2017.10.02 Mon |
DeepLearning(CNN)のHyper-parameters Tuning2
 前回、前々回に引き続き、今回もRでkerasを使ったDeepLearningを実行していきます。
前回、前々回に引き続き、今回もRでkerasを使ったDeepLearningを実行していきます。
環境設定など内容が前回・前々回と被るところはこの記事では省略します。
現在筆者(鈴木瑞人)が、Kaggleのコンテストに挑戦していることもあり、
前回に引き続き、DeepLearningのHyper-parameter tuningについていろいろ試してみます。
前回の知見をもとに今回標準となるNeural Networkを設定します。
ちなみに今回は、少し作業時間が多めにとれたのでepochs=10で実行します。
以下が標準となるNeural Networkです。
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
ちなみに、モデルの収束は以下で、
plot(history)
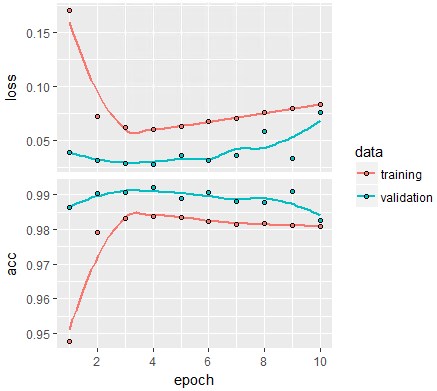 epochは6か7程度でよいみたいですね。精度が落ちています。。
epochは6か7程度でよいみたいですね。精度が落ちています。。
epoch数を下げてもよいのですが、今回はこのまま実験していきます。
基準となるモデルの精度は以下です。
model %>% evaluate(x_test, y_test)
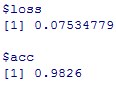
epoch4,5,6あたりの精度を使用したいところですが、今回はepoch=10の精度である、0.9826を基準として使用してみます。
今回検証してみる項目は以下になります。
①活性化関数としてreluの代わりにleaky_reluを使用
②活性化関数としてreluの代わりにparametric_reluを使用
③一つ目のMaxpoolingを消す
④二つ目のMaxpoolingを消す
⑤Maxpoolingを両方消す
①、②は活性化関数の変更になります。
最近はreluより、leaky_reluやprelu(parametric_relu)が良いということを耳に挟んでいたので試してみます。
③、④、⑤はMaxpoolingの変更になります。
以前知人からMaxpoolingは最近使われなくなってきていると聞いたのですが、なくしたり、他のものに変えたりしてみた方が良いのかということを検証してみます。
それでは、①から検証していきましょう。
①活性化関数としてreluの代わりにleaky_reluを使用
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation_leaky_relu() %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation_leaky_relu() %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation_leaky_relu() %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256) %>%
layer_activation_leaky_relu() %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#モデルの収束可視化
plot(history)
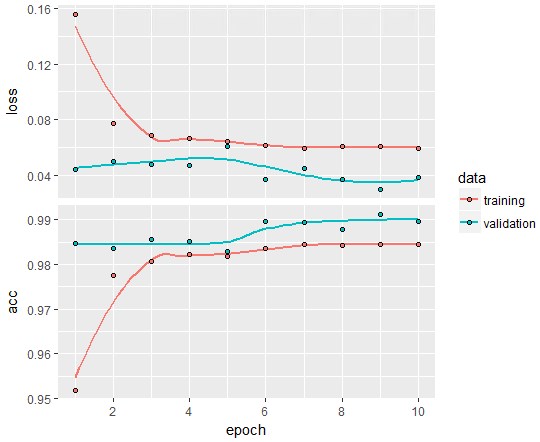 結構安定していますね。悪くはないようです。
結構安定していますね。悪くはないようです。
#精度
model %>% evaluate(x_test, y_test)
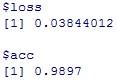
基準である0.9826と比較すると、0.9897と精度は向上しています。
次はparametric_reluを試してみます。
②活性化関数としてreluの代わりにparametric_reluを使用
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation_parametric_relu() %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation_parametric_relu() %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation_parametric_relu() %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation_parametric_relu() %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256) %>%
layer_activation_parametric_relu() %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#モデルの収束可視化
plot(history)
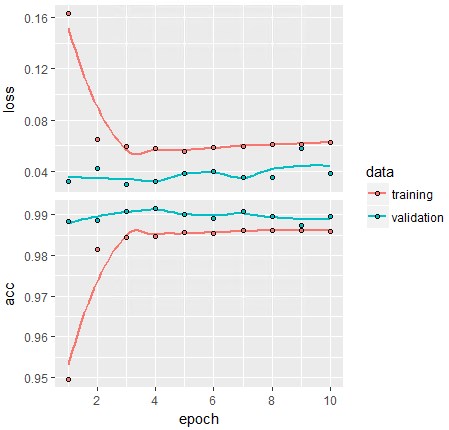 こちらもそれなりに安定したモデルですね。
こちらもそれなりに安定したモデルですね。
#精度
model %>% evaluate(x_test, y_test)
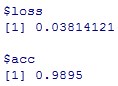
基準である0.9826と比べると精度は向上し0.9895となっています。
③一つ目のMaxpoolingを消す
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#モデルの収束可視化
plot(history)
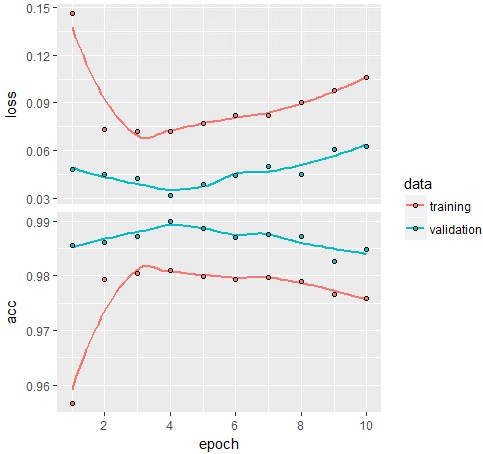 こちらかなり不安定なモデルになっています。やはりMaxpoolingは必要みたいです。
こちらかなり不安定なモデルになっています。やはりMaxpoolingは必要みたいです。
#精度
model %>% evaluate(x_test, y_test)
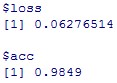
基準である0.9826よりは、精度がよく、0.9849となっています。
基準が精度が悪すぎましたね。。
④二つ目のMaxpoolingを消す
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#モデルの収束可視化
plot(history)
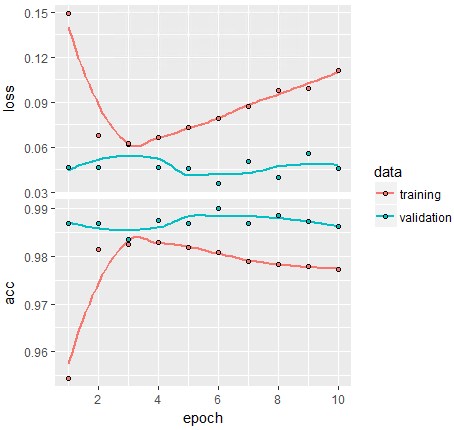 一つ目のMaxpoolingは残っているので、それなりに安定しています。
一つ目のMaxpoolingは残っているので、それなりに安定しています。
#精度
model %>% evaluate(x_test, y_test)
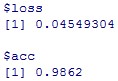
基準である0.9826よりは高く、精度は0.9862となっています。
⑤Maxpoolingを両方消す
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#モデルの収束可視化
plot(history)
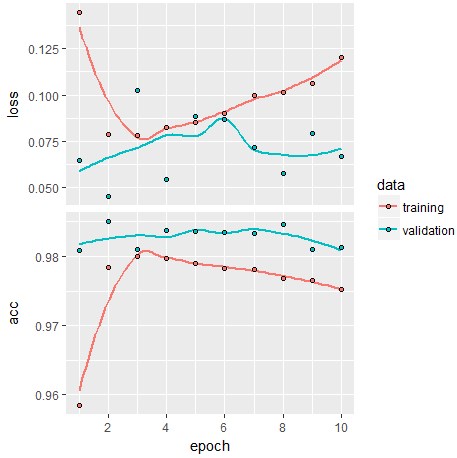 Maxpoolingを二つとも消すとかなり不安定なモデルとなりました。
Maxpoolingを二つとも消すとかなり不安定なモデルとなりました。
#精度
model %>% evaluate(x_test, y_test)
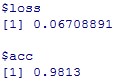
基準である0.9826より精度が悪く、0.9813となりました。
Maxpoolingを両方消すとよくないみたいです。
以上で以下の項目を検証し終わりました。
基準が悪かったので、基準は気にしないで、以下精度を比較してみます。
①活性化関数としてreluの代わりにleaky_reluを使用(0.9897)
②活性化関数としてreluの代わりにparametric_reluを使用(0.9895)
③一つ目のMaxpoolingを消す(0.9849)
④二つ目のMaxpoolingを消す(0.9862)
⑤Maxpoolingを両方消す(0.9813)
今回のデータ・ネットワークアーキテクチャでは、精度に際立って大きな違いは見出せませんでしたが、活性化関数であるleaky_reluやparametric_reluがモデルに安定性をもたらす可能性は言えたかなと思います。この二つの活性化関数が効果を表すネットワークアーキテクチャや他のパラメータセット、データセットに関して全く調べられていないので、一般論は言えませんが、MNISTデータセットを今回のようなNeuralNetに入れた感触からだとleaky_reluやparametric_reluは、精度を上げるには大して貢献しないと思います。
Maxpoolingは使われなくなってきているという知人からの情報を元にMaxpoolingをとりあえず消してみたところ、少なくとも一番初めのMaxpoolingは重要なようです。
ということで長くなりましたが、今回のDeepLearning(CNN)のHyper-parameter tuningを終わりにします。
鈴木瑞人
東京大学大学院新領域創成科学研究科 メディカル情報生命専攻 博士課程
NPO法人Bizjapan テクノロジー部門BizXチームリーダー