2017.07.06 Thu |
多くの人はどのようにしてプログラミングを学ぶか?
 最近プログラミングがちょっとしたブームになっていますが、どんな人が、どこで、どのような目的で、どんな言語を学んでいるかについてのいい感じのデータを見つけたので、主計・可視化・(できたら)解析までやってみたいと思ます。
最近プログラミングがちょっとしたブームになっていますが、どんな人が、どこで、どのような目的で、どんな言語を学んでいるかについてのいい感じのデータを見つけたので、主計・可視化・(できたら)解析までやってみたいと思ます。
今回解析するデータはこれです。
2016 New Coder Survey
A survey of 15,000+ people who are new to software development
 https://www.kaggle.com/freecodecamp/2016-new-coder-survey-
https://www.kaggle.com/freecodecamp/2016-new-coder-survey-
このデータは、Free Code Campという団体が集めたものらしいです。
Free Code Campは、コード(プログラミング)を学び、非営利のプロジェクトを立ち上げるための、オープンソースコミュニティとのことです。
このデータを収集した目的は、人々のプログラミングを学ぶモチベーション、プログラミングの学び方、彼らの人口統計・社会経済的背景を知る事だそうです。
このデータは、twitterとメーリングリストを通じて得られた、過去5年以内にプログラミングを始めた1万5千人以上のデータとのことです。
では、さっそくデータを読み込んでみましょう。
#データの読み込み
d=read.csv(“2016-FCC-New-Coders-Survey-Data.csv”,header=T)
#データの頭出し
str(d)
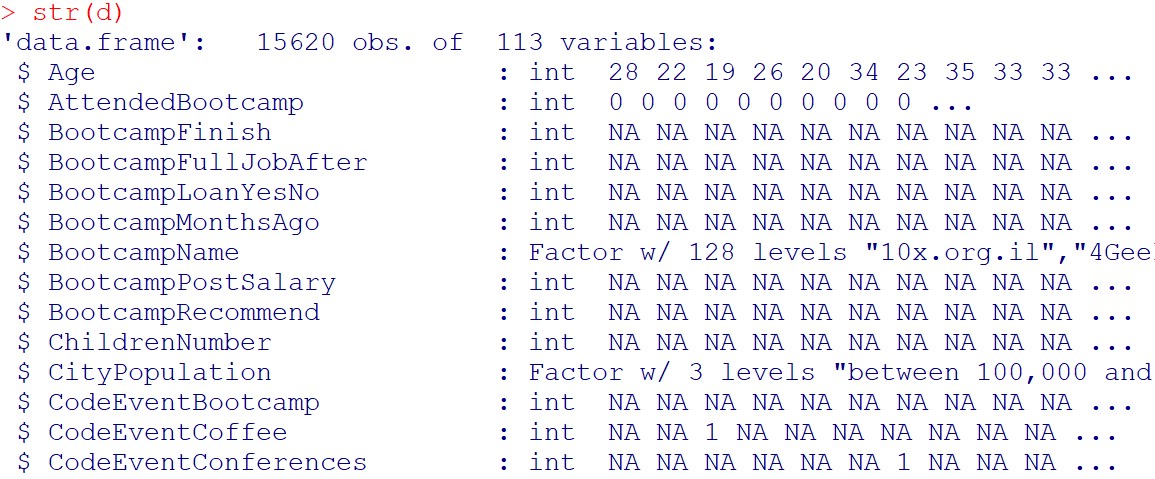 ということで、113変数、15620サンプルありますね。。
ということで、113変数、15620サンプルありますね。。
地道に一変数ずつ見ていきましょう。
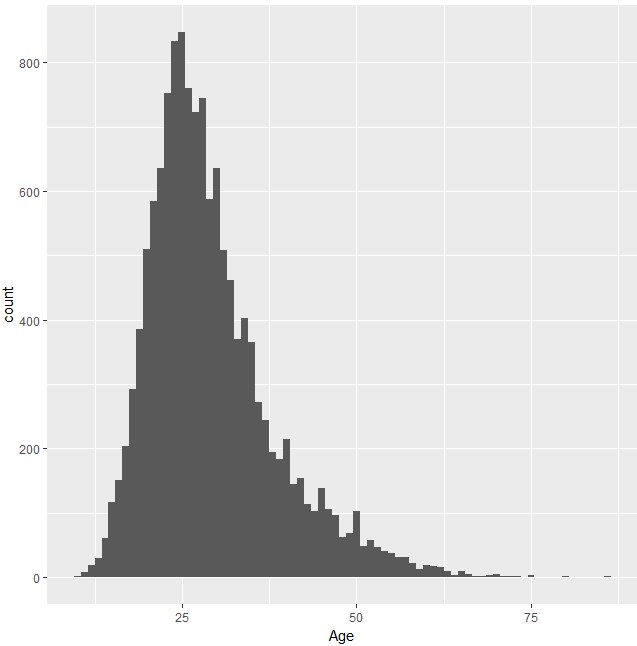
まずAge変数から。
ヒストグラムを作成してみましょう。
library(ggplot2)
#1歳ごとで区切ってヒストグラムを作成
ggplot(d)+geom_histogram(aes(Age),binwidth=1)
これを性別で色付けしていきます。
ggplot(d)+geom_histogram(aes(x=Age,fill=Gender),binwidth=1)
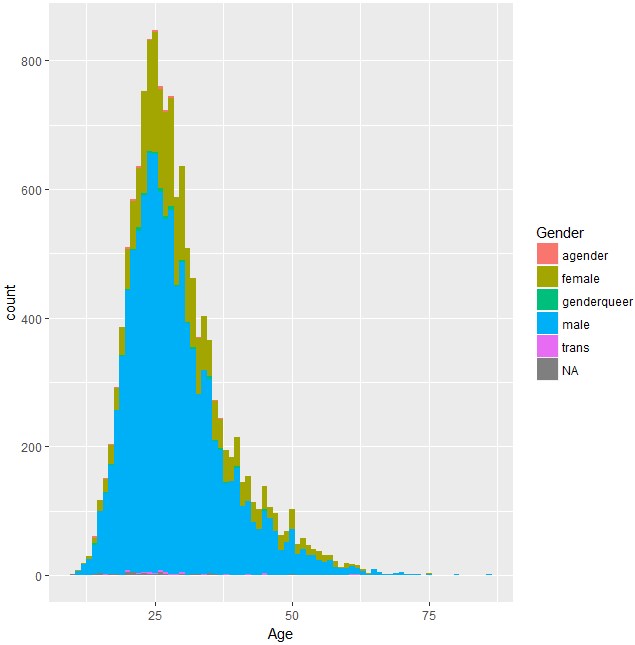 大部分は男性ですね。女性は、25歳以上になると増えてきますね。
大部分は男性ですね。女性は、25歳以上になると増えてきますね。
次に住んでいる市の人口を示すCityPopulation変数を可視化していきます。
ggplot(d)+geom_bar(aes(CityPopulation))+coord_flip()
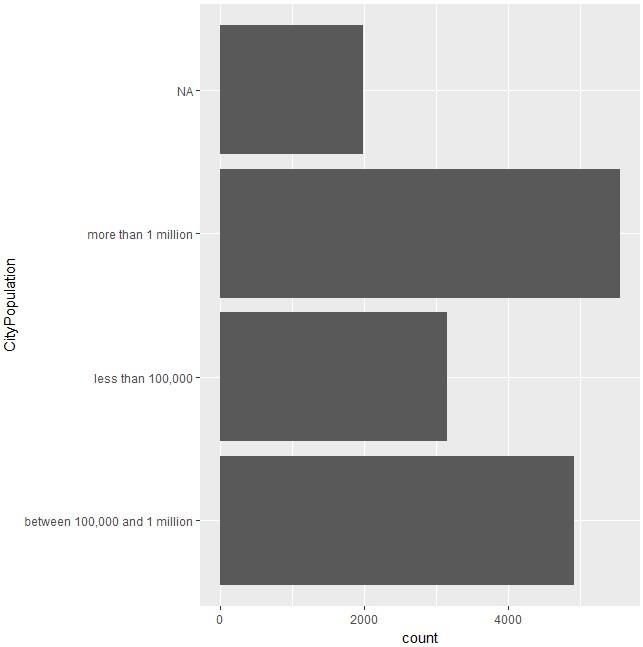 大都市に住んでいる人が多いことが分かります。
大都市に住んでいる人が多いことが分かります。
次に国別に人口を見ていきます。
library(dplyr)
u=d%>%group_by(CountryCitizen)%>%summarize(Num=n())%>%arrange(desc(Num))
u[1:15,]
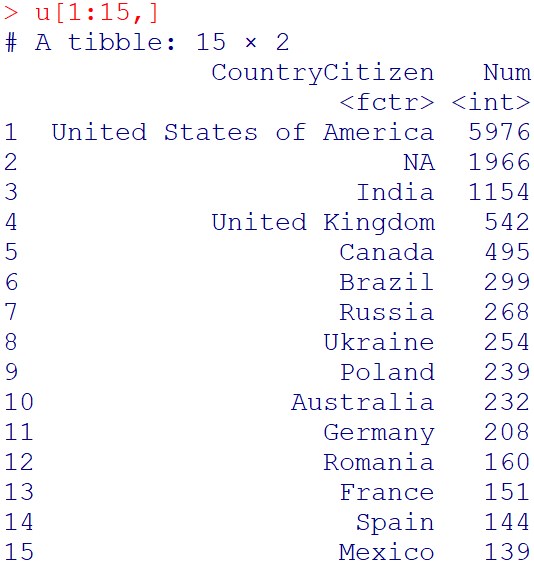 1位アメリカ、2位インド、3位イギリス、、と英語を話せる人口が多い地域が上位を占めていますね。中国は23位で、国内に英語でない母国語でのプログラミング学習サイトがある国では、Free Code Campのサービスは使われないようですね。
1位アメリカ、2位インド、3位イギリス、、と英語を話せる人口が多い地域が上位を占めていますね。中国は23位で、国内に英語でない母国語でのプログラミング学習サイトがある国では、Free Code Campのサービスは使われないようですね。
次は、どのOnline講座を使ったことがあるかを調べてみます。
日本だと、ドットインストールなどの日本語のサイトがメインになるのですが、世界規模だと人気のOnline講座は全く異なったラインナップになります。
#変数名内にResourceとある変数だけ取り出し、使わないResourceOther変数を消去
a=d%>%select(matches(‘Resource’))%>%select(-ResourceOther)
library(formattable)
data.frame(name=substring(names(a),9), count=colSums(a,na.rm=TRUE),row.names=NULL)%>%
arrange(desc(count))%>%
formattable(list(count = color_bar(“lightblue”)),align = ‘l’)
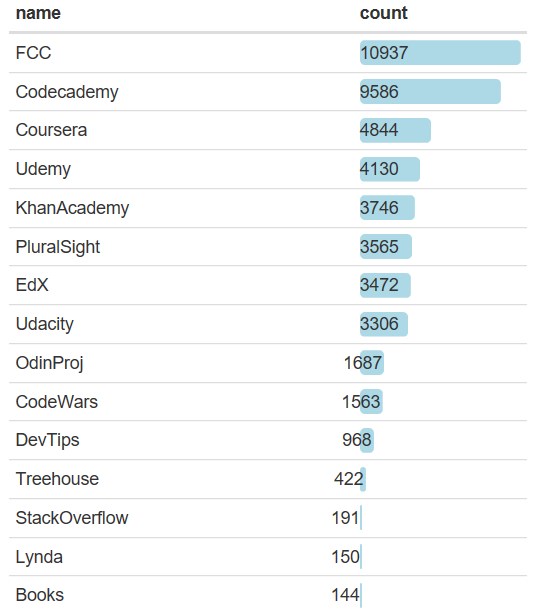 見たことがないものも多いですが、これが海外の英語圏の方たちが使用しているonlineコースです。個人的には、CourseraやEdXが一位と二位になっていないのが意外ですが、たぶんレベルが高すぎるのでしょうね。
見たことがないものも多いですが、これが海外の英語圏の方たちが使用しているonlineコースです。個人的には、CourseraやEdXが一位と二位になっていないのが意外ですが、たぶんレベルが高すぎるのでしょうね。
ちなみにこの集団の母国語は何が多いのでしょうか?今までの結果からだと、英語が多い気がしますが。
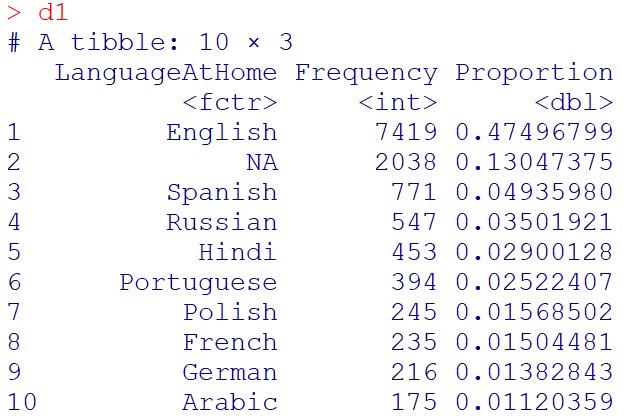
d1=d%>%group_by(LanguageAtHome) %>%
summarize(Frequency = n()) %>%
mutate(Proportion = Frequency/sum(Frequency)) %>%
arrange(desc(Frequency))%>%
head(10)
d1
ggplot(data=d1,aes(LanguageAtHome,Frequency)) +
geom_bar(stat=”identity”)
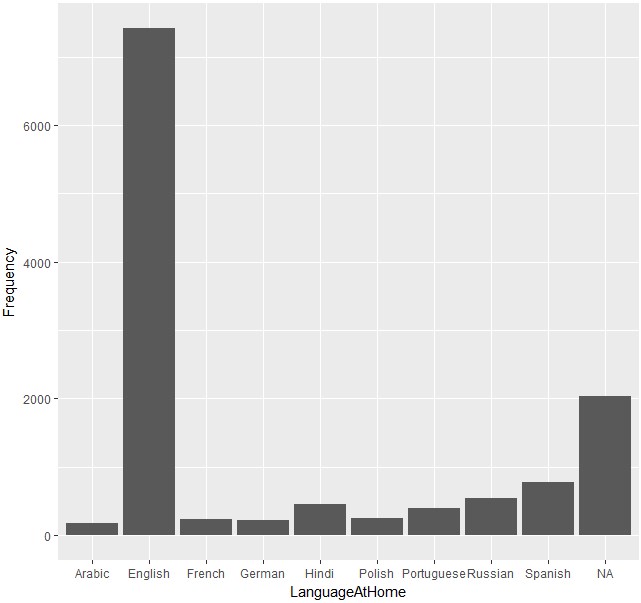 予想通り英語話者が多いですね。
予想通り英語話者が多いですね。
スペイン語が多いのは、アメリカでのスペイン語話者が多いこと、ヒンディー語が多いのはインドでヒンディー語の話者が多いからでしょう。
では最後にPodcastとして何を使っているかについて。
b=d%>%select(matches(‘Podcast’))%>%select(-PodcastOther)
data.frame(name=substring(names(b),8),
count=colSums(b,na.rm=TRUE),row.names=NULL)%>%
arrange(desc(count))%>%
formattable(list(count = color_bar(“lightblue”)),align = ‘l’)
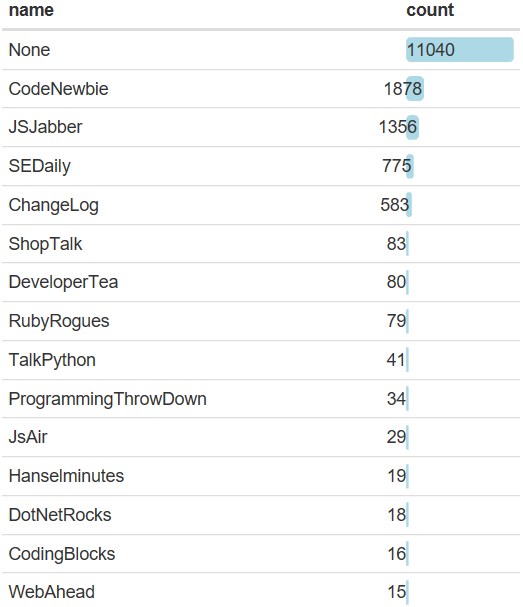 Podcastは使っていない人が多いですが、使っている人は、CodeNewbieやJSJabberなどが広く使われているようです。個人的にはどれも知りませんが。
Podcastは使っていない人が多いですが、使っている人は、CodeNewbieやJSJabberなどが広く使われているようです。個人的にはどれも知りませんが。
ということで、2016 New Coder Surveyのデータ解析をここで終わりにします。
新しくプログラミングを学ぶ時の学習方法の参考にもしかしたらなるかと思います(英語できれば)
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻 博士課程
東京大学機械学習勉強会 代表
NPO法人Bizjapan