2017.10.16 Mon |
Pythonによるデータ可視化

今回は、Pythonによるデータ可視化を行っていきます。
Pythonでのデータ可視化機能は、Pandasライブラリ、Matplotlibライブラリ、seabornライブラリ、Bokehライブラリ、Plotlyライブラリなどが担当しています。
1-2年前までは、データ可視化はRが圧倒的に強かったのですが、最近Pythonの追い上げが激しいのでPythonによる可視化には要注目です。
使用するデータセットは、KaggleのHumanResourceAnalyticsのデータです。
 https://www.kaggle.com/ludobenistant/hr-analytics
https://www.kaggle.com/ludobenistant/hr-analytics
ライブラリは、Pandas、Matplotlib、Seabornを使用します。
まずは使用するモジュールのインポートから。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
出力がjupyter notebook上で表示されるようにマジックコマンドを実行します。
%matplotlib inline
ちなみにですが、ここでのダブルクオテーションはなぜか半角で入力しても公開したときに全角になるので、コピペして実行する方はその点留意ください。
まずデータを読み込みます。
d = pd.read_csv(“HR_comma_sep.csv”)
さて早速可視化していきましょう。
まずは一次元の質的変数を可視化します。
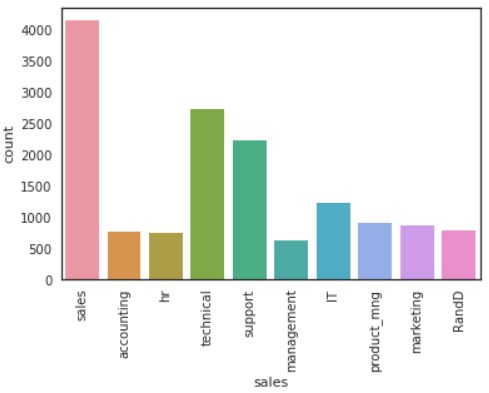
各従業員がどこに所属しているかを表すsales変数を可視化します。
g = sns.countplot(d[“sales”])
plt.setp(g.get_xticklabels(), rotation=90)
plt.show()
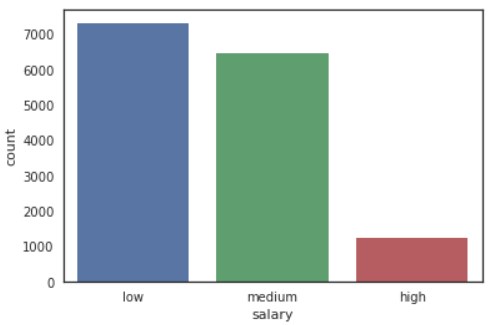
もう一つ、給与水準を表す変数、salaryを可視化します。
g = sns.countplot(dataset[“salary”])
plt.show()
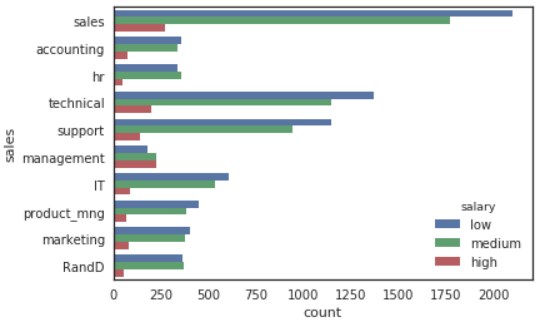
 次に二次元の質的変数の可視化を行います。
次に二次元の質的変数の可視化を行います。
使用する変数は、sales変数とsalary変数です。
sns.countplot(y=”sales”, hue=”salary”, data=d)
plt.show()
次は一次元の量的変数の可視化をしていきます。
従業員の満足度を表すsatisfaction_levelという変数を可視化します。
sns.distplot(d[“satisfaction_level”], kde=False)
plt.show()
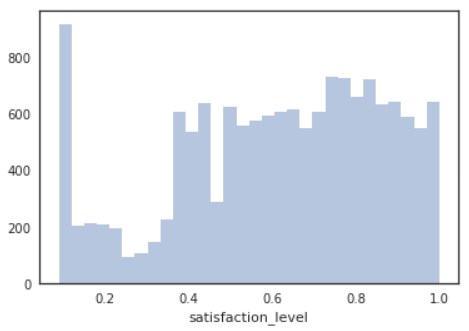 ちなみに、kde=Falseをいれない(デフォルトではkde=True)と以下のようになります。
ちなみに、kde=Falseをいれない(デフォルトではkde=True)と以下のようになります。
sns.distplot(d[“satisfaction_level”])
plt.show()
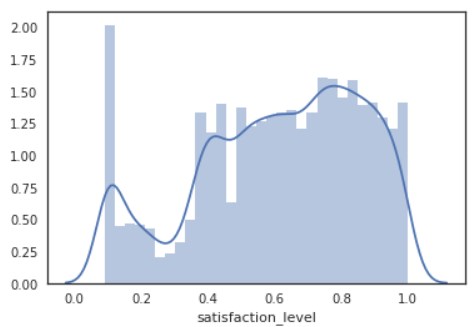 個人的にこの青線の密度曲線があまり好きではないので、普段はkde=Falseで実行しています。
個人的にこの青線の密度曲線があまり好きではないので、普段はkde=Falseで実行しています。
もう一つ量的変数の可視化をします。
sns.distplot(d[“last_evaluation”], kde=False)
plt.show()
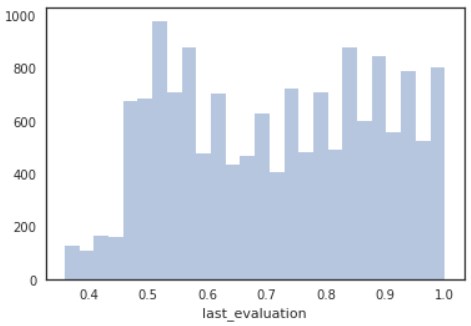 さて、二つ量的変数が出てきたところで、二次元の量的変数の可視化を行います。
さて、二つ量的変数が出てきたところで、二次元の量的変数の可視化を行います。
sns.jointplot(x=”satisfaction_level”, y=”last_evaluation”, data=d)
plt.show()
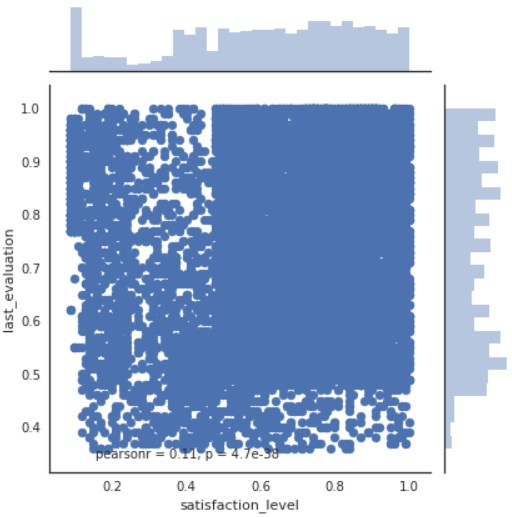 もしこのplotに質的変数で色付けしたいとします。その場合、sns.jointplot関数では僕が調べた限りできなさそう(color引数が質的変数を受け取ってくれない)なので、sns.lmplot関数を使用します。
もしこのplotに質的変数で色付けしたいとします。その場合、sns.jointplot関数では僕が調べた限りできなさそう(color引数が質的変数を受け取ってくれない)なので、sns.lmplot関数を使用します。
sns.lmplot(x=”satisfaction_level”, y=”last_evaluation”, data=d,fit_reg=False,hue=’left’)
plt.show()
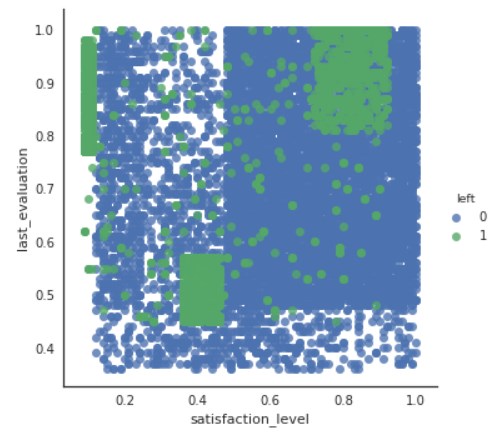 次に質的変数一つと量的変数一つの可視化を行います。
次に質的変数一つと量的変数一つの可視化を行います。
sns.boxplot(x=”salary”, y=”satisfaction_level”, data=d)
plt.show()
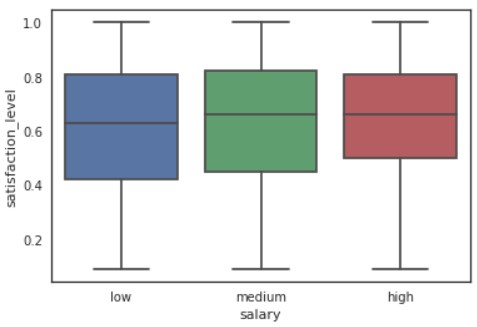 次に、散布図行列を出力してみます。
次に、散布図行列を出力してみます。
sns.pairplot(d)

ちょっと出力が多すぎて図が潰れてしまったので、変数を1列目から4列目だけ可視化します。
sns.pairplot(d.iloc[:,0:4])
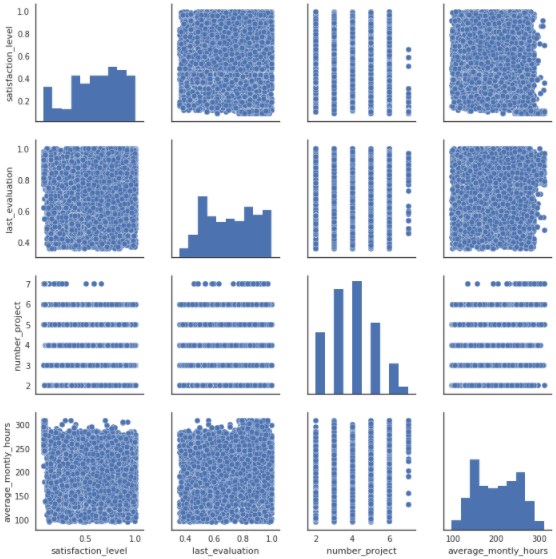
これに三列目の変数で色付けします。
sns.pairplot(d.iloc[:,0:4], hue=”number_project”)
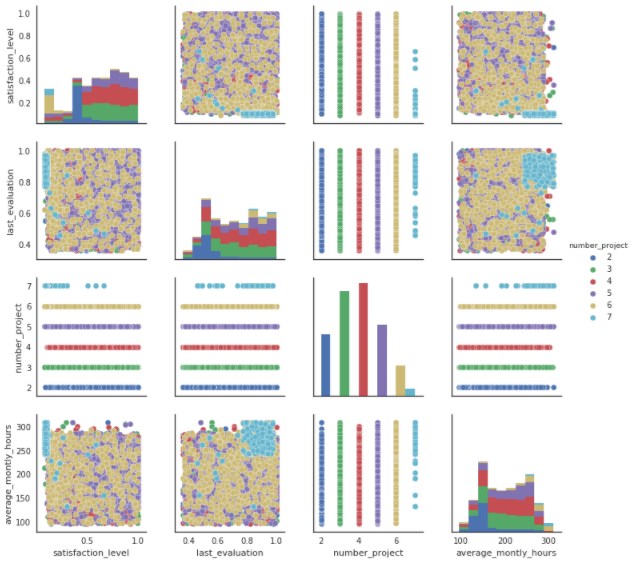
というようにPythonでもいろいろできるのがお分かりいただけたかなと思います。
ただ、Rのggplot2パッケージに慣れていると、いろいろ制限やできないことがあることに気づくかと思います。
たとえば、最後のプロットで、透明度を指定できなかったり、データにしていない変数に関しては色付けの変数として使用できなかったりします。また二次元の質的変数の可視化の選択肢が少ないです。
ただ、Rでの可視化を知らない人にとっては、こんなこともできるのかと感心することも多いかと思います。
ただ、個人的には、データ可視化はPythonよりRでやったほうが小回りが利くと思うので、Rでの可視化をお勧めします。
今回はここまで。
鈴木瑞人
東京大学大学院新領域創成科学研究科 メディカル情報生命専攻 博士課程
NPO法人Bizjapan テクノロジー部門BizXチームリーダー