2016.11.14 Mon |
Google翻訳の精度検証

こんにちは!
突然ですが、Google翻訳が、NeuralNetworkを採用することで、翻訳精度が急激に上がりました。皆さんご存知でしたか?今まで、Google翻訳と言ったら、機械っぽいイメージを皆さんお持ちだったと思いますが、今回の改善によりかなり人っぽい翻訳ができるようになりました。
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
細かいことはよいのですが、どれくらいの精度になったのか、恐縮ながらGoogle翻訳先生に練習問題を与えてテストしてみたいと思います。
まずは、せっかくなので、Google翻訳の新しい仕組みについての論文のアブストラクト(要約)を、使いたいと思います。https://arxiv.org/abs/1609.08144
それでは、一文一文を検証していきましょう。
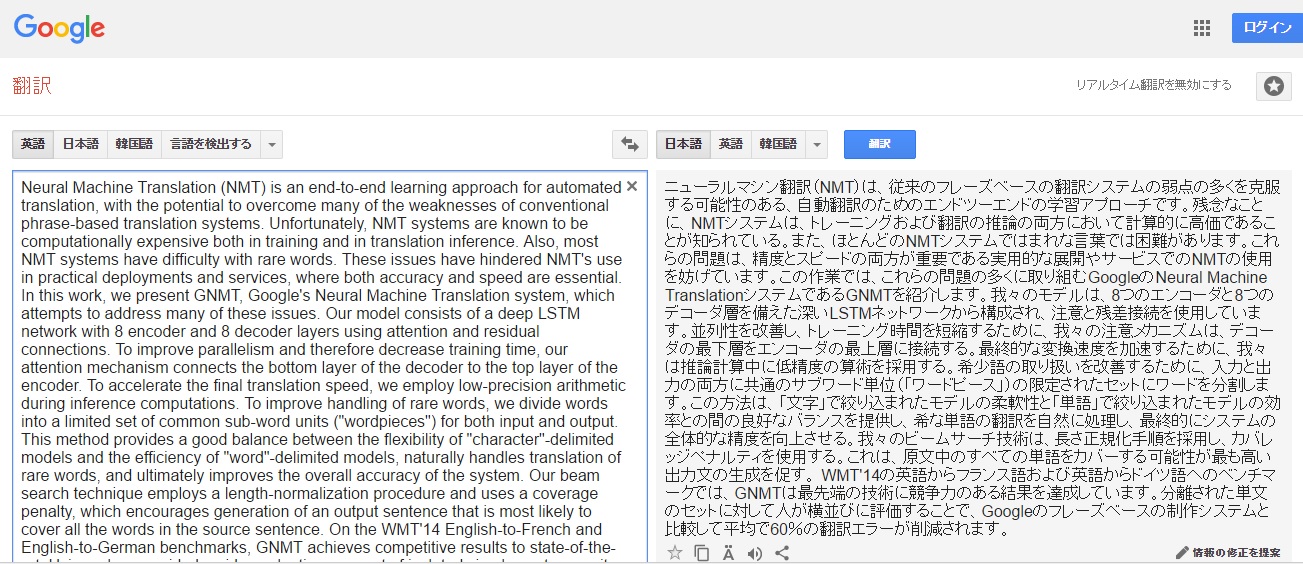
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems.
ニューラルマシン翻訳(NMT)は、従来のフレーズベースの翻訳システムの弱点の多くを克服する可能性のある、自動翻訳のためのエンドツーエンドの学習アプローチです。
満点でいいかなと思います。
Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference.
残念なことに、NMTシステムは、トレーニングおよび翻訳の推論の両方において計算的に高価であることが知られている。
trainingが学習と訳されていた方がいい気がするものの、ほぼ満点。
Also, most NMT systems have difficulty with rare words. These issues have hindered NMT’s use in practical deployments and services, where both accuracy and speed are essential.
また、ほとんどのNMTシステムではまれな言葉では困難があります。これらの問題は、精度とスピードの両方が重要である実用的な展開やサービスでのNMTの使用を妨げています。
”困難があります”という表現は多少使わないかなという気がしますが、ほぼ満点です。
In this work, we present GNMT, Google’s Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections.
この作業では、これらの問題の多くに取り組むGoogleのNeural Machine TranslationシステムであるGNMTを紹介します。我々のモデルは、8つのエンコーダと8つのデコーダ層を備えた深いLSTMネットワークから構成され、注意と残差接続を使用しています。
workは、この場合、作業より、研究の方がよいでしょう。attempts to addressの部分ももう少しいい訳がありそうですが、全体として8割方問題ないでしょう。それより、”デコーダ層”のように絶妙にカタカナごと漢字に変換したり”GoogleのNeural Machine Translationシステム”のように英語をそのまま残す基準も、一般的な感覚とあっているかと思います。
To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations.
並列性を改善し、トレーニング時間を短縮するために、我々の注意メカニズムは、デコーダの最下層をエンコーダの最上層に接続する。最終的な変換速度を加速するために、我々は推論計算中に低精度の算術を採用する。
これは満点でしょう。
To improve handling of rare words, we divide words into a limited set of common sub-word units (“wordpieces”) for both input and output. This method provides a good balance between the flexibility of “character”-delimited models and the efficiency of “word”-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system.
希少語の取り扱いを改善するために、入力と出力の両方に共通のサブワード単位(「ワードピース」)の限定されたセットにワードを分割します。この方法は、「文字」で絞り込まれたモデルの柔軟性と「単語」で絞り込まれたモデルの効率との間の良好なバランスを提供し、希な単語の翻訳を自然に処理し、最終的にシステムの全体的な精度を向上させる。
最初、”です・ます”調であるのに対し、その次が”である”調になっています。あとは、”delimited”が”絞り込まれた”と訳されていますが、正しくは”区切られた”と訳された方がよさそうです。それでも、8割得点。
Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT’14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art.
我々のビームサーチ技術は、長さ正規化手順を採用し、カバレッジペナルティを使用する。これは、原文中のすべての単語をカバーする可能性が最も高い出力文の生成を促す。 WMT’14の英語からフランス語および英語からドイツ語へのベンチマークでは、GNMTは最先端の技術に競争力のある結果を達成しています。
満点かなと思います。whichの訳し方がしっかりできるあたり関心してしまいます。
Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google’s phrase-based production system.
分離された単文のセットに対して人が横並びに評価することで、Googleのフレーズベースの制作システムと比較して平均で60%の翻訳エラーが削減されます。
満点あげていいかなと思います。Using a human…とあるので、今までの機械だったら、”人のなになにを使うことで。。”と訳してしまいそうですが、そこも、しっかり訳せています。
全体を通して、訳出する単語の選択はもっと改良の余地があるとは思いますが、文法的に訳が難しいところを見事訳せているのが分かると思います。
全体の点数としては8割~9割はいくと思います。すごいですね。
試しにもう一つ、NatureCommunicationsの論文で試してみましょう。NatureCommunicationsは、NaturePublishingGroupが提供するオープンアクセスのジャーナルです。分野は、物理・地学・化学・生物など幅広く扱っています。
今回は、筆者が理解できる範囲の論文を選びたいと思います。
シロイヌナズナの論文があったので、それにします。
http://www.nature.com/articles/ncomms13412
今回もAbstractを翻訳して、内容を分割して検証していきます。
こんな感じです。では、参りましょう。
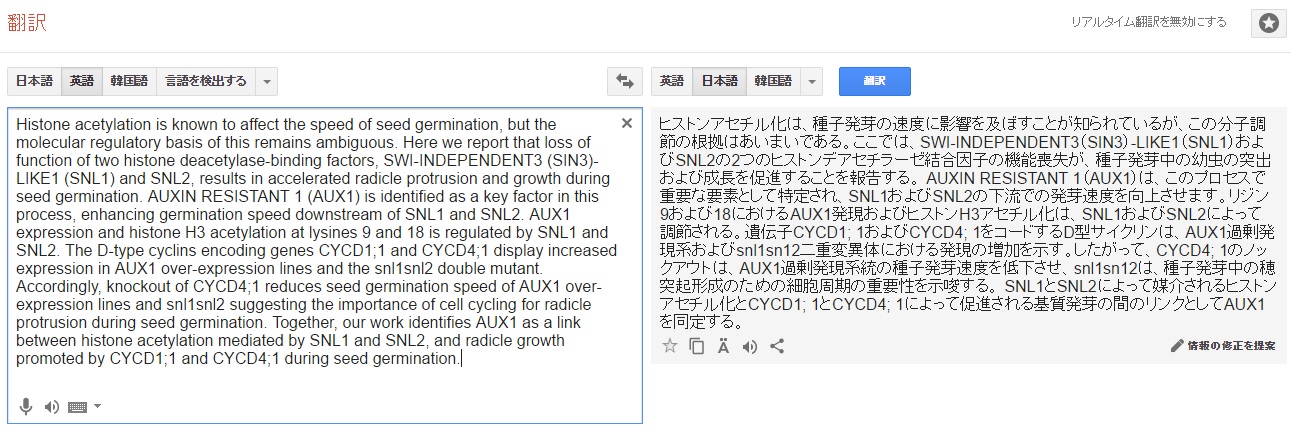
Histone acetylation is known to affect the speed of seed germination, but the molecular regulatory basis of this remains ambiguous. Here we report that loss of function of two histone deacetylase-binding factors, SWI-INDEPENDENT3 (SIN3)-LIKE1 (SNL1) and SNL2, results in accelerated radicle protrusion and growth during seed germination.
ヒストンアセチル化は、種子発芽の速度に影響を及ぼすことが知られているが、この分子調節の根拠はあいまいである。ここでは、SWI-INDEPENDENT3(SIN3)-LIKE1(SNL1)およびSNL2の2つのヒストンデアセチラーゼ結合因子の機能喪失が、種子発芽中の幼虫の突出および成長を促進することを報告する。
9割得点。radicleは、”幼虫”ではなく、”幼根”なので、誤り。webで調べてみても、幼虫という単語は出てこなかったので、この結果は、元データに”幼根”を扱うデータが少なかったことが原因と考えられます。こういう単純な単語ミスは、一般的な辞書を参照すればわかるので、珍しい単語に注意すれば見つけられそうですね。今までの、一般的な辞書に頼っていた機械的翻訳ではありえない間違いともいえます。
AUXIN RESISTANT 1 (AUX1) is identified as a key factor in this process, enhancing germination speed downstream of SNL1 and SNL2. AUX1 expression and histone H3 acetylation at lysines 9 and 18 is regulated by SNL1 and SNL2.
AUXIN RESISTANT 1(AUX1)は、このプロセスで重要な要素として特定され、SNL1およびSNL2の下流での発芽速度を向上させます。リジン9および18におけるAUX1発現およびヒストンH3アセチル化は、SNL1およびSNL2によって調節される。
7割得点。”下流での”の”の”はいらないですね。”の”があると意味が変わってきます。 lysines 9 and 18は、ヒストンH3へのアセチル化にのみ掛かり、AUX1 expressionには掛からないので、間違いですが、文法的には、両方に掛けてもよいところです。作者の文法ミスとは言えないですが、意味を知っていて初めて分かることなので、これは厳しいですね。
The D-type cyclins encoding genes CYCD1;1 and CYCD4;1 display increased expression in AUX1 over-expression lines and the snl1snl2 double mutant. Accordingly, knockout of CYCD4;1 reduces seed germination speed of AUX1 over-expression lines and snl1snl2 suggesting the importance of cell cycling for radicle protrusion during seed germination.
遺伝子CYCD1; 1およびCYCD4; 1をコードするD型サイクリンは、AUX1過剰発現系およびsnl1sn12二重変異体における発現の増加を示す。したがって、CYCD4; 1のノックアウトは、AUX1過剰発現系統の種子発芽速度を低下させ、snl1sn12は、種子発芽中の穂突起形成のための細胞周期の重要性を示唆する。
ここでも、レアな単語である、”radicle”は正しく訳せていない(”穂”でなく”幼根”が正解)ですが、全体としては、ほぼ満点です。”over-expression lines”を”過剰発現系”と訳したのはすごいなと感じました。
Together, our work identifies AUX1 as a link between histone acetylation mediated by SNL1 and SNL2, and radicle growth promoted by CYCD1;1 and CYCD4;1 during seed germination.
SNL1とSNL2によって媒介されるヒストンアセチル化とCYCD1; 1とCYCD4; 1によって促進される基質発芽の間のリンクとしてAUX1を同定する。
相変わらず、”radicle”が正しく訳せておらず、今回は”基質”という全く的外れな単語に訳されています。”our work identifies”など、論文独特の言い回しは、少し苦手なのかなという印象を持ちました。しかしこの全体としては、8-9割の得点を与えてよいと思います。
まとめますと、今回のNatureCommunicationsの論文のAbstractでも、8-9割方訳せているといえました。
おそらく、言語処理に詳しい方なら、このレベルで、英→日の翻訳ができるのは、少なくともあと数年先と予想していたと思います。それがあっという間に実現されてしまいました。
この事実は、我々、英語学習者にとって、今後の時間の使い方に大きく影響を与えるものです。極端な話、もう英語を勉強しないという選択肢もあり得るくらいです。もちろん、機械翻訳の間違いを見つけられるくらいの英語力は必要ですが、今後のアルゴリズムの進歩を考えると、どこまで学習するべきか、悩むところです。
少し話を変えますと、翻訳精度向上は、日本の研究・産業の発展に大きく寄与すると思います。基本的に、日本人は、英語が読めません。しかし、多くの分野の研究の最先端は英語の文書しかありません。また産業においても、最先端技術は英語のドキュメントしかないという事態はよくあります。この、言語のバリアがなくなることは、非常に大きいものだと個人的には思っています。専門分野を複数持つハードルも下がり、異分野融合も促進されるでしょう。
非常に楽しみですね。
僕なんかは、Spark、Stan、Bioconductor、GoogleCloudPlatform、Watson、Azure、AWSなど、大量の英語ドキュメントが、大量に高速で読めるようになるため、うれしくて仕方がありません。
ということで、今日は、ここまでにしたいと思います。
いろいろ、Google翻訳先生に翻訳してもらって、どういう間違いの傾向があるかつかんだ後で、ひたすら翻訳してもらうのがよいと思います。
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程1年
一般社団法人Bizjapan
東京大学機械学習勉強会