2016.10.04 Tue |
テキスト解析の実践2
以前ご紹介したテキスト解析ですが、実際には何に使えるでしょうか?
以前の例にご紹介したような、2つの商品のレビューの比較や、2つの企業のサービスの比較、企業に応募してきた人材を選ぶときの参考資料として、使えそうですね。他にどんなことに使えるでしょうか?
私事になりますが、個人的に、毎週数百本出版される科学論文(医学・生物系)の内容をテキストマイニングを用いて、より効率的に把握できるようになりたいなと思っています。今回はそれをやってみましょう。
今回は以前ご紹介したUserLocalを用いてみたいと思います。
今回内容を把握したい論文は、OpenAccessのJournal, NatureCommunicationsから取ってきましょう。
リンクはここになります。
http://www.nature.com/ncomms/
Nature CommunicationsはNature Publishing Groupが提供するOpen AccessのJournalです。普通アカデミックな論文は、出版社と契約して高額な購読料を払わないと読めないのですが、最近はこういった無料で誰もが読めるJournalが増えてきています。
さて、今回は、たまたまNature ComunicationsのHome画面にあった、
”A plasma membrane microdomain compartmentalizes ephrin-generated cAMP signals to prune developing retinal axon arbors”
http://www.nature.com/articles/ncomms12896
を解析してみましょう。
このAbstractからMethodsまでをコピーして、UserLocalのテキストボックスに貼り付けます。
ちなみに、文字数をカウントしたら、スペースなしで46420個ありました。。1つの論文でこれですからね。。1つの単語が平均5文字として、8千語ある。。
たとえば癌の分野なら、この規模の論文が年に10万本くらい出版されます。。情報の洪水ですね。人がこんなにたくさんの情報を処理することはできないので、今後はAIに頼っていく必要があります。。。
こんな感じではりつけて、下の緑のボタン”テキストマイニングする”を押して、解析を実行します。

まず初めに出てくるのは、共起ネットワークです。
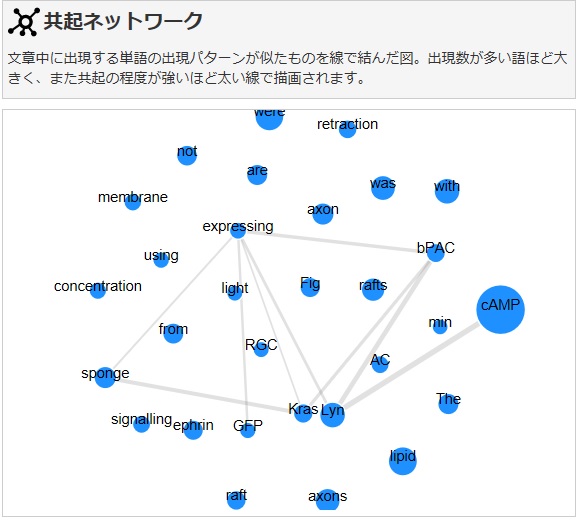
全部同じ色なのと、あまり線が出てきてないことから、英語において、名詞・動詞・形容詞の区別はできず、単語間の関係もあまりとらえられないようですね。
しかし、大体どんな単語が出てきて、それぞれのどんな関係があるかわかりました。
次に出てくるのは、ワードクラウドです。
単語の出現頻度が多いほど大きな文字として出力されます。

cAMP,Lyn,ephrin,bPACなどをあらかじめ調べておかないとこの論文は読めなそうですね。。
次に単語出現頻度です。
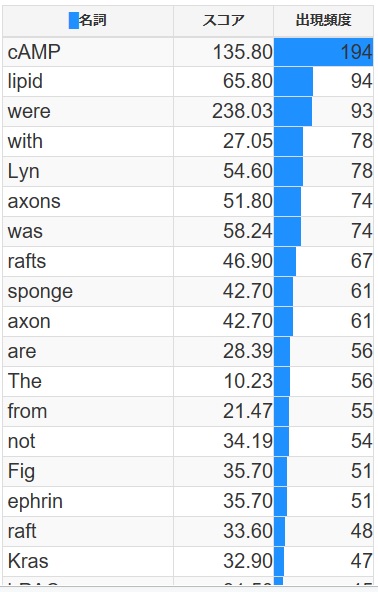
cAMPが圧倒的に多いですね。基本的に、wordcloudの生データですね。
特に新しい情報はないです。
UserLocalが日本語用なので、英語を名詞・動詞・形容詞に識別できないのが残念ですね。
本当は別のツールを使うべきなのでしょうか今回はこのまま突き進んでみます。
今度は2つの文章の比較を行ってます。二つの文章比較ならもっと有意義な内容が出てくるかもしれません!
比較するのは、今回の論文内容と、この論文の引用文献のAbstract(要約)です。ココがポイントです。今回の論内容の新規性を洗い出すならこの情報の選び方が一番良いと思います。
引用文献のAbstractは手作業で、Pubmedから取ってきます。
まず出てくるのは、入れた文章です。

次に出てくるのは、
wordcloudです。

参照論文では、flotllinが重要なようでしたが、今回の新しい論文では、あまり出てきていませんね。あと、cav。今回の論文では、この二つが重要なのかもしれません。
次は特徴語マップです。
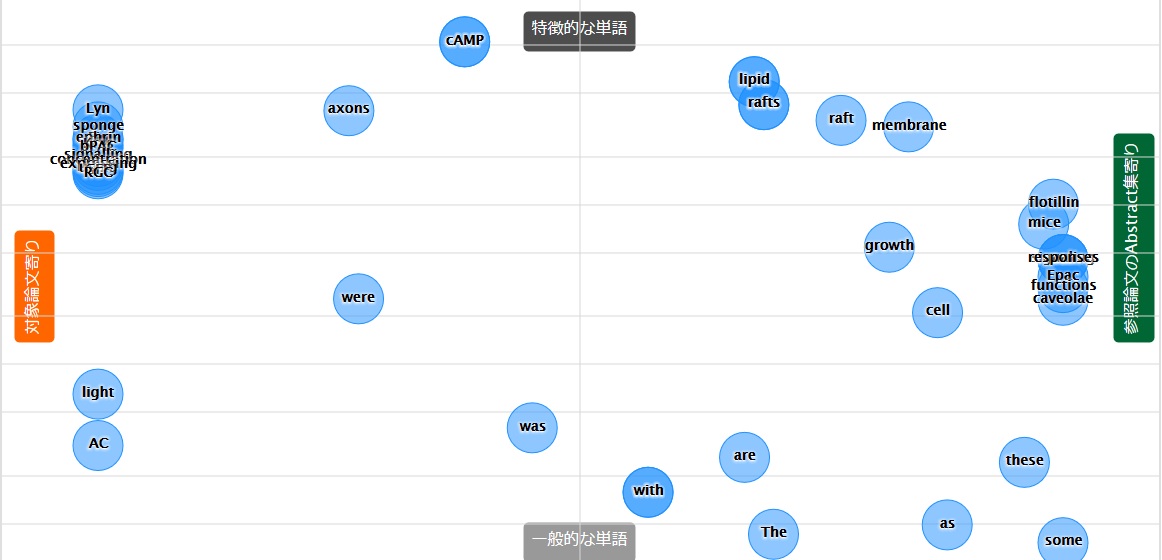
右と左の両端に密集している単語にカーソルを合わせて一つ一つ見ていくと、今までの論文と比べて今回の論文がどう違っているかの仮説が立てられます。仮説をもって新しい論文に臨むと、理解度が高くなるかもしれません。
最後は単語出現頻度の比較です。
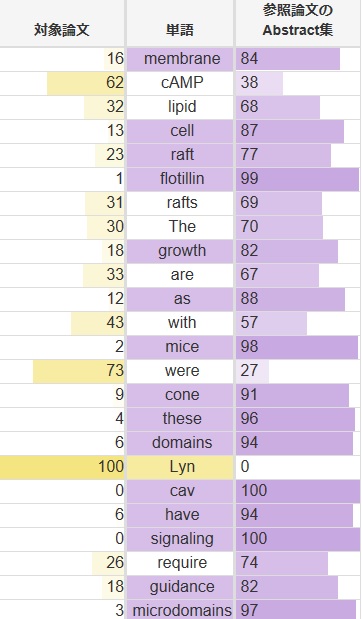
今まで共起ネット―ワークやwordcloud,特徴語マップで表されていたことが、より定量的に理解できるようになりましたね。
特に顕著なのは、今までは、flotillinとcavいう単語の出現頻度が高かったのに対して、今回の論文では、Lynという単語が出現し、かなり使われています。この単語がkeyなのでしょう。
今回は英語には非対応のUserLocalというテキストマイニングのツールを用い、参照文献67本あるうちの15本しか使わなかったのですが、それでもそれっぽい結果がでました。
英語対応のWatsonAPIなどを使い、全参照文献のAbstract(もしくは本文)を使ったら、より詳細に、参照文献から、新しく出た論文の新規性がつかめるようになるのではないかと思います。
今後いろいろ試してみたいと思います。
何かご質問ありましたら以下までメールでお願いします。
machine.learning.r@gmail.com
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程1年
一般社団法人Bizapan
東京大学機械学習勉強会