2017.10.01 Sun |
DeepLearning(CNN)のHyper-parameters Tuning
 前回、Rでkerasを用いて、DeepLearningを実行する記事を書きましたが、今回はその続編です。
前回、Rでkerasを用いて、DeepLearningを実行する記事を書きましたが、今回はその続編です。
DeepLearningといっても今回は特に畳み込みニューラルネットワーク(Convolutional Neural Network、今後CNNと略)を、扱います。
CNNには、簡単な構造でもかなり高い精度を出すのですが、Kaggle Competitionのような国際的な機械学習のコンテストで、成果を出すには、より高い精度を必要とします。
たとえば、現在筆者(鈴木瑞人)は、Kaggle CompetitionのDigit Recognizer(https://www.kaggle.com/)というコンテストで、1701チーム中245位(2017年9月30日現在)ですが、現時点での精度は、0.99342です。
これを限りなく0.999999に近付けていくことで、上位に食い込むことができます。
ちなみに日本または、世界の先進国において、kaggleコンテストで上位10%以内に入っていると、基本的には機械学習の実用において、上級者と判断されます。
ビジネスの世界においては、機械学習で相当高い精度を要求される場面は、ガンの診断などシビアなものを除けば、あまりありません。
しかし、Kaggleでいろいろなデータやモデルを扱うと、機械学習の実用について知識が深まり、実際にビジネスでシステムを構築する際に大いに役に立つことは、多くのkaggleコンテスト上位者のインタビューの記述で目にすることができます(http://blog.kaggle.com/category/winners-interviews/)。
ということで、今回は、どうやったらDeepLearning(CNN)の精度が上がるかを試してみたいと思います。
Kaggleコンテストのデータ解析は基本的にkaggle kernelでしか公開してはいけないことになっているので、今回はRのkerasパッケージに付属のMNISTデータ(一般的なものと同一)でいろいろと精度を上げる実験をしていきます。
それでは一番僕がよく使うCNNのモデルを使って、これからいろいろ性能を比べる際の基準となる精度を出します。
ちなみに環境は、
GoogleCloudPlatformComputeEngine
Windows 2016
2.30GHz CPU 8個
メモリ30GB
です。
最初の環境のセットアップに関しては前回の記事をご覧ください。
RのkerasパッケージでDeepLearning
http://ritsuan.com/blog/7384/
#kerasパッケージのロード
library(keras)
install_keras()
#データのロード
mnist = dataset_mnist()
#学習用説明変数の作成
x_train = mnist$train$x
#学習用目的変数の作成
y_train = mnist$train$y
#テスト用説明変数の作成
x_test = mnist$test$x
#テスト用目的変数の作成
y_test = mnist$test$y
#画像の縦幅
img_rows=28
#画像の横幅
img_cols=28
#画像の種類(数字の0-9)
num_classes=10
#バッチサイズ
batch_size=28
#エポック数
epochs=5
#説明変数の次元変更
dim(x_train) = c(nrow(x_train), img_rows, img_cols, 1)
dim(x_test) = c(nrow(x_test), img_rows, img_cols, 1)
#データ入力次元の設定
input_shape = c(img_rows, img_cols, 1)
#基準化
x_train = x_train / 255
x_test = x_test / 255
#目的変数をone-hotベクトルへ変換
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
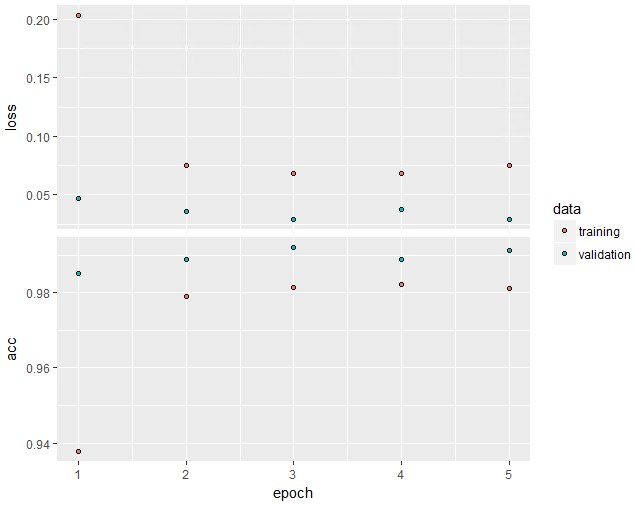 あまり時間かけたくなかったのでepochs=5で実行しましたが、それなりに収束しているようです。青い点が精度検証用データでの結果で、下のacc(accuracy)の青い点の最大値が大体0.991くらいで安定しそうなことが分かります。
あまり時間かけたくなかったのでepochs=5で実行しましたが、それなりに収束しているようです。青い点が精度検証用データでの結果で、下のacc(accuracy)の青い点の最大値が大体0.991くらいで安定しそうなことが分かります。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
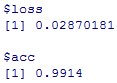 ここで出てきた精度acc(Accuracy)=0.9914が今後の標準とします。
ここで出てきた精度acc(Accuracy)=0.9914が今後の標準とします。
それでは、実験していきましょう。
今回以下のようなHyper-parameter tuningを行います。
①一層目二層目のkernel_sizeを(5,5)にする。
②三層目四層目のfilterの数を64から32へ変更する。
③各層においてreluの後にbatch_nomalizationを導入する。
④各層においてreluの前にbatch_nomalizationを導入する。
⑤最後から二層目のnodeの数を128→256にする。
⑥最後から二層目のnodeの数を128→512にする。
⑦畳み込み層を3層3層にする。
まず初めに、変更してみるのは、CNNの一層目と二層目のkernel_sizeです。
今までは、c(3,3)でやってきましたが、いろんな人の実行例を見ているとたまにc(5,5)も見かけるので、c(5,5)でやってみます。
①一層目二層目のkernel_sizeを(5,5)へ
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(5,5), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(5,5)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
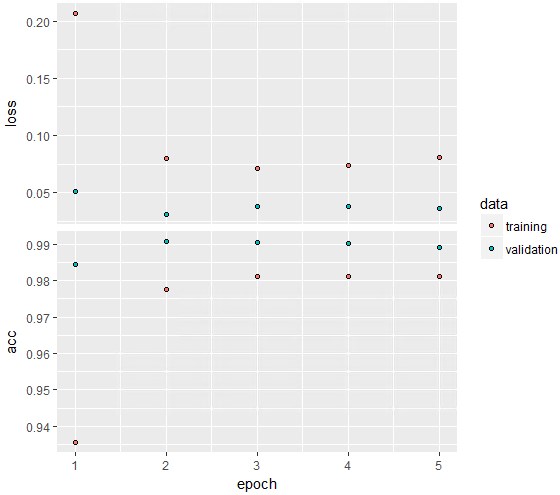
今回も大体0.99くらいで収束していますね。epochs=5でも問題なかったでしょう。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
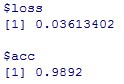
Accuracy=0.9892と先ほどの基準値(0.9914)に比べて下がりました。
一層目と二層目に関しては、kernel_sizeは(5,5)より、(3,3)がいいみたいですね。
#②三層目四層目のfilterの数を64から32へ変更
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
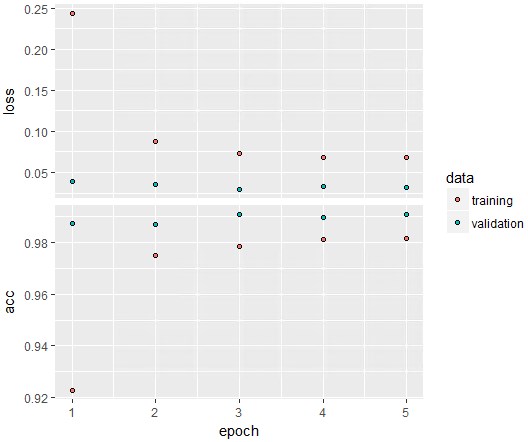
大体accuracyは収束しているように見えます。
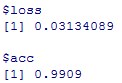
#テストデータでの評価
model %>% evaluate(x_test, y_test)
#③各層においてreluの後にbatch_nomalizationを導入
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_batch_normalization()%>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_batch_normalization()%>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_batch_normalization()%>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_batch_normalization()%>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
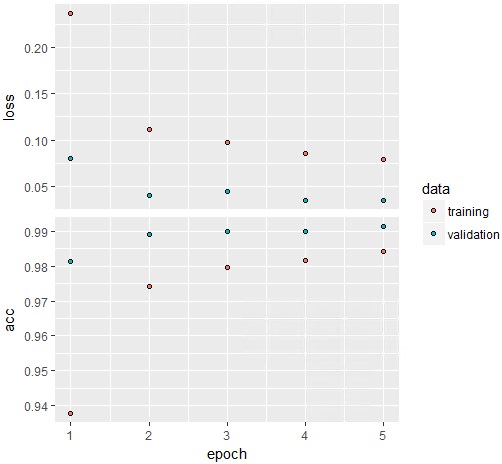 大体収束していますが、epoch数をもう少し上げるとさらにAccuracyが上がりそうです。
大体収束していますが、epoch数をもう少し上げるとさらにAccuracyが上がりそうです。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
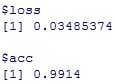 精度acc(Accuracy)=0.9914でこれは、基準の0.9914と同じです。
精度acc(Accuracy)=0.9914でこれは、基準の0.9914と同じです。
epoch数を上げた場合、ないよりあった方が良い可能性はありますが、今回はとりあえず劇的な精度上昇はなかったということにします。
次に念のためbatch_nomalizationの位置を変えてみます。
batch_nomalizationは、必要という人という人がいる割には、僕の経験上導入しても精度が上がったことがないので、今回それなりにしっかり検証したいと思います。
#④各層においてreluの前にbatch_nomalizationを導入
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_batch_normalization()%>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_batch_normalization()%>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_batch_normalization()%>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_batch_normalization()%>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
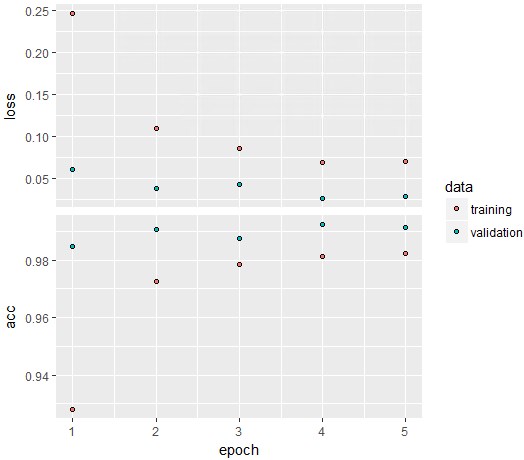
前の例と比べると若干不安定なモデルになったように思います。
ただepoch=5でも、それなりに収束していそうです。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
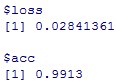
Accuracy=0.9913となり、基準である0.9914より小さくなりました。
ということで、活性化関数の前と後にbatch_nomalizationの層をいれましたが、あまり結果が変わらなかったことがわかりました。
#⑤最後から二層目のnodeの数を128→256
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 256, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
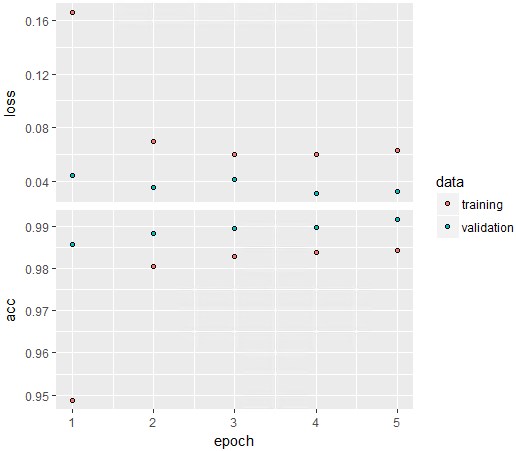 acc(Accuracy)のvalidation(青点)をみてみるとさらに精度が上がりそうです。
acc(Accuracy)のvalidation(青点)をみてみるとさらに精度が上がりそうです。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
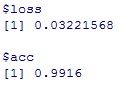 精度は、0.9916であり、基準である0.9914を超えました。
精度は、0.9916であり、基準である0.9914を超えました。
最後から二層目のnodeの数を128→256にするという戦略は正しかったようです。
#⑥最後から二層目のnodeの数を128→512
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 512, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
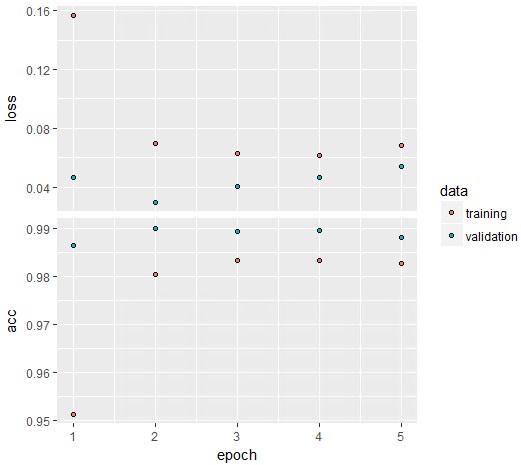 かなり不安定なのが分かります。epoch=5だと、高精度に収束する兆しはないですね。
かなり不安定なのが分かります。epoch=5だと、高精度に収束する兆しはないですね。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
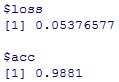 精度は、0.9881で基準となる、0.9914を下回っているのがわかります。
精度は、0.9881で基準となる、0.9914を下回っているのがわかります。
最後から二層目のnodeの数を128→512という戦略は、今回の条件では功を奏しませんでした。
#⑦畳み込み層を3層3層にする
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), input_shape = input_shape) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3)) %>%
layer_activation(‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = “categorical_crossentropy”,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history=model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#収束結果
plot(history)
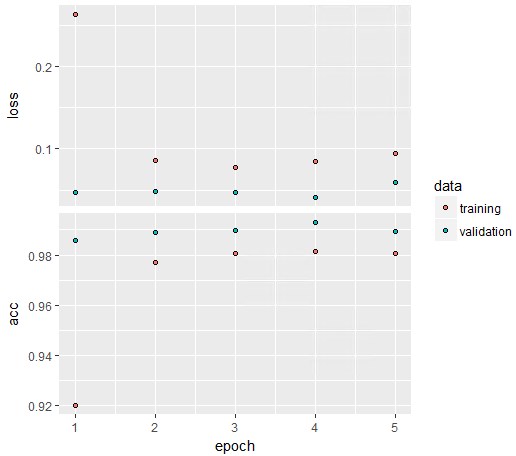 収束しているか微妙なところではありますが、さらに精度が良くなる兆しはありそうです。
収束しているか微妙なところではありますが、さらに精度が良くなる兆しはありそうです。
#テストデータでの評価
model %>% evaluate(x_test, y_test)
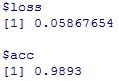 精度は0.9893と、基準である0.9914を下回っています。
精度は0.9893と、基準である0.9914を下回っています。
今回はepoch数はそろえてHyper-parameter tuingすることにしたので、
畳み込み層を3層3層にしたことは良くなかったということにします。
さて、今回以下のようなHyper-parameter tuningを行いました。
①一層目二層目のkernel_sizeを(5,5)にする。
②三層目四層目のfilterの数を64から32へ変更する。
③各層においてreluの後にbatch_nomalizationを導入する。
④各層においてreluの前にbatch_nomalizationを導入する。
⑤最後から二層目のnodeの数を128→256にする。
⑥最後から二層目のnodeの数を128→512にする。
⑦畳み込み層を3層3層にする。
この中で精度(Accuracy)が向上したものは、
⑤最後から二層目のnodeの数を128→256にする。
だけでした。。すでにいろいろ試し終わって精度の良いモデルを標準にしているので、仕方ない面もあるのですが、少し残念ですね。。
付け加えますが今回は時間と計算リソースの問題で、epoch数を5で実行しましたが、本当はepoch数20程度あるとより良いです。
ということで今回のHyper-parameter tuningを終わりにします。
鈴木瑞人
東京大学大学院新領域創成科学研究科 メディカル情報生命専攻 博士課程
NPO法人Bizjapan テクノロジー部門BizXチームリーダー