2016.10.04 Tue |
テキスト解析の実践1
以前テキスト解析(テキストマイニング)についてご紹介しましたが、今回は実際にどのようなものか使ってみたいと思います。
テキストマイニングのツールとして、RやWatsonAPI,KHCoderなどいろいろなものがありますが、今回は、何も環境設定しなくて使える、UserLocalのwebブラウザ上でのテキストマイニングの結果を見てみましょう。
URLは、ここです。
http://textmining.userlocal.jp/
このテキストボックスの中に解析したい文章を貼り付けて、下の緑のボタン「テキストマイニングする」を押せば解析できます。
まず、右上にある、サンプル1:夏目漱石「吾輩は猫である」を見てみましょう。
これは、おそらく、「吾輩は猫である」の一部または、すべての本文をいれたものと思われます。
3つの出力結果が出てきます。
まずは共起ネットワークです。
これはどの単語とどの単語が連続して出現したかを集計し可視化しています。
このページの説明だと、
文章中に出現する単語の出現パターンが似たものを線で結んだ図。出現数が多い語ほど大きく、また共起の程度が強いほど太い線で描画されます。
と書かれています。
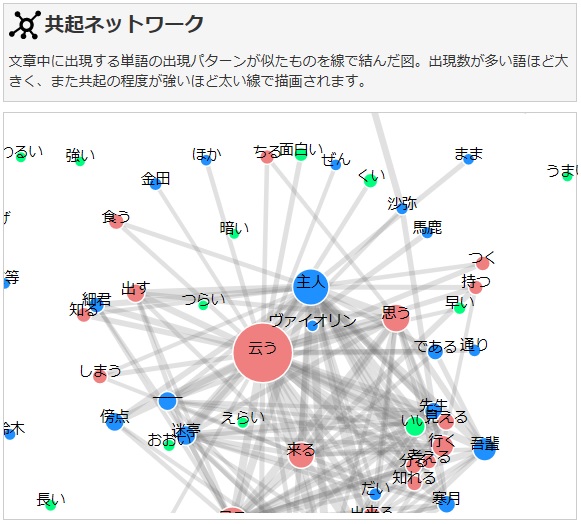
「吾輩は猫である」を読んだことがある人からしたら、たしかにそんな感じかも。。といった感じですね。
次は、ワードクラウドです。
出現頻度が高い単語ほど大きく表示されています。
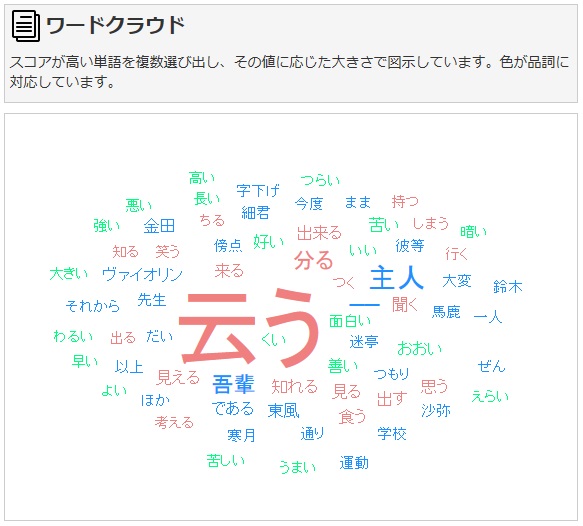
基本的に、共起ネットワークの線がないバージョンですね。
どんな単語が出てきたかはぱっと見でわかりますね。
次に、単語の出現頻度を集計・棒グラフとして可視化したものです。
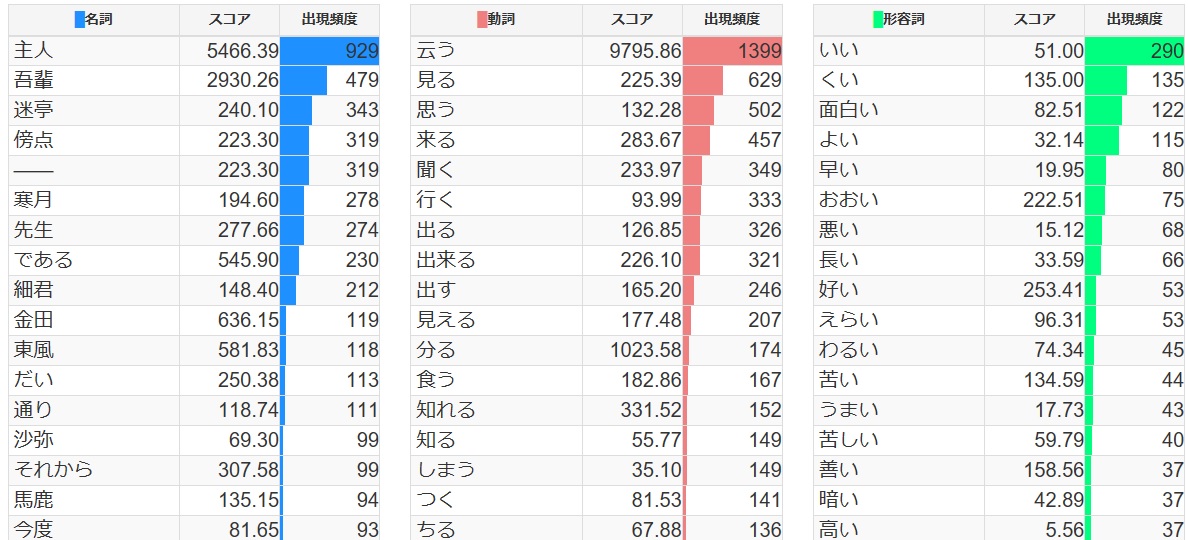
名詞・動詞・形容詞、の順で、各単語の出現頻度が出てきていますね。
これを見ても大体のテキストの内容が想像できますね。
では次にサンプル2:掃除機の高評価・低評価レビュー比較解析、を見てみましょう。
先ほどが一つの文章(吾輩は猫である)の解析であったのに対して、今回は、二つの文章の解析です。
主目的は、二つの文章の比較になります。
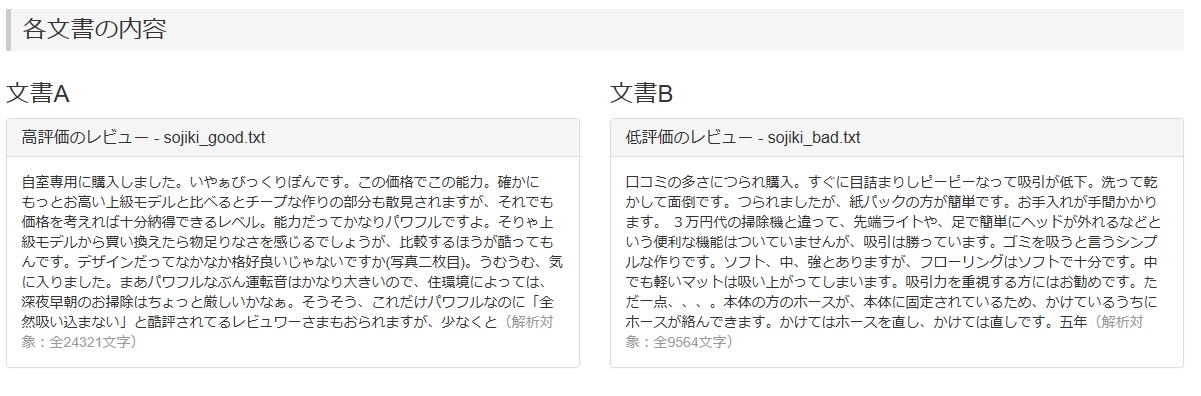
まず出てくるのは、解析をかけた二つの文章の内容です。
次に出てくるのは、
ワードクラウドです。
2つの文章それぞれについて出てきます。
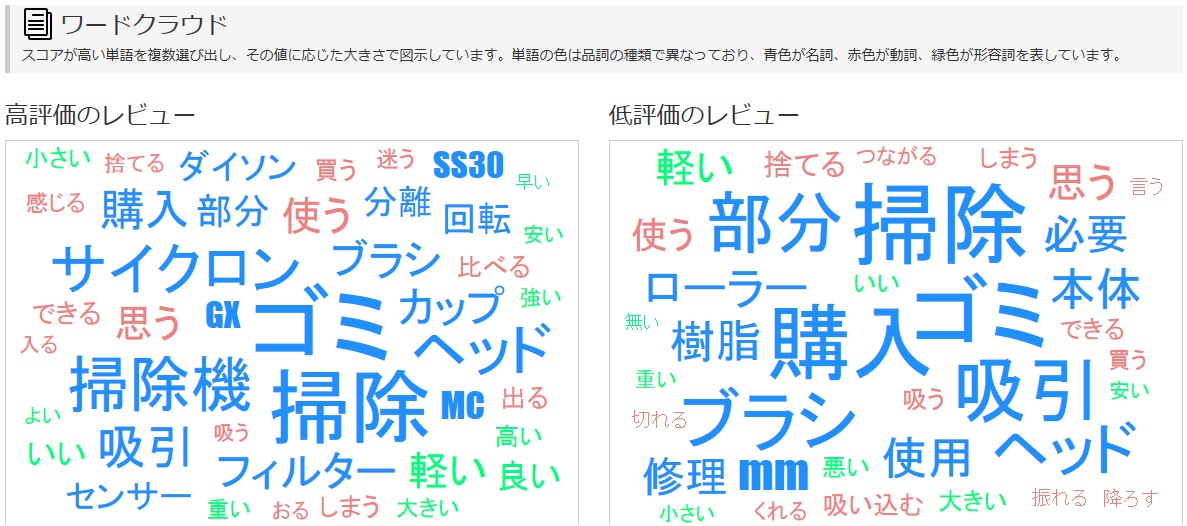
このワードクラウドを比較するだけでは、今回の場合は二つの文章の違いはそれほどわかりませんね。。
次に出てくるのは、
特徴語マップです。
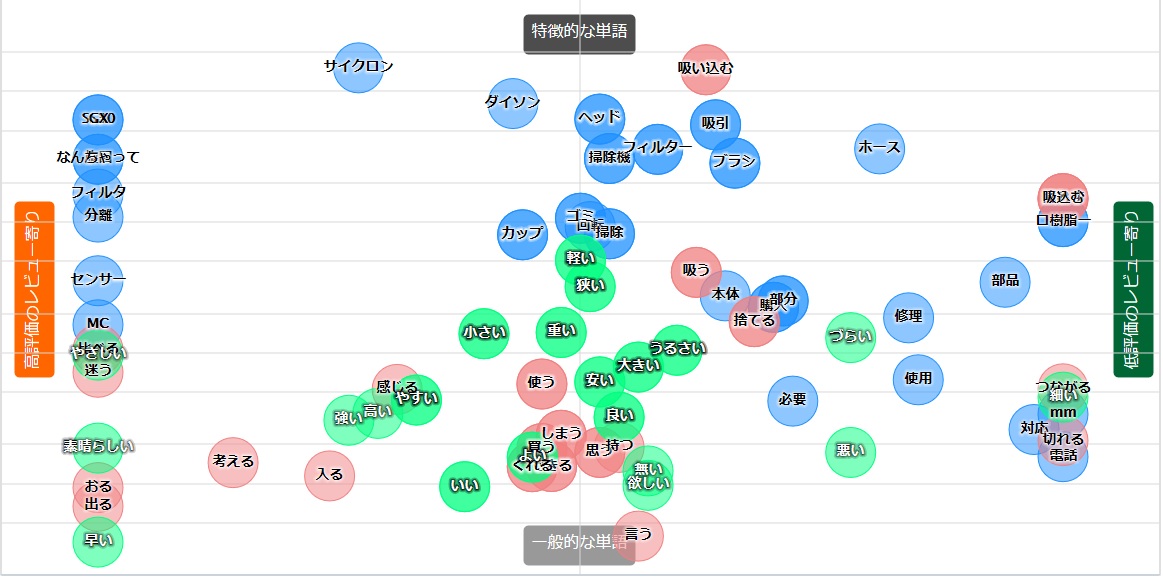
この特徴語マップの説明は、
解析対象の文書に現れる単語がどちらの文書により多く出現するか、またその単語が文書においてどれだけ特徴的であるかを2次元でマッピングした図です。単語が左寄りになっているほど文書Aにより多く現れることを、右寄りになっているほど文書Bにより多く現れることを意味しています。また、単語が上寄りになっているほどこの文書で特徴的な単語であることを、下寄りになっているほどどのような種類の文書にも出現するような一般的な単語であることを意味しています。
となっています。
二つの文章の違いは、特徴語マップに現れる各単語が右寄りか左寄りかで、わかりますね。
右の低評価レビュー寄りだと、”悪い”、”切れる電話”、”うるさい”などと言ったマイナスの意味を持つ単語が現れています。
次に出てくるのは、
ネガポジマップです。
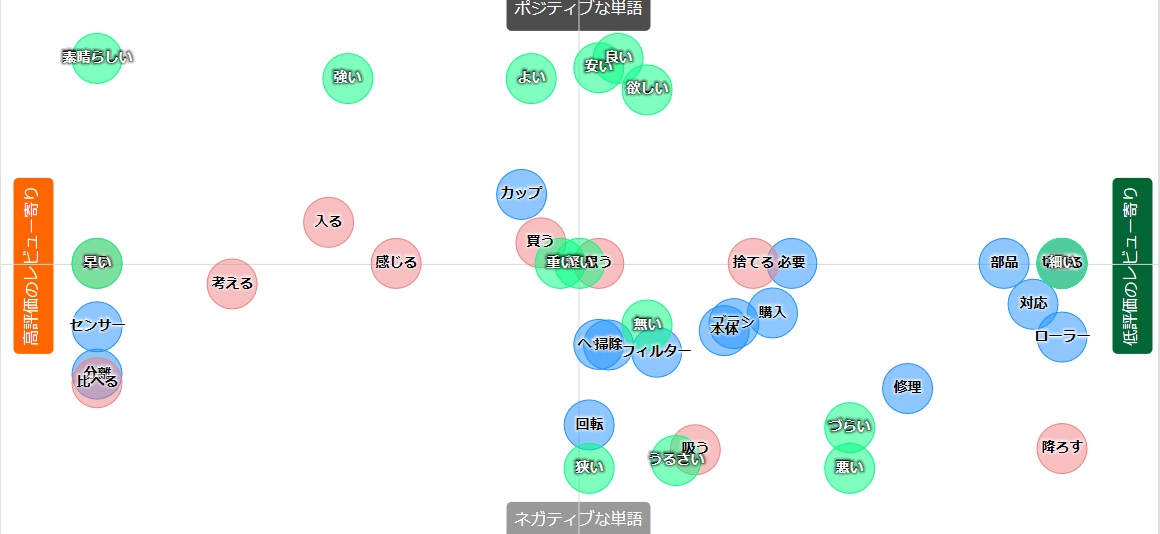
このページの説明だと、
解析対象の文書に現れる単語がどちらの文書により多く出現するか、またその単語の意味がどれだけポジティブ・ネガティブであるかを2次元でマッピングした図です。単語が左寄りになっているほど文書Aにより多く現れることを、右寄りになっているほど文書Bにより多く現れることを意味しています。また、単語が上寄りになっているほどポジティブな単語であることを、下寄りになっているほどネガティブな単語であることを意味しています。
となっています。
低評価なレビューの方が、ネガティブの単語が多く、高評価なレビューの方が、高評価なレビューが多いことが分かりますね。
二つの文章中にどちらの文章がポジティブな単語が多く、ネガティブな単語が多いかが分かります。
次に出てくるのは、単語の出現率です。
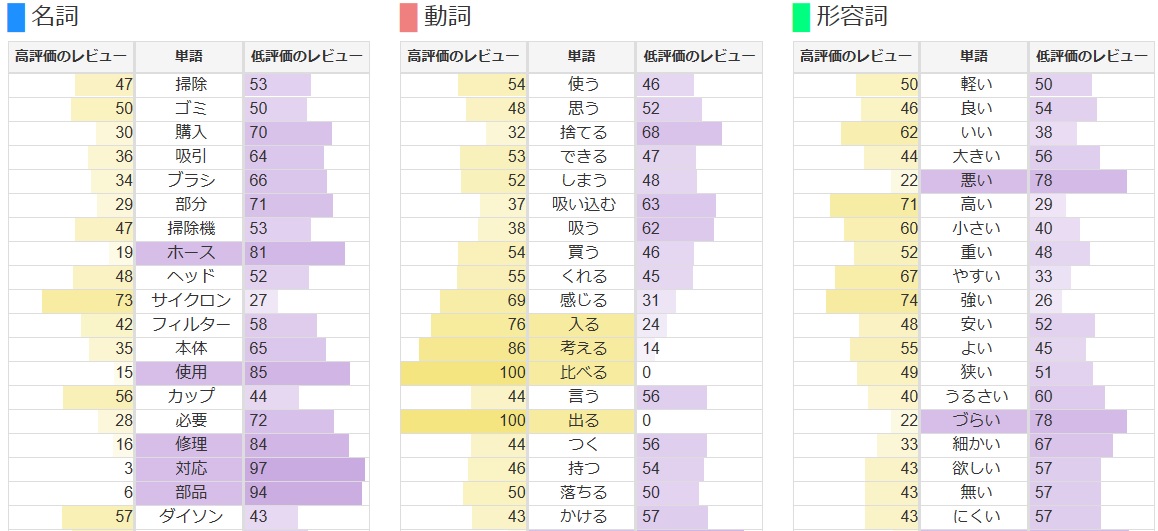
名詞・動詞・形容詞のそれぞれについて、各単語の出現頻度の比較がなされています。
二つの文章をまじめに比較して何かを導き出そうとしているときには、役立ちそうですね。
今回はUserLocalさんのテキストマイニング例をご紹介させていただきました。
とりあえず、テキスト解析でどんなことが出来そうかの雰囲気をつかめたかと思います。
これをどのような文章に対して適用し、実際のビジネス・研究に役立てるのかについては、新しい発想と工夫が必要です。
それについてはまた今度書けたらと思います。
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程1年
一般社団法人Bizjapan
東京大学機械学習勉強会