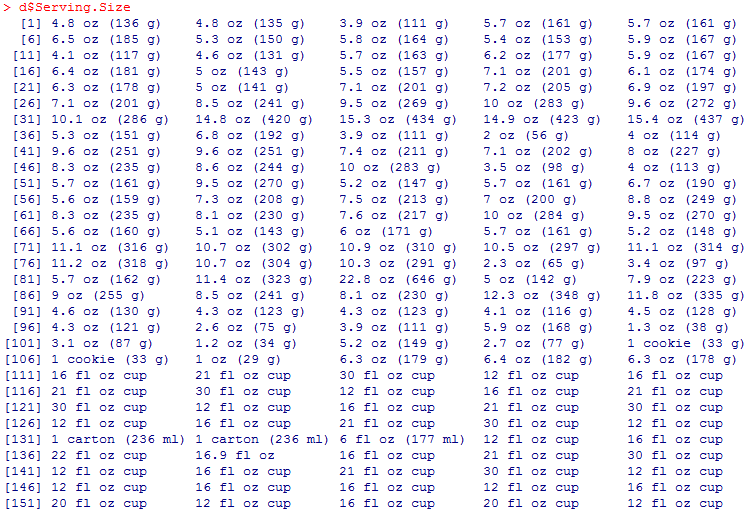 表記方法が、
表記方法が、
4.8 oz (136 g)
1 cookie (33 g)
16 fl oz cup
1 carton (236 ml)
と4種類あります。
ozというのはオンス(ounce)の略称で、1オンス = 28.3495グラムです。
ただし今回はすでにg(グラム)に直してくれているのでそれを使いましょう。
fl ozというのは液量オンス(fluid ounce)でオンスとは異なります。イギリスとアメリカでは異なるのですが今回のデータはアメリカのマクドナルドのWebsiteからとってきているとのことなので、
1米液量オンス=29.5735ml(ミリリットル)を用いましょう。
すでにもうややこしいですね汗
今回4つの表記法のうち食べ物の重さである上二つはグラムで、飲み物の重さであるした二つはミリリットルで表すことにします。
高々260件なので手で修正してもいいくらいなんですが、ここはしっかり正規表現など使って前処理していきましょう。
はっきり言って、Serving.Size列の前処理は簡単ではありません。
ただ、データサイエンティストが前処理ストと呼ばれるように実際こういうデータはよくあるので少しでもなれることが重要と思います。
#Serving.Size列を文字列型に変換する
d$Serving.Size = as.character(d$Serving.Size)
#丸カッコ内から内容を取り出す(gsub関数は文字列置換関数で第一引数が正規表現)
d$Serving.Size = gsub(“.*\\((.*)\\).*”, “\\1”, d$Serving.Size)
d$Serving.Size

#stringrパッケージのstr_detect関数を使用
library(stringr)
d$Serving.Size[str_detect(d$Serving.Size, “oz”)] = paste(as.integer(29.5735*as.numeric(gsub(“([0-9]+).*$”, “\\1”, d$Serving.Size[str_detect(d$Serving.Size, “oz”)]))), “ml”)
d$Serving.Size
#food列とdrink列を新たに作成し、商品がfoodであれば、food列がTRUE,drinkであればdrink列がTRUEとなるようにする。
d$food = as.factor(grepl(“g”, d$Serving.Size))
d$drink = as.factor(grepl(“ml”, d$Serving.Size))
head(d$food)
head(d$drink)
#gを消去
d$Serving.Size[d$food == TRUE] = gsub(” g”, “”, d$Serving.Size[d$food == TRUE])
d$Serving.Size
 #mlを消去
#mlを消去
d$Serving.Size[d$drink == TRUE] = gsub(” ml”, “”, d$Serving.Size[d$drink == TRUE])
d$Serving.Size
 #文字列から実数型へ変換
#文字列から実数型へ変換
d$Serving.Size = as.numeric(d$Serving.Size)
d$Serving.Size
同じ列にgとmlが混在しているなんておかしい。という方もいらっしゃると思います。ごもっともです。
ですが今回は簡単のため1g=1mlとして計算してしまいます。ざっくり全部gに変換したとお考え下さい。水は1L=1kgなのでそれほど間違ってはいないはずです。
せっかくなのでここでデータを保存します(Rならrow.names=Fが必要で、RStudioなら不要)。
write.csv(d,”mac.csv”,row.names=F)
さて、集計と可視化によってデータの内容を把握していきましょう。
まず各変数の可視化をしていきます。
ggplot2パッケージを使用します。
library(ggplot2)
#Serving.Size列の可視化
ggplot(data=d, aes(x=Serving.Size))+
geom_bar()+
facet_wrap(~ Category, nrow = 2)
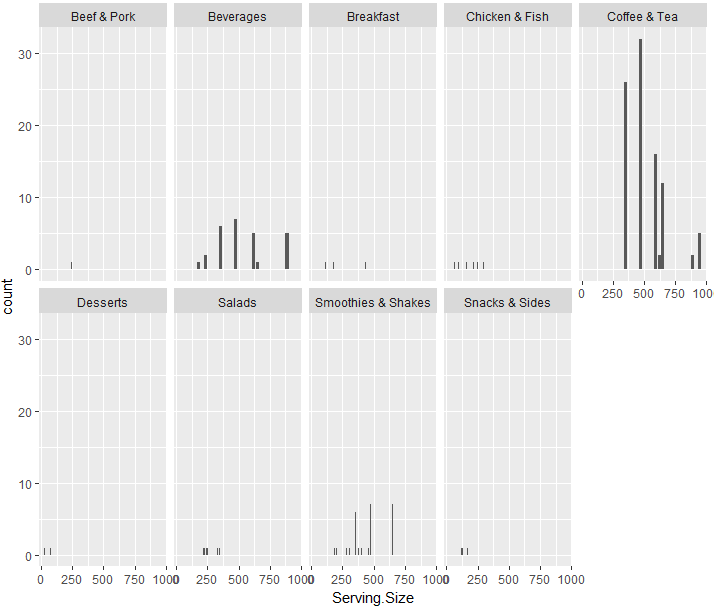 一応Serve.Size列の概要は把握できました。この単位はグラムであり、重量は飲み物の方が重いので納得できます。
一応Serve.Size列の概要は把握できました。この単位はグラムであり、重量は飲み物の方が重いので納得できます。
#カロリーの可視化
ggplot(data=d, aes(x=Calories))+
geom_bar()+
facet_wrap(~ Category, nrow = 2)
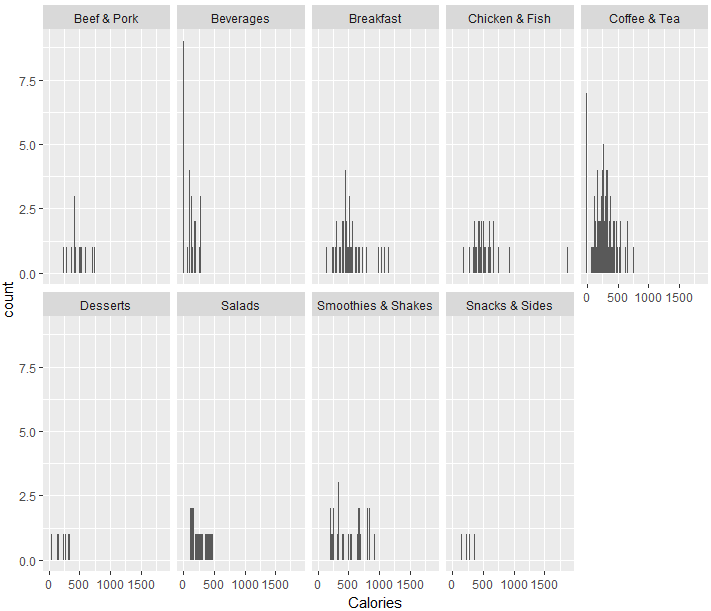 Caloryが高いのは、Breakfast、Chicken & Fish、Smoothies & Shakesみたいですね。
Caloryが高いのは、Breakfast、Chicken & Fish、Smoothies & Shakesみたいですね。
#脂質の総量の可視化
ggplot(data=d, aes(x=Total.Fat))+
geom_bar()+
facet_wrap(~ Category, nrow = 2)
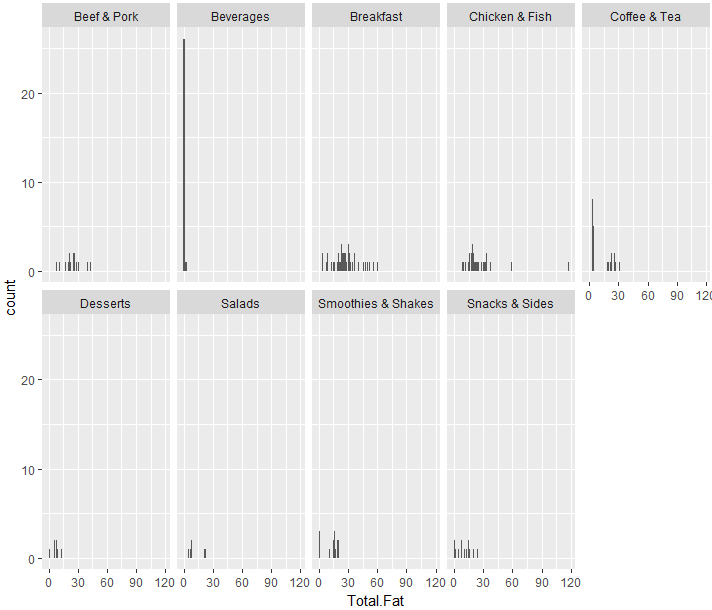 脂質の総量は朝食(Beakfast)が多いですね。あと鶏肉と魚肉(Chicken&Fish)、牛肉と豚肉(Beef&Pork)。
脂質の総量は朝食(Beakfast)が多いですね。あと鶏肉と魚肉(Chicken&Fish)、牛肉と豚肉(Beef&Pork)。
カテゴリーごとに見ていってもあまりおもしろくないので、いくつかの変数の同時可視化を行ってみます。
#塩(Sodium)、炭水化物(Carbohydrates)、タンパク質(Protein)の可視化
ggplot(data = d) +
geom_point(mapping =
aes(x = Sodium, y = Carbohydrates, color = Category, size = Protein),
alpha = 1 / 3)
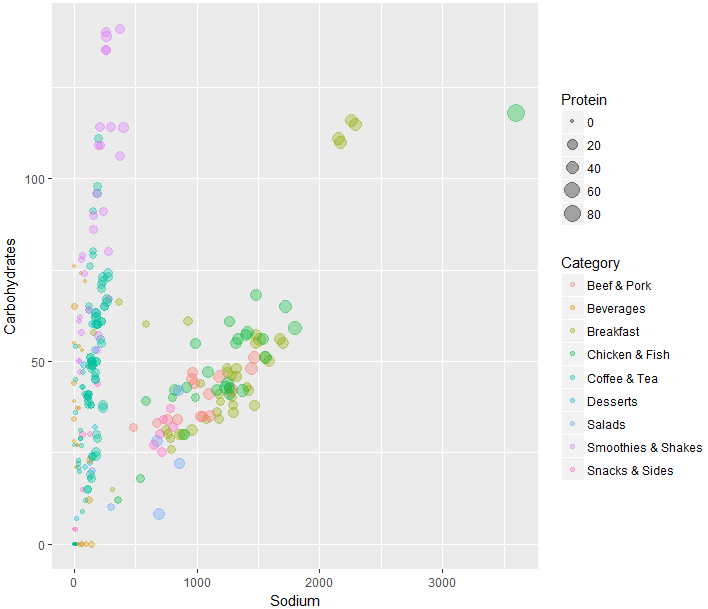 この可視化はいい感じですね。Categoryごとの違いがよくわかります。
この可視化はいい感じですね。Categoryごとの違いがよくわかります。
たとえば、Smoothies & ShakesがCarbohydrate(炭水化物)が多いこと、基本的に塩(Sodium)量と炭水化物量は比例することなどです。
#砂糖(Sugars)、飽和脂肪(Saturated.Fat)、食物繊維(Dietary.Fiber)の可視化
ggplot(data = d) +
geom_point(mapping =
aes(x = Sugars, y = Saturated.Fat, color = Category, size = Dietary.Fiber),
alpha = 1 / 3)
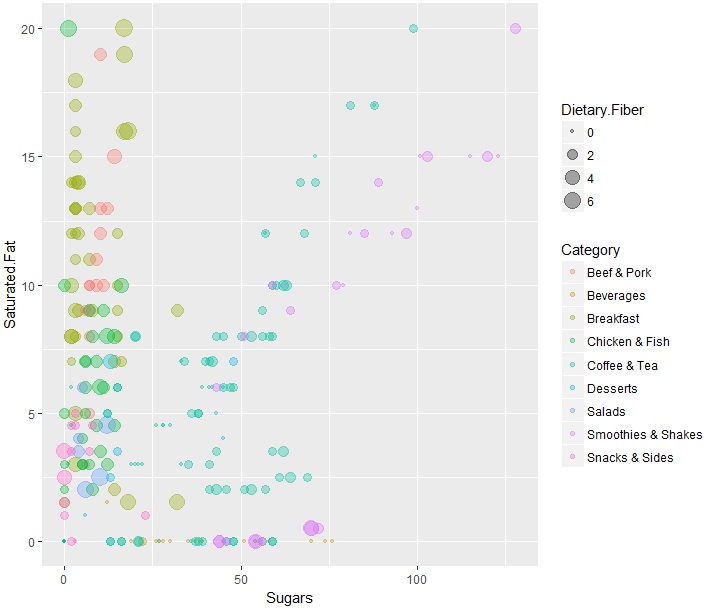 基本的にBreakfast(朝ごはん)が飽和脂肪が多いみたいですね。。飽和脂肪はたしか体に良くないと記憶しているのですが(論文では見かけませんが)、、朝マックは良くないということでしょうか。。一応弁解しておくと、朝マックには、食物繊維(Dietary.Fiber)はそれなりに含まれるようです。
基本的にBreakfast(朝ごはん)が飽和脂肪が多いみたいですね。。飽和脂肪はたしか体に良くないと記憶しているのですが(論文では見かけませんが)、、朝マックは良くないということでしょうか。。一応弁解しておくと、朝マックには、食物繊維(Dietary.Fiber)はそれなりに含まれるようです。
飲料(Beverages)、コーヒー・紅茶(Coffee&Tea)、スムージーとシェイク(Smoothies&Shakes)などには砂糖(Sugars)が多いことは容易に想像がつくのですが、飽和脂肪も多いみたいですね。ミルクという名前の油と乳化剤混ぜたやつが飽和脂肪量を押し上げているんですかね。
#ビタミンA(Vitamin.A….Daily.Value.)、カルシウム(Calcium….Daily.Value.)、鉄分(Iron….Daily.Value.)の可視化
ggplot(data = d) +
geom_point(mapping =
aes(x = Vitamin.A….Daily.Value., y = Calcium….Daily.Value., color = Category, size = Iron….Daily.Value.),
alpha = 1 / 3)
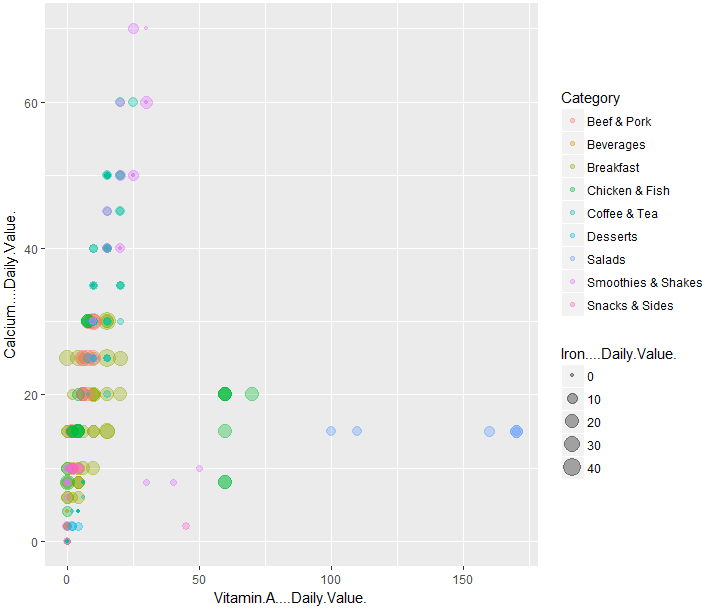 ビタミンAはサラダと鶏肉・魚肉に多く含まれているようです。
ビタミンAはサラダと鶏肉・魚肉に多く含まれているようです。
意外なのは、鉄分がBreakfastに多く含まれていることですね。ちゃんと考えているのだと思います。
カルシウムは、コーヒー・紅茶(Coffee&Tea)、スムージーとシェイク(Smoothies&Shakes)などの牛乳が含まれている系なものに多く含まれているようです。
#トランス脂肪(Trans.Fat)、ビタミンC(Vitamin.C….Daily.Value.)、コレステロール(Cholesterol)の可視化
ggplot(data = d) +
geom_point(mapping =
aes(x =Trans.Fat, y =Vitamin.C….Daily.Value.,color=2, size = Cholesterol),alpha = 1 / 5)+
facet_wrap(~ Category, nrow = 2)
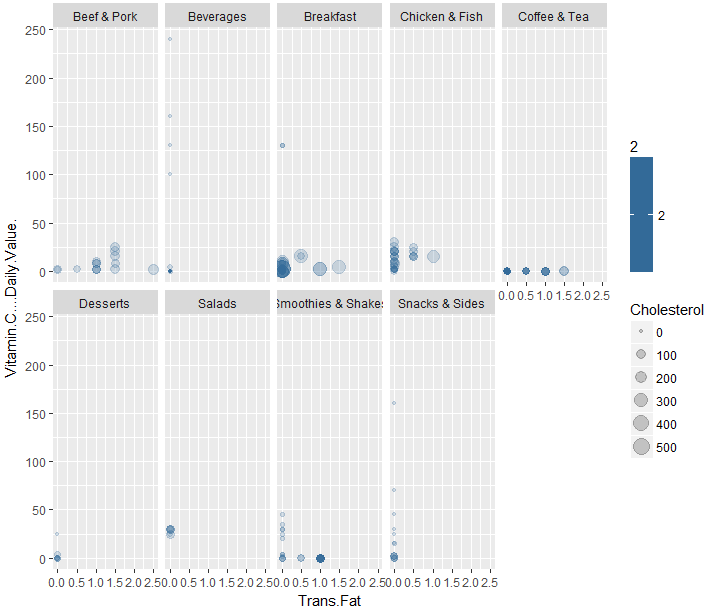 ビタミンCは、飲み物(Beverage)に多く含まれているようですね。
ビタミンCは、飲み物(Beverage)に多く含まれているようですね。
朝食(Breakfast)と鶏肉・魚肉(Chicken & Fish)にはコレステロールが多く含まれているようですね。コレステロールは一概に体に良い悪い言えませんが。
トランス脂肪(Trans.Fat)は、飲料(Beverages)、デザート(Desserts)、サラダ(Salads)、スナック(Snacks & Sides)には含まれていないようですね。スナックに含まれていないのが意外でした。
今回はこの辺でMacdonaldのメニューの栄養解析を終わりにしたいと思います。
このデータは、売り上げデータなどの顧客データが含まれないため、ビジネスに生かすのは難しいとは思いますが、前処理の練習になるのと、可視化の練習にはなるかなと思います。
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程1年
東京大学機械学習勉強会 代表
NPO法人 Bizjapan テクノロジー部門BizX チームリーダー