2017.04.05 Wed |
Kaggleデータをあさってみる4(Human Resource Analysis)

前回に引き続き、Human Resource Analytisisのデータ解析を続けていきたいなと思います。
前回の記事はこちらから
http://ritsuan.com/blog/5985/
前回から、交互作用項の候補の詳細を見ていますが、その続きです。
以下の変数の組み合わせを見ていきます。
(2)両方が質的変数の一水準なもの
(2-1)number_project3:time_spend_company3
(2-2)number_project4:time_spend_company3
(2-3)number_project6:time_spend_company3
(2-4)number_project4:time_spend_company5
(2-5)number_project6:time_spend_company5
(2-6)number_project6:time_spend_company6
(2-7)time_spend_company6:salarylow
(2-8)Work_accident1:promotion_last_5years1
(2-9)salesmanagement:salarylow
(2-10)salesmanagement:salarymedium
(3)両方が量的変数なもの
(3-1)satisfaction_level:last_evaluation
(3-2)last_evaluation:average_montly_hours
まず毎度同じくデータの読み込みと、離散値のFactor化です。
#データの読み込み
t=read.csv(“HR_comma_sep.csv”,header=T)
#質的変数のFactor化
i=0
d=t
for (i in c(3,5,6,7,8)){
d[,c(i)]=as.factor(t[,c(i)])
}
str(d)
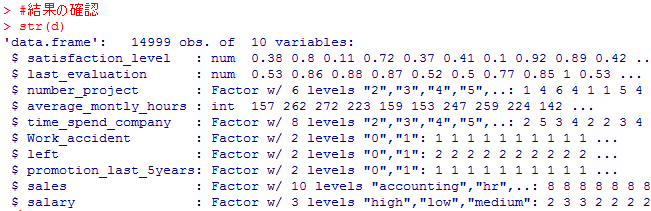 まず、
まず、
(2-1)number_project3:time_spend_company3
(2-2)number_project4:time_spend_company3
(2-3)number_project6:time_spend_company3
(2-4)number_project4:time_spend_company5
(2-5)number_project6:time_spend_company5
(2-6)number_project6:time_spend_company6
を検討していきましょう。
可視化には、前回同様ggplot2パッケージを使用します。
#ggplot2パッケージのロード
library(ggplot2)
ggplot(data = d) +
geom_bar(mapping = aes(x = left, fill = left))+
facet_grid(number_project ~ time_spend_company)
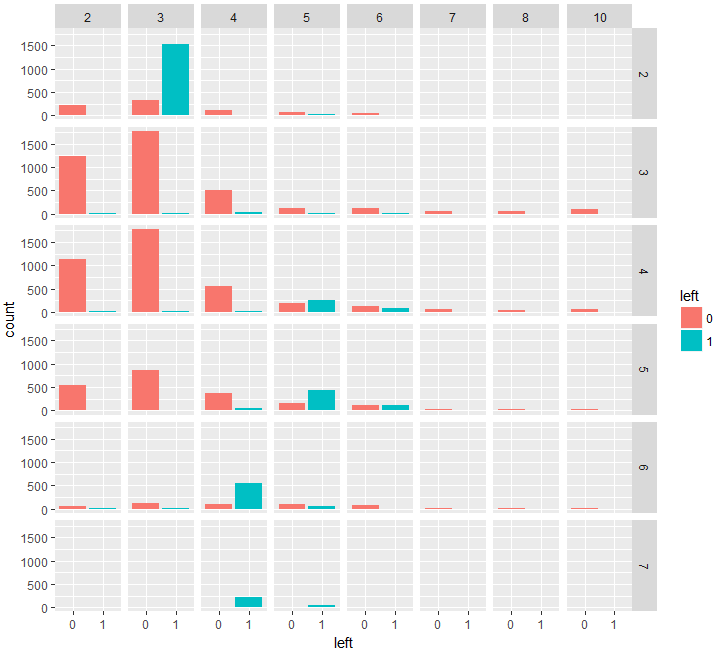 この図は少し理解するのが難しく感じられるかもしれませんが、実はシンプルです。
この図は少し理解するのが難しく感じられるかもしれませんが、実はシンプルです。
赤いバーは各条件で、会社を辞めていない人の人数、青いバーは、各条件で、会社を辞めた人の人数です。
そして灰色のブロックは、各条件を表しています。
例えば、左上の灰色ブロックは、
time_spend_company=2かつnumber_project=2の条件において、退職していない人が約250人、退職した人が0人であることを表しています。
左上から一つ右隣のブロックは、
time_spend_company=3かつnumber_project=2の条件において、退職していない人が約280人、退職した人が約1510人であることを表しています。
見方がわかったところで、
(2-1)number_project3:time_spend_company3(赤枠)
(2-2)number_project4:time_spend_company3(赤枠)
(2-3)number_project6:time_spend_company3(赤枠)
(2-4)number_project4:time_spend_company5(青枠)
(2-5)number_project6:time_spend_company5(青枠)
(2-6)number_project6:time_spend_company6(紫色)
を見ていきましょう。色でどこを示すかわかるようになっています。
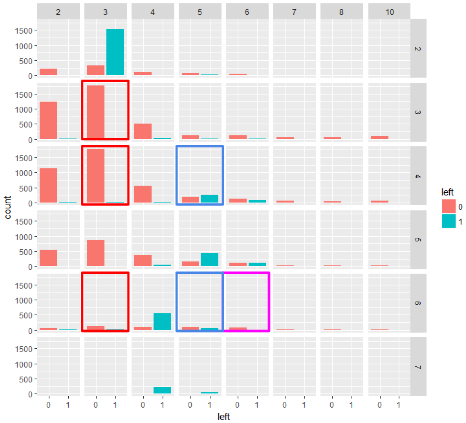 赤枠は、どれも、赤(辞めていない人)が多く、青(辞めた人の人数)が少ないですね。なので、優秀な社員を引き留めるsolutionにはつながらないでしょう。交互作用項としては、たしかにこれらの条件がそろうと((2-1)または(2-2)または(2-3))、辞めない人の割合が、他のブロックと比べて、著しく増えるので、ありなのかなと思います。
赤枠は、どれも、赤(辞めていない人)が多く、青(辞めた人の人数)が少ないですね。なので、優秀な社員を引き留めるsolutionにはつながらないでしょう。交互作用項としては、たしかにこれらの条件がそろうと((2-1)または(2-2)または(2-3))、辞めない人の割合が、他のブロックと比べて、著しく増えるので、ありなのかなと思います。
紫枠も赤枠と同様の解釈です。
青枠は、それなりに青(辞めている人)があり、この条件が揃おうと、辞めやすくなるといえるでしょう。
青枠は、再度条件を掲載しますと、
(number_project=4かつtime_spend_company=5)と
(number_project=6かつtime_spend_company=5)です。
これらの条件がそろわないようにかつ、青色が少なく赤色が少ないブロックの条件にプロジェクト数と会社で費やした時間をもっていくsolutionが考えられます。
次は、
(2-7)time_spend_company6:salarylow
を見ていきましょう。
ggplot(data = d) +
geom_bar(mapping = aes(x = left, fill = left))+
facet_grid(salary ~ time_spend_company)
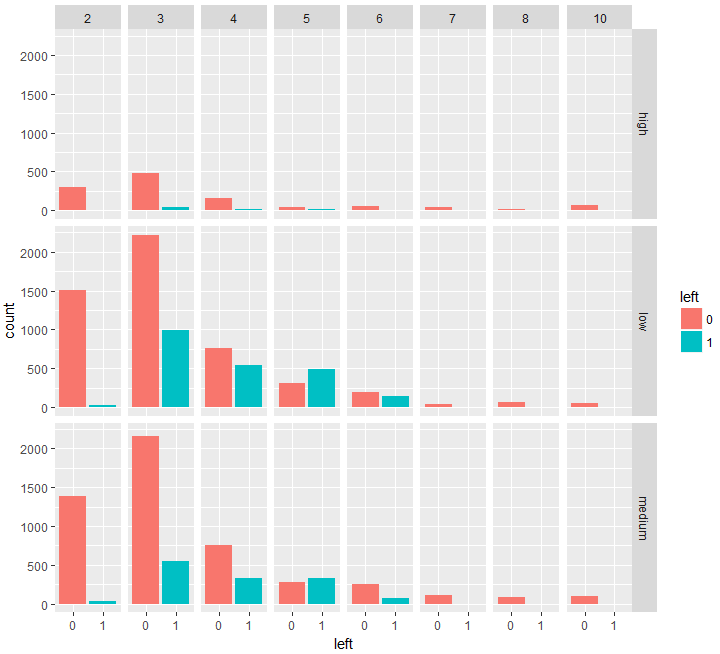 time_spend_company=6かつsalary=lowのところを見てみます。
time_spend_company=6かつsalary=lowのところを見てみます。
time_spend_company=6は左から5列目、salary=lowは上から2段目のブロックです。
この条件の下では、それなりに青(辞めている人)があり、time_spend_company=6という、経験を積んだ社員がやめるのを阻止することができれば、会社にとってメリットがあるでしょう。この場合も、青が多く赤が少ないブロックの条件に変えればよいため、給料をmediumかhighに変えればよい、ということが考えられます。
このbarplotの全体を見返してみると、基本的にやめる人は給料がより低い人が辞める傾向があるみたいですね。ただしtime_spend_company=2ではやめず3以降に辞める人が多くなり、その後辞める人が減少していく傾向があるようですね。全体を通して給与が高い人はあまりやめません。
次に行きたいと思います。
(2-8)Work_accident1:promotion_last_5years1
同じようにプロットしてきます。
ggplot(data = d) +
geom_bar(mapping = aes(x = left, fill = left))+
facet_grid(Work_accident ~ promotion_last_5years)
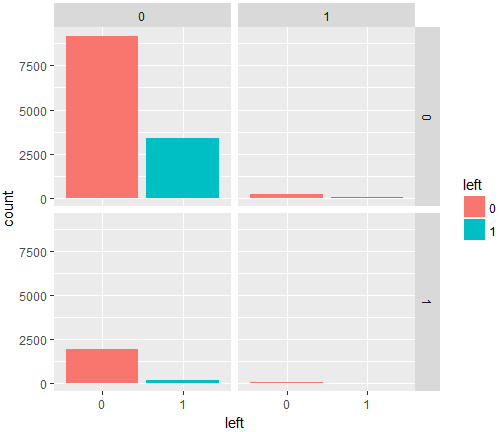 この図の見方ですが、4つある灰色のブロックのうち、例えば右上が、
この図の見方ですが、4つある灰色のブロックのうち、例えば右上が、
Work_accident=0(事故なし)かつpromotion_last_5years=1(昇進あり)
4つある灰色のブロックのうち、左下が、
Work_accident=1(事故あり)かつpromotion_last_5years=0(昇進なし)
を示しています。
今回検出された交互作用項は右下のブロックなのですが、赤がわずかにあるくらいですね。。
仮にこの条件がそろうと辞めにくくなる交互作用があるとしても、あまり参考にならなそうですね。
4つのブロックのうち上の二つが、事故なしで、下の二つが事故ありなのですが、事故があっても会社を辞める人が劇的に増えるということはないようです。逆に事故があったほうが会社を辞める人の割合が減るように見えますが、これは擬似相関などだと考えられます。
次に、
(2-9)salesmanagement:salarylow
(2-10)salesmanagement:salarymedium
を見ていきましょう。
同じようにプロットしてきます。
ggplot(data = d) +
geom_bar(mapping = aes(x = left, fill = left))+
facet_grid(sales ~ salary)
 これで、どの部署(sales)の、どのくらい賃金をもらっている人が、どれくらいの割合で辞めたかわかりますね。給料が低いほど、辞める傾向があることがわかります。また部署によっても在籍人数と辞職人数の割合の特徴があるようです。営業部(sales)、お客様対応部(support)、技術部(technical)が在籍数も多く辞めた人も多い傾向があるようです。給料がlowかmediumかで辞めた人数の割合が大きく違う部署に、営業部(sales)、お客様対応部(support)がありますが、この部署の人たちは、仕事より賃金にモチベーションがあることが推測できますね。
これで、どの部署(sales)の、どのくらい賃金をもらっている人が、どれくらいの割合で辞めたかわかりますね。給料が低いほど、辞める傾向があることがわかります。また部署によっても在籍人数と辞職人数の割合の特徴があるようです。営業部(sales)、お客様対応部(support)、技術部(technical)が在籍数も多く辞めた人も多い傾向があるようです。給料がlowかmediumかで辞めた人数の割合が大きく違う部署に、営業部(sales)、お客様対応部(support)がありますが、この部署の人たちは、仕事より賃金にモチベーションがあることが推測できますね。
ざっくり俯瞰したところで、交互作用項を見ていきましょう。
(2-9)sales=managementかつsalary=low
(2-10)sales=managementかつsalary=medium
この二つが交互作用の影響が出ているといわれても上の結果を見てみると、特に他と変わったことはないことから、特にsolutionにはつながらないでしょう。
では、次に移ります。
(3)両方が量的変数なもの
(3-1)satisfaction_level:last_evaluation
(3-2)last_evaluation:average_montly_hours
を一つずつ見ていきます。
(3-1)satisfaction_level:last_evaluation
から行きます。
これは、散布図をplotして、各点の色をleft(0)かleft(1)で変えます。
ggplot(data = d) +
geom_point(mapping = aes(x = satisfaction_level, y = last_evaluation, color = left))
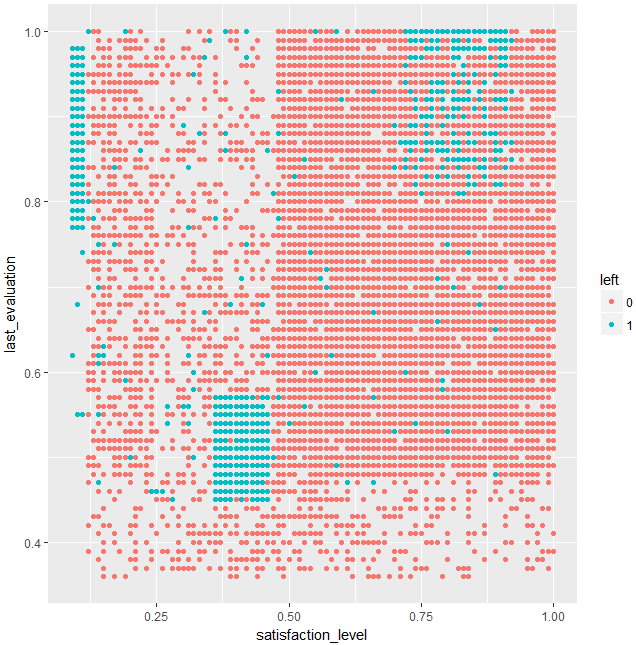 このplotはウソではありませんplot関数で実行しても同じ結果が出ます。
このplotはウソではありませんplot関数で実行しても同じ結果が出ます。
このplotには、人為的なものを感じる方もいらっしゃるでしょう。
実は、実際に人為的なデータです。データセットの説明にも書いてあります。
 https://www.kaggle.com/ludobenistant/hr-analytics
https://www.kaggle.com/ludobenistant/hr-analytics
このデータを用いた理由は、内容がユニークであり、仮に実際のデータでなくとも、このデータ解析方法は実際のデータを解析するための重要な洞察を与えてくれると思ったからです。
では先ほどのplotの結果の解釈に戻りましょう。
交互作用が大きいときは、変数同士が独立でないとき、たとえば相関係数が高いときです。
今回は青い点(辞めた人)が右上がりの対角線上に(主に)あり、それが、交互作用として認識されたのでしょう。もしこれが、実際の辞めた人のデータであれば、青い点の条件の人をいかにして赤い点のところに持っていくかが、優秀な人を辞めさせないsolutionとなります。ちなみに、どの点がlast_evaluationが高い人なのかですが、今回は、縦軸がlast_evaluationなので、上にあるほど、優秀な人となります。満足度(satisfaction_level)が著しく低いグループと、高いグループがありますね。満足度が高く優秀なグループは、会社にとどまらせるべきなので、その人たちを特定して何らかのsolutionを打つべきでしょう。
ちなみに、このplotで、なぜrandomforestが精度がよかったか納得できますね。赤点と青点が、x軸またはy軸に平行な線で分割可能だからです。
それでは最後、
(3-2)last_evaluation:average_montly_hours
に行きたいと思います。
これは、散布図をplotして、各点の色をleft(0)かleft(1)で変えます。
ggplot(data = d) +
geom_point(mapping = aes(x = average_montly_hours, y = last_evaluation, color = left))
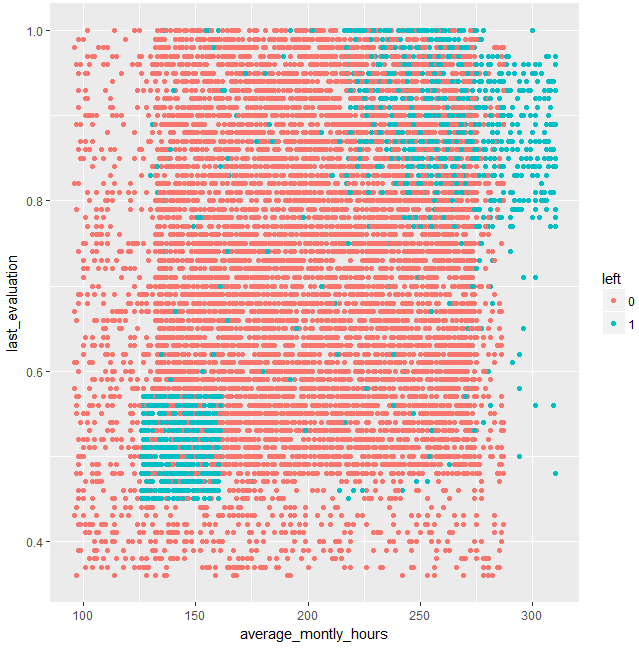 こちらも、The人為的って感じがしますが、あまり気にしないで解説していきます。
こちらも、The人為的って感じがしますが、あまり気にしないで解説していきます。
交互作用項として検出されたのは、青い点が、右上がりの対角線上にあるからでしょう。
もしこれが本当のデータだとした場合、右上のlast_evaluationが高い人たちのような人たちを増やさないように、右上の位置の条件になってしまった人を以下に素早く検知し、他の位置の条件に移すが重要になります。ここでの横軸は、月の平均労働時間なので、労働時間を減らすというのも、soluktionの一つとしてあり得ると思います。
ということで、以上で長く続いた、Human Resource Analysisのデータ解析を終わりにします。
何か解析したら面白そうなデータがありましたら、
machine.learning.r@gmail.com
までご連絡ください。時間があればこんな感じに記事にします。
鈴木瑞人
東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程
東京大学機械学習勉強会 代表
NPO法人Bizjapan Technology部門 BizXチームリーダー