2017.10.15 Sun |
今さら聞けない「機械学習」(前編)
今や誰もが一度は聞いたことがあるであろう言葉「機械学習」。しかし、それが実際に具体的にどのように行われているのかを知っている方は少ないのではないでしょうか?
研究や開発などで触れる機会がなければ、何となく漠然と「コンピュータが自分で考えて動く」ぐらいのイメージではないかと思います。
そこで今回、次回と連続して、漠然としたイメージの「機械学習」にメスを入れ、その内側で何が行われているのかを垣間見ていきたいと思います。
具体的に何をしているのか?
機械学習とは、データの背後にある数学的な構造をコンピュータによって計算し見つけ出す仕組みです。
少しわかりにくいので、具体例として1年間の月別の平均気温のデータを考えてみます。この月ごとの平均気温の変化の様子を数式を用いて表すことができれば、翌年の気温を予測することが可能になります。つまりは元のデータの変化に対して関数近似をしようということです。
この数式を見つけ出すためにコンピュータが用いられます。
しかしすべての手順をコンピューターが行うわけではありません。
先ほどの平均気温の例で考えると、まず関数近似を行うにはそもそもの関数の型を用意してやる必要があります。2次関数なのか指数関数なのか、はたまた三角関数なのか。
このデータの背後にある関数の型を見つける作業をモデル化と呼びます。このモデル化はコンピュータではなく人間の作業になってきます。
モデルをもとにパラメータ、すなわち関数でいう係数を調整し、元データにフィットする最適な値に調整していくのがコンピュータの仕事になります。このパラメータの調整プロセスは「学習」と呼ばれています。
ではどのようにパラメータを調整するのでしょうか?
それには「誤差関数」と呼ばれるものを使用します。
コンピュータが出力した関数から得られる値と元データの値とを比較し、その誤差を小さくするようにパラメータの調整を行うのが「学習」の具体的なプロセスです。
値の比較方法にはいくつか種類があり、それは「誤差関数」として人間が用意してやる必要があります。
実際の問題には平均気温のような1次元のデータのみならずもっと高次元のデータも使われ、数学的な構造はより複雑なものとなります。与えられたデータの本質や関係性を見つけ出し、それを元に未知のデータの予測などを行うのが機械学習における人工知能の意味になってきます。
以上より、まず大前提として機械学習を行うには何らかのデータが必要になることがわかります。何らかの形でデータを収集し、コンピュータでの学習を行えるような形に変換しなければなりません。このデータを用意する作業は人間が行う必要があり、なかなか時間のかかる大変な作業になります。
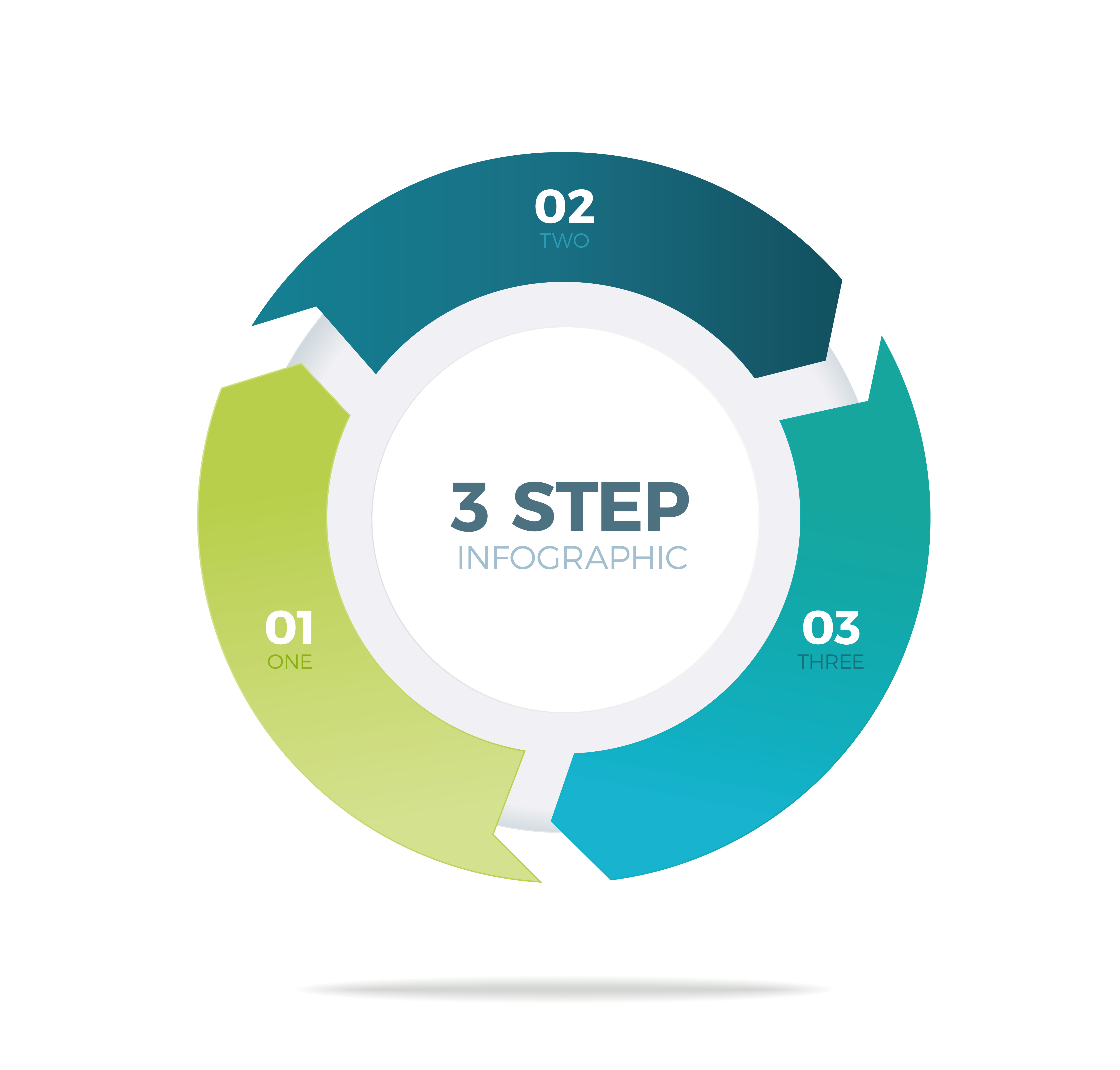
まとめると機械学習は以下の3つの段階に分けられます。
①与えられたデータを元にして、未知のデータを予測する数式を考える。(モデル化)
②数式に含まれるパラメータの良し悪しを判断する誤差関数(元のデータとどれだけずれているかを見積もる関数)を用意する。
③誤差関数を最小化するようにパラメータの値を決定する。
これによって未知の値の入力に対して予測を行うことができるようになります。繰り返しになりますが、ここで大切なのは機械学習とはすべてコンピュータが自ら行うものではなく、手順①、②に関しては人が行う必要があるということです。コンピュータの役割はあくまでパラメータを最適化することにあります。用意したモデルが良くないとこの予測精度は悪くなるため、この精度を上げるためにより良いモデルを見つけ出すことがデータサイエンティストの腕の見せ所になります。
基本的な機械学習の中身がわかったところで、次回は今流行りのニューラルネットワーク、さらにディープラーニングにメスを入れていきたいと思います。

【出典】
・「TensorFlowで学ぶディープラーニング入門 畳み込みニューラルネットワーク徹底解説」(マイナビ出版)
K.M
東京大学大学院 工学系研究科 修士課程1年