2018.01.18 Thu |
テキスト解析入門その5(日本語での用例索引)

今まで、4回にわたってテキストマイニングを行ってきましたが、今回もその続編です。
今までの記事をまだ見ていない方はぜひご覧ください。
テキスト解析入門その1
http://ritsuan.com/blog/8035/
テキスト解析入門その2
http://ritsuan.com/blog/8138/
テキスト解析入門その3
http://ritsuan.com/blog/8164/
テキスト解析入門その4
今回は、用例索引を扱います。
今回扱うテキストデータは、前回同様、平成29年9月25日の安倍内閣総理大臣記者会見の安倍首相の演説文を扱います。
https://www.kantei.go.jp/jp/97_abe/statement/2017/0925kaiken.html
このリンク先の記事の安倍首相の発言だけを取り出し、ファイルに保存します。ファイル名を、Abe925.txt として保存します。
まずパッケージをロードします。
library(RMeCab)
次に日本語テキストの読み込みと形態素解析を行います。
result = RMeCabText(“Abe925.txt”)
形態素解析の結果を見てみましょう。
head(result)
 このリストの各成分の第一成分だけ抽出したいので、
このリストの各成分の第一成分だけ抽出したいので、
purrrパッケージのmap_chr関数と、
magrittrパッケージのextract関数を用いて抽出します。
まずはパッケージのロードから
library(purrr)
library(magrittr)
もしまだ入っていなければ以下を実行
install.packages(“purrr”,dependencies=T)
install.packages(“magrittr”,dependencies=T)
下記コマンドで形態素解析された結果の、各単語要素のみ抽出します。
result2 = map_chr(result,extract(1))
結果の頭出し
head(result2, n = 30)

ここで変数の名前を変えます。
data = result2
今回は「国民」という単語の前後を調べてみることにしましょう。
単語の位置情報を取得します。
word_position = which(data == “国民”)
結果の頭出し
head(word_position)
![]()
この位置情報を使っていきます。
たとえば、前後4文字を取り出したいなら、
一つ目の「国民」に対して、5番目を中心として、1~4、6~9を取り出し
data[c(1,2,3,4,5,6,7,8,9)]
![]() とすればいいわけですね。
とすればいいわけですね。
出力するときは、ダブルクオテーションを削除して文として出力したいので、
paste(data[c(1,2,3,4,5,6,7,8,9)], collapse = “”) とします。
![]() これを、各「国民」について行うので、
これを、各「国民」について行うので、
b=NULL
for(i in 1:length(word_position)){
a = word_position[i]
b[i] = paste(data[c((a-4):(a+4))], collapse = “”)
}
結果を表示
b
 このように、検索語に対して、その前後の文の一部を取り出すことで、検索語がどのように使われているかを可視化することを、用例索引と言います。
このように、検索語に対して、その前後の文の一部を取り出すことで、検索語がどのように使われているかを可視化することを、用例索引と言います。
ここでは、「国民の皆様」または「国民の信」という使われ方が多いことがわかります。国民を立てる言い方で、足り前ですが肯定的な言い方であることがわかります。
今回はしっかりと用例索引できたのですが、先ほどのコードでは、
(a-4)が0以下の時または、
(a+4)がlength(data)より大きいときに問題が起きます。
なので、その時ように書き換えると以下のようになります。
b=NULL
for(i in 1:length(word_position)){
a = word_position[i]
d = max(a-4,1)
e =min(a+4,length(data))
b[i] = paste(data[d:e], collapse = “”)
}
今回は、結果が全く同じですが、たとえば、検索語が、文章の冒頭にあったり、末尾にあった場合にこのコードでエラーを回避することができます。
また、もしも、検索語が中央に来るように、揃えたい場合は以下のようなコードになります。
n = length(word_position)
d = data.frame(before = rep(0,n),keyword = rep(0,n),after = rep(0,n))
for(i in 1:length(word_position)){
a = word_position[i]
b = max(a-4,1)
e =min(a+4,length(data))
f = min(a+1,length(data))
d[i,1] =paste(data[seq(b,(a-1))], collapse = “”)
d[i,2] = paste(data[a], collapse = “”)
d[i,3] = paste(data[seq(f,e)], collapse = “”)
}
結果
d
 ちょこっと見やすくなったかもしれません。
ちょこっと見やすくなったかもしれません。
この結果をcsvファイルに書き出してみましょう。
write.csv(d,”test.csv”,row.names=F)
そしてこれを、GoogleのSpreadSheetで開いてみましょう。
(Microsoft Excelで開くと文字化けする人がいるようなのでGoogleのSpreadSheetを推奨します)
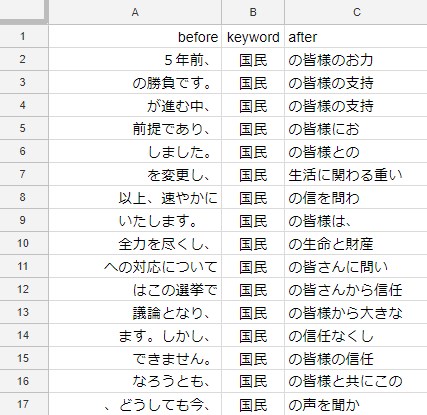 これだと見やすいですね。
これだと見やすいですね。
1列目を右揃え、2列目を中央ぞろえ、3列目を左揃えにしています。
各列に関して、評判分析を行って、その合計値を4列目に表示するのもありですね。
今回のような普通の文書に対して、用例索引を行っても大して面白くないのですが、大量のアンケート結果や、口コミデータに対して用例索引を行うといろいろわかることがあるようです。
今日はここまでにしましょう。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻博士課程
実践的機械学習勉強会 代表
株式会社パッパーレ 代表取締役社長
NPO法人Bizjapan テクノロジー部門BizXチームリーダー