2016.10.04 Tue |
まだExcelで消耗してるの?ver2
みなさん、今日もExcel使っていますか?
GUIですごく使いやすいですね。
統計解析もHADなどのアドオン使えば何とかできますね。
そんな便利なExcelですが、Rの方がずっと便利でできることも圧倒的に多いですので、乗り換えをお勧めします。
もしくはどちらも使えるようになりましょう。
さて、今日は、Rを用いた空間統計をご紹介したいと思います。
空間統計といっても初歩的なもので、地図上に値をヒートマップ(値の大きさを色の濃さで表す)で表したり、値の大きさを国や州の面積に反映するものです。
まずは、mapsというRのパッケージをご紹介します。
Rをすでにダウンロードインストールしている方は以下のコマンドを順にコピペしていけば同じ結果を再現できるはずです。
それでは参りましょう!
まず、mapsパッケージをダウンロードインストールします。
install.packages(“maps”,dependencies=T)
次にパケージをメモリにロードします。
library(maps)
それではまず世界地図を出力してみましょう。
map(‘world’)

それでは、次に、アメリカを出力してみましょう!
map(‘usa’)

次はアメリカの地図の一部に大気中のオゾンの濃度の計測値を出力してみましょう!
まずオゾンのデータを見てみましょう。
data(ozone)
head(ozone)
str(ozone)

xが経度(東経をプラス、西経をマイナス)、yが緯度(北緯がプラス、南緯がマイナス)で、medianがオゾン濃度です。
まずは、今回のデータの範囲でのアメリカの地図を描画します。
map(“state”, xlim = range(ozone$x), ylim = range(ozone$y))

次に、オゾン濃度をプロットします。
text(ozone$x, ozone$y, ozone$median)
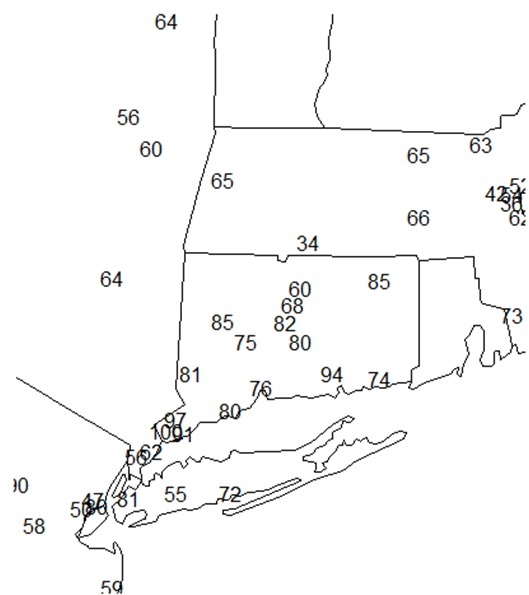
box()
で外枠を囲うとそれっぽくなりますね。
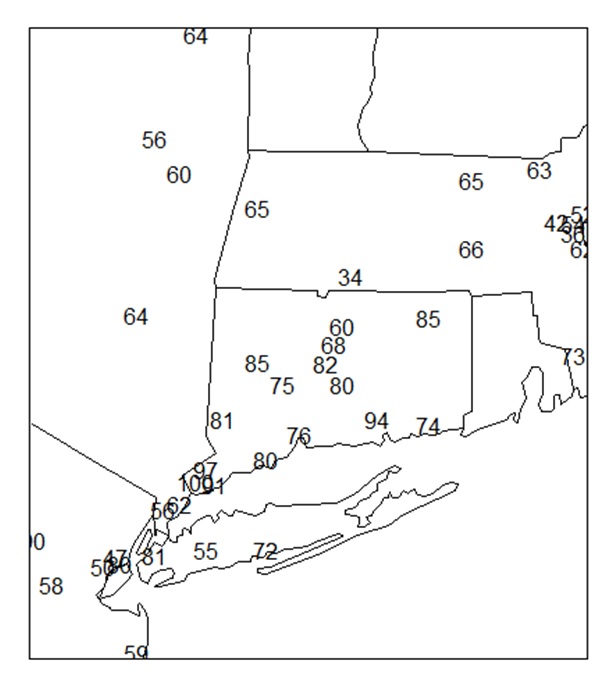
あまりきれいなプロットではありませんが、このように数値を地図上にプロットする可視化もあることはぜひとも知っておいてください。
きれいなプロットは次でやります。
次にアメリカの郡区分(county:state(州)の下位の行政区画)の失業率をヒートマップで可視化したいと思います。
mapprojを使うのでロードしておいて下さい。(mapsパッケージを入れたときに同時にダウンロードされているはずですのでinstall.packagesコマンドは必要ありません。)
library(mapproj)
使うのは、2009年の失業率のデータとFIPS county codesです。
アメリカでは、州(state)と郡(county)に番号が割り振られています。こんな感じです。

失業率のデータは、unempに入っており、
郡のfipsのデータは、county.fipsに入っています。
まずはこれらのデータをロードして中身を見てみましょう。
data(unemp)
data(county.fips)
head(unemp)
str(unemp)
head(county.fips)
str(county.fips)

このfipsコードを使って、各郡にunempの値をプロットしていくわけですね。しかも、その値の大きさを色の濃さで表現します。
さあ、続けましょう。
#color bucketsを定義
colors = c(“#F1EEF6”, “#D4B9DA”, “#C994C7”, “#DF65B0”, “#DD1C77”, “#980043”)
unemp$colorBuckets <- as.numeric(cut(unemp$unemp, c(0, 2, 4, 6, 8, 10, 100)))
leg.txt <- c(“<2%”, “2-4%”, “4-6%”, “6-8%”, “8-10%”, “>10%”)
#州と郡でマッチングさせることにより地図の定義を調整する。
cnty.fips <- county.fips$fips[match(map(“county”, plot=FALSE)$names,
county.fips$polyname)]
colorsmatched <- unemp$colorBuckets [match(cnty.fips, unemp$fips)]
# mapを描画
map(“county”, col = colors[colorsmatched], fill = TRUE, resolution = 0,
lty = 0, projection = “polyconic”)

#州の境界線を白線表示
map(“state”, col = “white”, fill = FALSE, add = TRUE, lty = 1, lwd = 0.2, projection=”polyconic”)
#タイトルを入れる
title(“unemployment by county, 2009”)
#凡例を入れてどの色がどの数値を意味するかを明確にする。
legend(“topright”, leg.txt, horiz = TRUE, fill = colors)
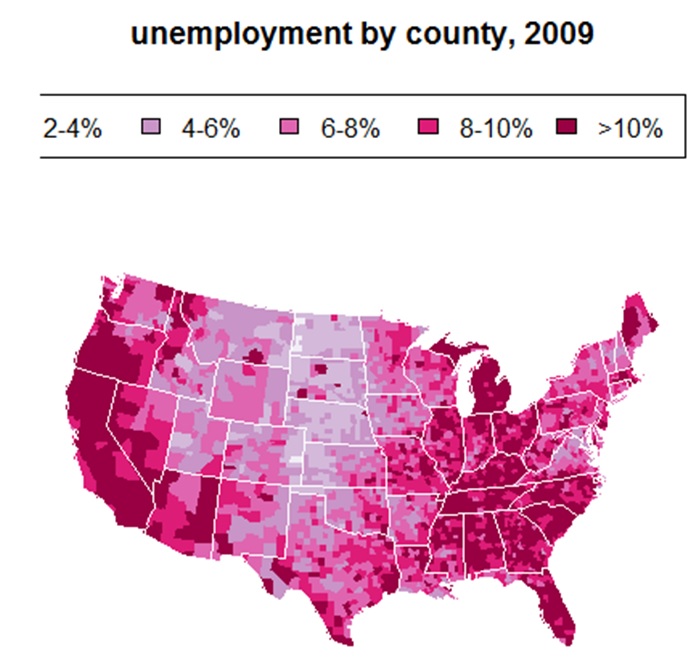
いい感じに出力できましたね。
もともとの失業率のデータは、
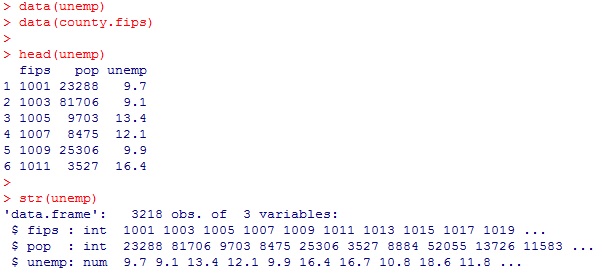
こんな感じの表データでした。
Excelだったらこれ止まりだったと思うのですが、Rだと上のようにきれいに可視化できました。
またさらにRの可能性に気づいてもらえたかなと思います。
今回はこの辺で。
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程1年
一般社団法人Bizjapan
東京大学機械学習勉強会