2018.01.17 Wed |
テキスト解析入門その3(日本語での共起語の分析)
 前回と前々回に続き、今回もテキスト解析を行っていきます。
前回と前々回に続き、今回もテキスト解析を行っていきます。
環境設定方法は、前回の記事に書いたのでぜひご覧ください。
今回扱う日本語のテキストは、「第百九十五回国会における安倍内閣総理大臣所信表明演説」です。
https://www.kantei.go.jp/jp/98_abe/statement2/20171117shoshinhyomei.html
このテキスト部分をテキストエディタにコピーアンドペーストして、保存します(文字コードは、Windowsの人がSHIFT-JIS(ANSI),MacとLinuxの方はUTF-8)。
ファイル名は何でもいいですが、僕は、Abe195.txtとしました。
今回は、「共起語の分析」を行ってみます。
たとえば、「日本」という単語(検索語)の一つ前、二つ前、一つ後、二つあとにどのような単語(共起語)が出てきやすいかを集計し、その共起強度の指標(T score(T), Mutual Information(MT))を算出するということを指します。
それでは、やっていきましょう。
library(RMeCab)
collocate関数で共起語を抽出します。
検索語は「日本」、前後いくつの単語まで見るかに関して前後それぞれ5個を選択しています。
result = collocate(“Abe195.txt”, node = “日本”, span = 5)
集計結果の確認
head(result, n = 10)
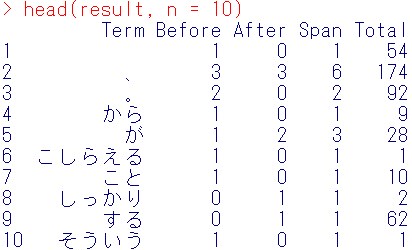 この結果の見方ですが、
この結果の見方ですが、
Term:共起語
Before:検索語の前の5個単語の中に共起語が何回現れるかを表したもの。
After:検索語の後の5個単語の中に共起語が何回現れるかを表したもの。
Span:検索語の前5単語と後5単語の中に合計いくつ共起語が現れたかどうか(Before+After)
Total:文書中で何回その共起語が現れたか。
となっています。
ただ、collocate関数では、
共起強度の指標(T score(T), Mutual Information(MT))は、算出されません。これらを算出したい場合は、collocate関数の結果に対して、
collScores関数を適用します。
result1 = collScores(result, node = “日本”, span = 5)
集計結果の確認
head(result1, n = 10)
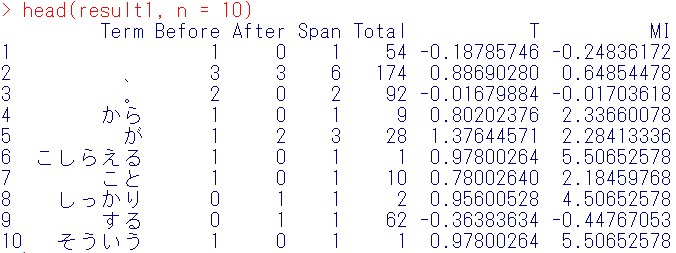 Tが大きい共起語を採用するか、MIが大きい共起語を採用するかは、目的によって異なります。
Tが大きい共起語を採用するか、MIが大きい共起語を採用するかは、目的によって異なります。
たとえば、Twitter情報(ツイート)解析で、純粋に検索語と多く共起する共起語を知りたいなら、T Scoreでよく、
アンケート調査などで、非常に数は少ないながらも、重要な共起語(システムの脆弱性の発見につながるなど)を発見したいときは、T Scoreに加えて、MTを使用します。
まず、T値が大きい共起語を抽出して可視化してみましょう。
library(dplyr)
T値が大きい順に共起語を並び替え
result2 = arrange(result1,desc(T))
結果の頭出し
head(result2, n = 20)
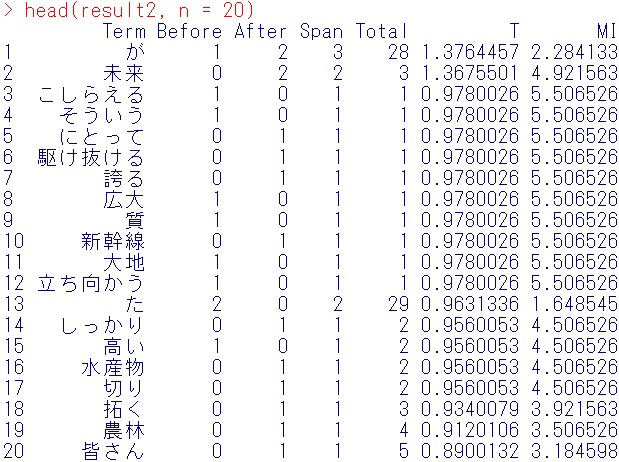
「日本」という単語と共起している単語はそもそもあまりないようです。今回の安倍首相の演説がそれほど長くなかったこと、良いスピーチほど同じ単語を繰り返し使用しないことが原因かと思います。
次に一応MI値も求めておきます。
MI値が大きい順に共起語を並び替え
result3 = arrange(result1,desc(MI))
結果の頭出し
head(result3, n = 20)
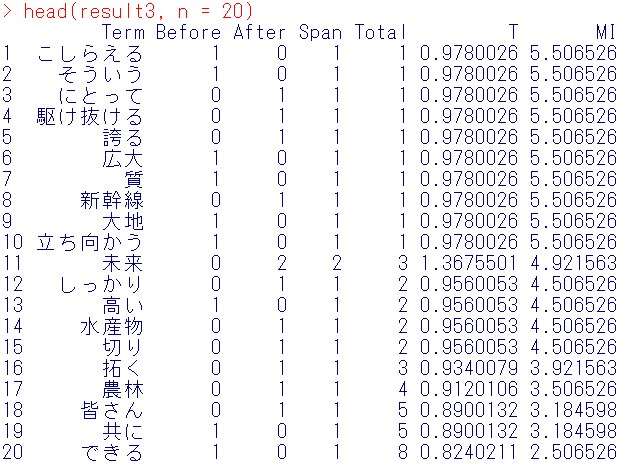 文書の中であまり同じ単語が繰り返し用いられなかったため、ここで出てきている単語は、T値が大きいものとあまり変わりません。
文書の中であまり同じ単語が繰り返し用いられなかったため、ここで出てきている単語は、T値が大きいものとあまり変わりません。
ただ、先ほども書いた通り、口コミデータのようなものに関して、ある商品名と共起する単語を知りたいときは、T値、異常値検知やシステムの脆弱性発見のためにはMI値ということで覚えておかれるとよいかと思います。
今回はここまで。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻博士課程
実践的機械学習勉強会 代表
株式会社パッパーレ 代表取締役社長
NPO法人Bizjapan テクノロジー部門BizXチームリーダー