2017.05.16 Tue |
Kaggleデータ探索(Speed Dating Experiment)その3

前回(Kaggleデータ探索(Speed Dating Experiment): http://ritsuan.com/blog/6387/)
と前々回(Kaggleデータ探索(Speed Dating Experiment)その2: http://ritsuan.com/blog/6406/)
に引き続き、Speed Dating Experimentについて扱っていこうと思います。
前回と前々回で、195個の変数の内容を解説し終えました。
ようやく中身の解説に入っていけるわけです。。
データ解析の前の、前処理の前の、データの理解と解説で9時間ほどかかってしまって、早くも出鼻をくじかれているのですが、頑張っていきましょう。
それでは、まずデータの読み込みです。
#データの読み込み
d=read.csv(“Speed Dating Data.csv”,header=T)
#このデータでは大きく分けて2つの前処理が必要です。
income列とtuition列とmn_sat列が、各要素が”86,340.00″のように、コンマが入っているので、コンマを取り除く必要があります。
その次に、実験単位であるWaveの 6-9タームにて、他のタームとは違った回答方法が指定されている(6-9ターム:6項目を各10点満点で評価、1-5と10-21ターム:合計点が100点になるように6項目を評価)ので、Waveの6-9タームの結果を他のタームに合わせる作業が必要になります。
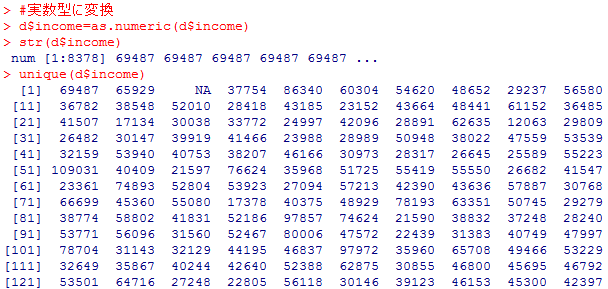
#income列の内容確認
str(d$income)
unique(d$income)
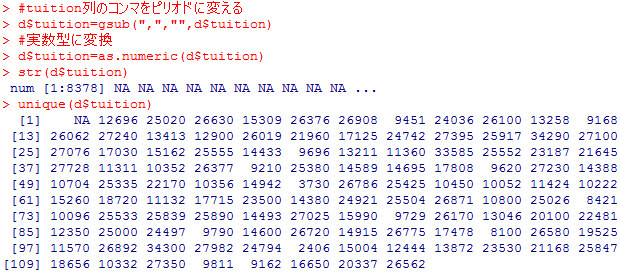
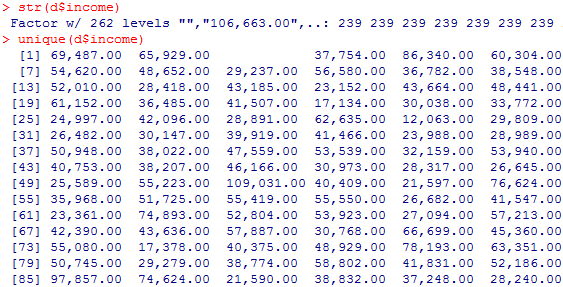 #tuition列の内容確認
#tuition列の内容確認
str(d$tuition)
unique(d$tuition)
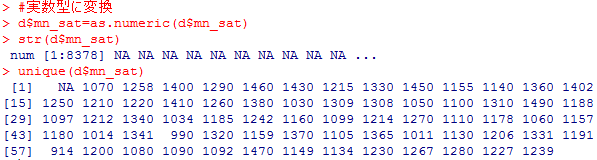
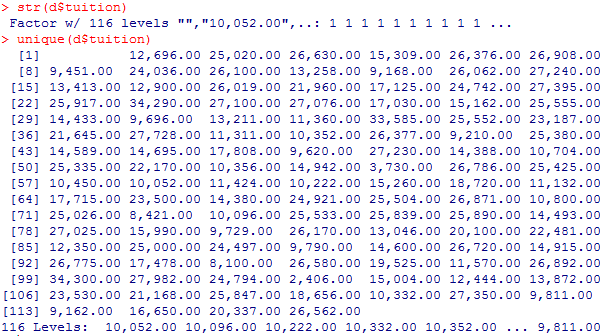 #mn_sat列の内容確認
#mn_sat列の内容確認
str(d$mn_sat)
unique(d$mn_sat)
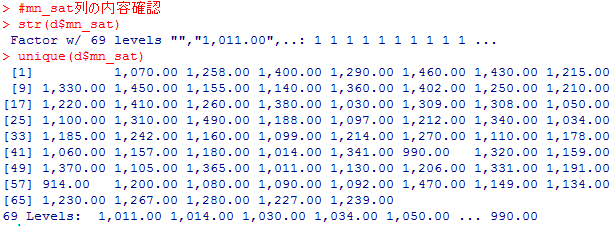
#income列のコンマをピリオドに変える
d$income=gsub(“,”,””,d$income)
#結果確認
str(d$income)
unique(d$income)
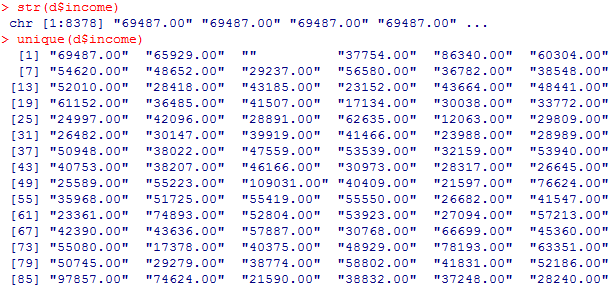 #実数型に変換
#実数型に変換
d$income=as.numeric(d$income)
str(d$income)
unique(d$income)
 #tuition列のコンマをピリオドに変える
#tuition列のコンマをピリオドに変える
d$tuition=gsub(“,”,””,d$tuition)
#実数型に変換
d$tuition=as.numeric(d$tuition)
str(d$tuition)
unique(d$tuition)
#mn_sat列のコンマをピリオドに変える
d$mn_sat=gsub(“,”,””,d$mn_sat)
#実数型に変換
d$mn_sat=as.numeric(d$mn_sat)
str(d$mn_sat)
unique(d$mn_sat)
それでは次に、Waveの6-9タームの結果を他のタームに合わせる作業を行います。
これは直さないといけない変数が多く大変ですが頑張っていきましょう。
まず、
attr1_1
sinc1_1
intel1_1
fun1_1
amb1_1
shar1_1
の6列からですね。
library(dplyr)
library(ggplot2)
d %>% filter(wave <= 9 & 6 <= wave) %>% ggplot(aes(attr1_1)) + geom_histogram(binwidth = 1)
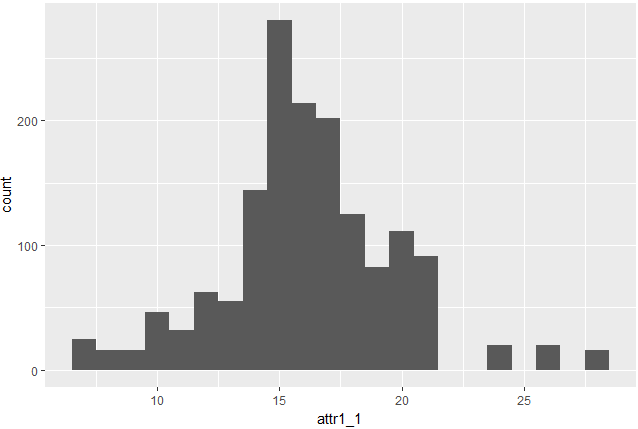 本来、0-10のところに分布の山が存在しているはずなんですが、なんかおかしいですね。。
本来、0-10のところに分布の山が存在しているはずなんですが、なんかおかしいですね。。
waveを6から9までとってこれていないのでしょうか?
d %>% filter(wave <= 9 & 6 <= wave) %>% ggplot(aes(wave)) +geom_bar()
 いや、とれています。
いや、とれています。
おそらく、変数の説明が間違っているのだと思います。間違っていたとしても、6項目全部足して各項目を割り100を掛ける方針は変わりません。
よく考えてみると、waveが1-5と10-21タームでは合計点が100点になるように6項目を評価、となっていますが、アンケートに答えたすべての人が、毎回合計100点になるように計算できている気がしません。
なので、すべてのwaveに関して、”6項目全部足して各項目を割り100を掛ける”前処理を適用しようと思います。新しい変数を作成し各新しい変数の末尾にはcorrectされたということで、cをつけたいと思います。
d = d %>%
mutate(sum1_1=attr1_1+sinc1_1+intel1_1+fun1_1+amb1_1+shar1_1) %>%
mutate(attr1_1c=(attr1_1/sum1_1)*100) %>%
mutate(sinc1_1c=(sinc1_1/sum1_1)*100) %>%
mutate(intel1_1c=(intel1_1/sum1_1)*100) %>%
mutate(fun1_1c=(fun1_1/sum1_1)*100) %>%
mutate(amb1_1c=(amb1_1/sum1_1)*100) %>%
mutate(shar1_1c=(shar1_1/sum1_1)*100)
#確認
summary(d$attr1_1c)
summary(d$sinc1_1c)
summary(d$intel1_1c)
summary(d$fun1_1c)
summary(d$amb1_1c)
summary(d$shar1_1c)
 attr1_1cの最大値が100があるあたり、他の5項目すべて0の人がいるということで、このアンケート結果がどれだけちゃんと記入されているのか、疑問符が付きますが、そこは目をつぶっていきましょう。
attr1_1cの最大値が100があるあたり、他の5項目すべて0の人がいるということで、このアンケート結果がどれだけちゃんと記入されているのか、疑問符が付きますが、そこは目をつぶっていきましょう。
こんな感じで、しばらく変数を前処理していきます。
d = d %>%
mutate(sum4_1=attr4_1+sinc4_1+intel4_1+fun4_1+amb4_1+shar4_1) %>%
mutate(attr4_1c=(attr4_1/sum4_1)*100) %>%
mutate(sinc4_1c=(sinc4_1/sum4_1)*100) %>%
mutate(intel4_1c=(intel4_1/sum4_1)*100) %>%
mutate(fun4_1c=(fun4_1/sum4_1)*100) %>%
mutate(amb4_1c=(amb4_1/sum4_1)*100) %>%
mutate(shar4_1c=(shar4_1/sum4_1)*100)
#確認
summary(d$attr4_1c)
summary(d$sinc4_1c)
summary(d$intel4_1c)
summary(d$fun4_1c)
summary(d$amb4_1c)
summary(d$shar4_1c)
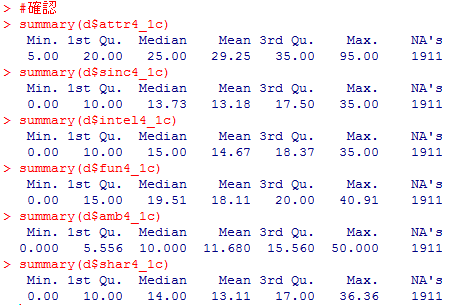 今回は、最大値100はないようです。
今回は、最大値100はないようです。
欠損値が多いですね。。
d = d %>%
mutate(sum2_1=attr2_1+sinc2_1+intel2_1+fun2_1+amb2_1+shar2_1) %>%
mutate(attr2_1c=(attr2_1/sum2_1)*100) %>%
mutate(sinc2_1c=(sinc2_1/sum2_1)*100) %>%
mutate(intel2_1c=(intel2_1/sum2_1)*100) %>%
mutate(fun2_1c=(fun2_1/sum2_1)*100) %>%
mutate(amb2_1c=(amb2_1/sum2_1)*100) %>%
mutate(shar2_1c=(shar2_1/sum2_1)*100)
#確認
summary(d$attr2_1c)
summary(d$sinc2_1c)
summary(d$intel2_1c)
summary(d$fun2_1c)
summary(d$amb2_1c)
summary(d$shar2_1c)

d = d %>%
mutate(sum1_2=attr1_2+sinc1_2+intel1_2+fun1_2+amb1_2+shar1_2) %>%
mutate(attr1_2c=(attr1_2/sum1_2)*100) %>%
mutate(sinc1_2c=(sinc1_2/sum1_2)*100) %>%
mutate(intel1_2c=(intel1_2/sum1_2)*100) %>%
mutate(fun1_2c=(fun1_2/sum1_2)*100) %>%
mutate(amb1_2c=(amb1_2/sum1_2)*100) %>%
mutate(shar1_2c=(shar1_2/sum1_2)*100)
#確認
summary(d$attr1_2c)
summary(d$sinc1_2c)
summary(d$intel1_2c)
summary(d$fun1_2c)
summary(d$amb1_2c)
summary(d$shar1_2c)
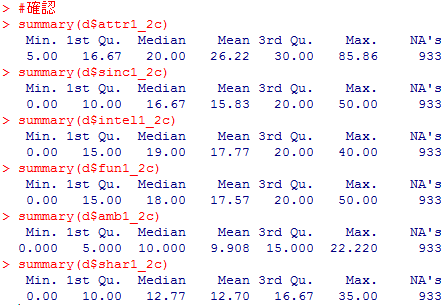
長く続いた前処理もこれで終わりです!
さて解析に入っていきましょう!
まずは、個人的に、
dec:相手にもう一度会いたいかどうか(Yes:1,No:0,Other:NA)
という変数に興味があるんですよね。
たぶん、男性にも女性にも、人気者と不人気者がいて二極化しているのではないかということを検証していきたいと思います。
ユニークid(iid)と性別(gender:Female=0,Male=1)でdec列の合計算出してヒストグラムを作成してみましょう。
#マッチング(両者がまた会いたいといったかどうか)を男女別で集計
d %>% group_by(iid,gender) %>% summarise(famous=sum(dec)) %>% ggplot(aes(famous)) + geom_histogram(binwidth = 1) + facet_wrap(~ gender, nrow = 1)
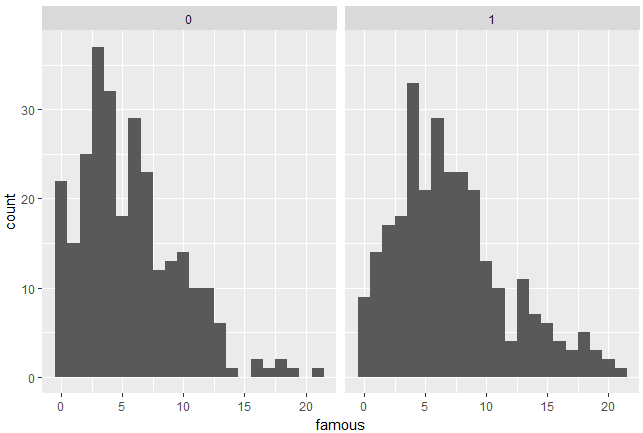 むむ。。不人気者が少ないですね。よく考えてみれば、この母集団は、コロンビア大学院関連の人たちでした。。いわばエリート集団だったわけですね。
むむ。。不人気者が少ないですね。よく考えてみれば、この母集団は、コロンビア大学院関連の人たちでした。。いわばエリート集団だったわけですね。
誰ともマッチンングしなかった人は、男性(右の表)だと10人、女性だと22人しかいません。一般的な母集団でこの実験をすれば、だれともマッチングしなかった人がもっと増えると思います。
一応仮説に立てた、”二極化”は男性で進んでいるようです。マッチングの数が15件を超えている人が女性だと7人しかいないのに、男性だと、32人います。ただこれは、女性の方は、限られた人数の男性にしか”また会いたい”と言わないのに、男性の方は、より多くの人に”また会いたい”と言ってしまうことからくるのかもしれませんね。
次は、人種ごと・性別ごとに、異性の何を重視するか集計してみましょう。
まず人種は、race列に格納されており、内容は、
Black/African American=1
European/Caucasian-American=2
Latino/Hispanic American=3
Asian/Pacific Islander/Asian-American=4
Native American=5(今回のデータには実際は含まれない)
Other=6
NA
となっています。
被験者が、異性の何を重視するかは、以下の変数です。
attr1_1c:魅力(Attractive)
sinc1_1c:誠実さ(Sincere)
intel1_1c:知性(Intelligent)
fun1_1c:楽しさ(Fun)
amb1_1c:野心(Ambitious)
shar1_1c:共通した興味・趣味(shared interests/hobbies)
expnum:20人会った中で、何人があなたとのデートに興味を持ったと予想するか。
imprace:デートする相手が自分と同じ人種・民族であることが重要かを0-10で評価(実際のデータにはNAを含む)
imprelig:デートする相手が自分と同じ宗教を信じることが重要かを1-10で評価(実際のデータにはNAを含む)
まずは、attr1_1c:魅力(Attractive)について、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,attr1_1c) %>% summarise(Attractive=mean(attr1_1c)) %>%ggplot(aes(Attractive)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
 人種ごとに少しだけ違いますね。男性(1)の方が女性(0)より、魅力を重要視する傾向があります。ただ論文に書いてあるほど、顕著な違いはないように思います(上段と下段であまり変わらないですよね?)。
人種ごとに少しだけ違いますね。男性(1)の方が女性(0)より、魅力を重要視する傾向があります。ただ論文に書いてあるほど、顕著な違いはないように思います(上段と下段であまり変わらないですよね?)。
上に並んでいるラベルは、1=Black/African American
2=European/Caucasian-American
3=Latino/Hispanic American
4=Asian/Pacific Islander/Asian-American
5=Native American(今回のデータには実際は含まれない)
6=Otherで、
右のラベルは、0が女性、1が男性、です。
次は、誠実さ:Sincereについて、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,sinc1_1c) %>% summarise(Sincere=mean(sinc1_1c)) %>%ggplot(aes(Sincere)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
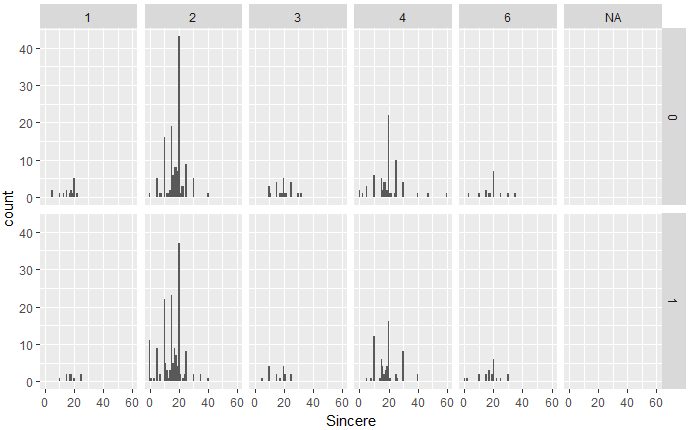 人種ごとではちがいはあるものの性別ごとではほとんど違いはないですね。
人種ごとではちがいはあるものの性別ごとではほとんど違いはないですね。
次は、知性:Intelligentについて、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,intel1_1c) %>% summarise(Intelligent=mean(intel1_1c)) %>% ggplot(aes(Intelligent)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
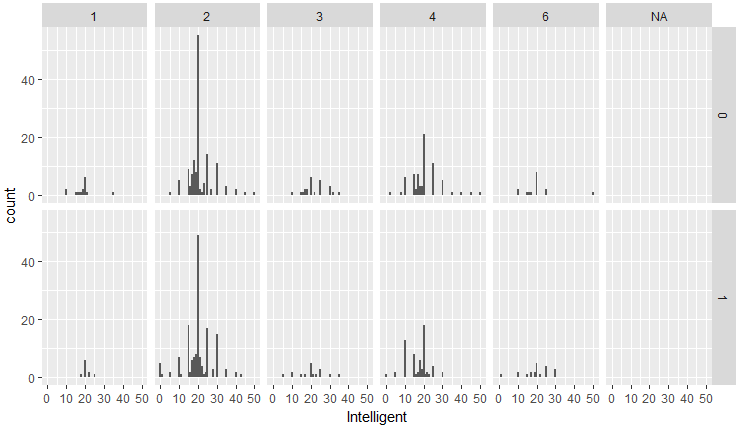 大雑把にみると、知性への重要視の姿勢は、人種・男女ともにあまりありませんが、よく見ると少しだけ、女性の方が重要視する人が多いように思います。
大雑把にみると、知性への重要視の姿勢は、人種・男女ともにあまりありませんが、よく見ると少しだけ、女性の方が重要視する人が多いように思います。
次は、楽しさ:Funについて、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,fun1_1c) %>% summarise(Fun=mean(fun1_1c)) %>% ggplot(aes(Fun)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
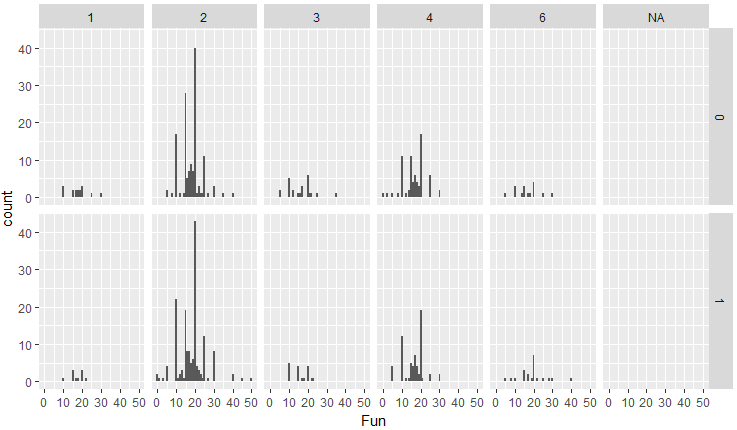 これもあまり男女で違いはないように見えます。人種間では標本数が違いすぎてなんとも言えません。
これもあまり男女で違いはないように見えます。人種間では標本数が違いすぎてなんとも言えません。
次に、野心:Ambitiousについて、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,amb1_1c) %>% summarise(Ambitious=mean(amb1_1c)) %>% ggplot(aes(Ambitious)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
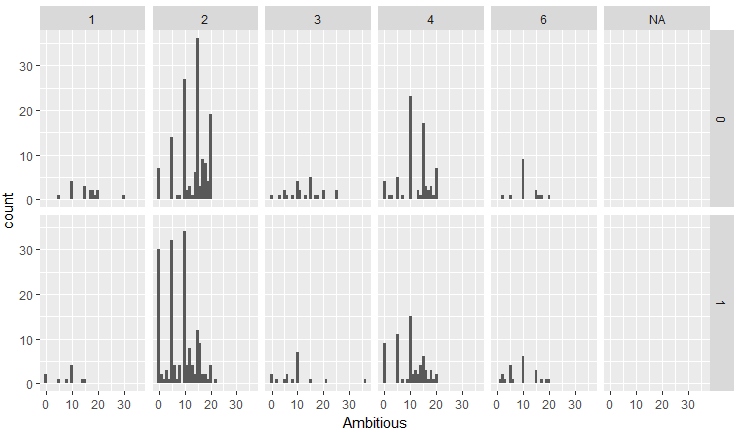 全体的に女性は男性の野心を重要視するようです。
全体的に女性は男性の野心を重要視するようです。
次に、共通の興味・趣味(shared_interests/hobbies)について、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,shar1_1c) %>% summarise(shared_interests=mean(shar1_1c)) %>% ggplot(aes(shared_interests)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
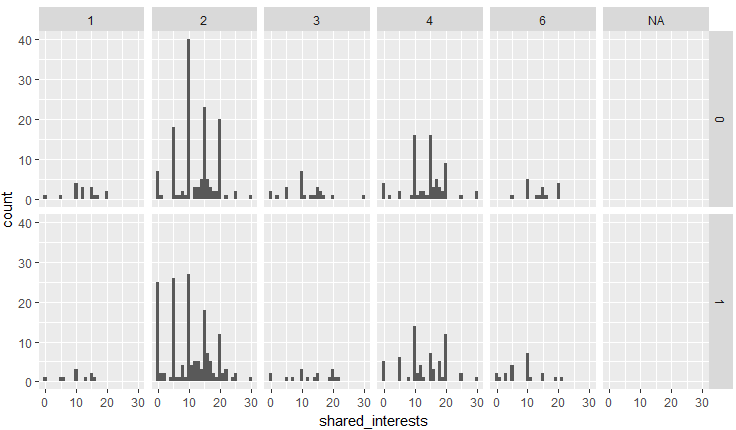 共通の興味や趣味に関しては男女差は見られず、ヨーロッパ人よりアジア人の方が重要視するといえそうです。
共通の興味や趣味に関しては男女差は見られず、ヨーロッパ人よりアジア人の方が重要視するといえそうです。
次にexpnum(20人会った中で、何人があなたとのデートに興味を持ったと予想するか)について、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,expnum) %>% summarise(Expnum=mean(expnum)) %>% ggplot(aes(Expnum)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
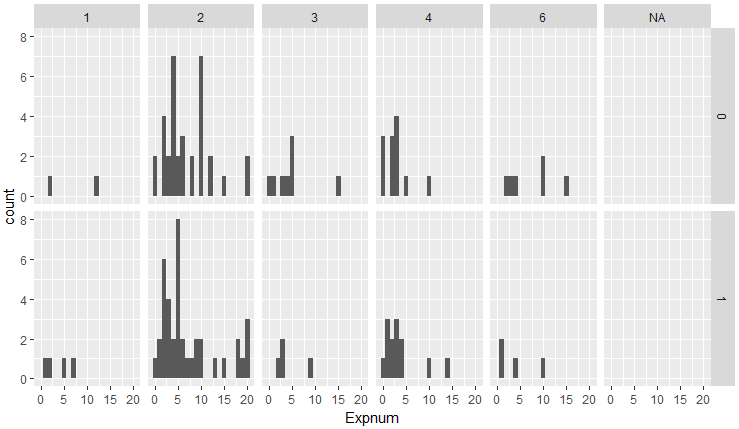 1,3,6はサンプル数が少なくて何とも言えないものの、4のアジア人は、2のヨーロッパ人を比較して、自分に興味を持ってくれたであろう相手の人数を少なく見積もる傾向があると言えるかもしれません(今回の被験者がヨーロッパ人主体なのであくまで可能ですが)
1,3,6はサンプル数が少なくて何とも言えないものの、4のアジア人は、2のヨーロッパ人を比較して、自分に興味を持ってくれたであろう相手の人数を少なく見積もる傾向があると言えるかもしれません(今回の被験者がヨーロッパ人主体なのであくまで可能ですが)
次にimprace(デートする相手が自分と同じ人種・民族であることが重要かを0-10で評価)について、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,imprace) %>% summarise(Imprace=mean(imprace)) %>% ggplot(aes(Imprace)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
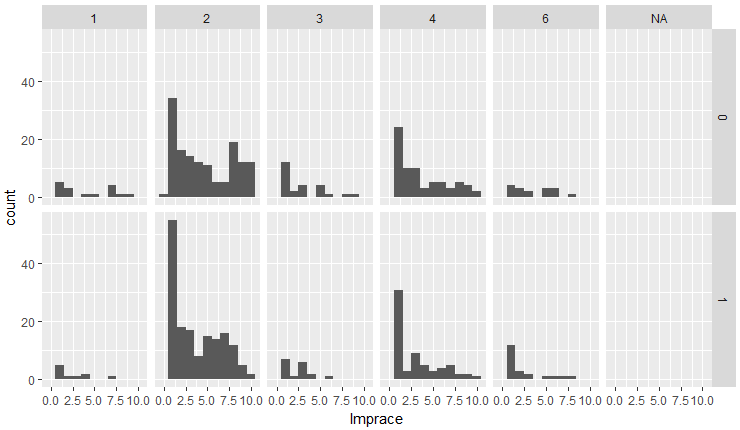 女性の方が、ほぼどの人種でも(3は微妙ですが)デートする相手が自分と同じ人種・民族であることが重要と思っている人が多いようです。
女性の方が、ほぼどの人種でも(3は微妙ですが)デートする相手が自分と同じ人種・民族であることが重要と思っている人が多いようです。
次にimprelig(デートする相手が自分と同じ宗教を信じることが重要かを1-10で評価)について、人種・性別ごとに、どれくらい異性のこの項目を重視するかを可視化してみます。
d %>% group_by(iid,race,gender,imprelig) %>% summarise(Imprelig=mean(imprelig)) %>% ggplot(aes(Imprelig)) + geom_histogram(binwidth = 1) + facet_grid(gender ~ race)
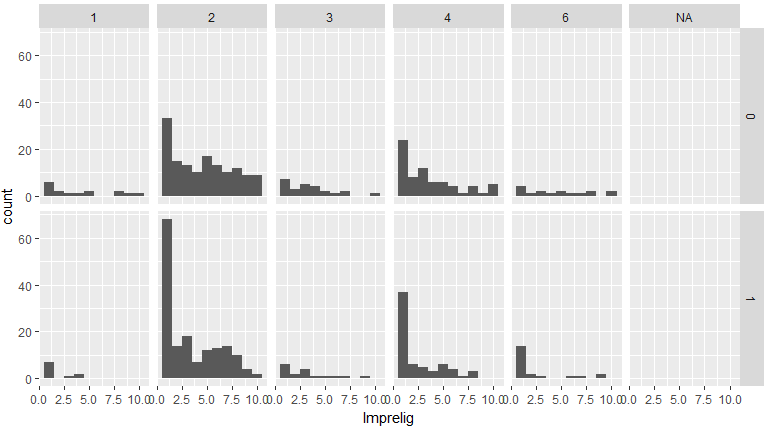 どの人種も男性は、相手の宗教が自分と同じでなくてもよいと考える人が多いようです。
どの人種も男性は、相手の宗教が自分と同じでなくてもよいと考える人が多いようです。
とりあえず、以上。
鈴木瑞人
東京大学大学院新領域創成科学研究科 メディカル情報生命専攻 博士課程
東京大学機械学習勉強会 代表
NPO法人Bizjapan