2018.04.15 Sun |
Pythonでのクラスタリング1
みなさんは、クラスタリングという言葉を知っていますか?
機械学習の中でも、教師なし(つまりデータにラベルがついていない(猫の写真に猫とラベルがついてないなど))の機械学習に分類され、簡単に言えば、似た者同士グルーピングするものです。
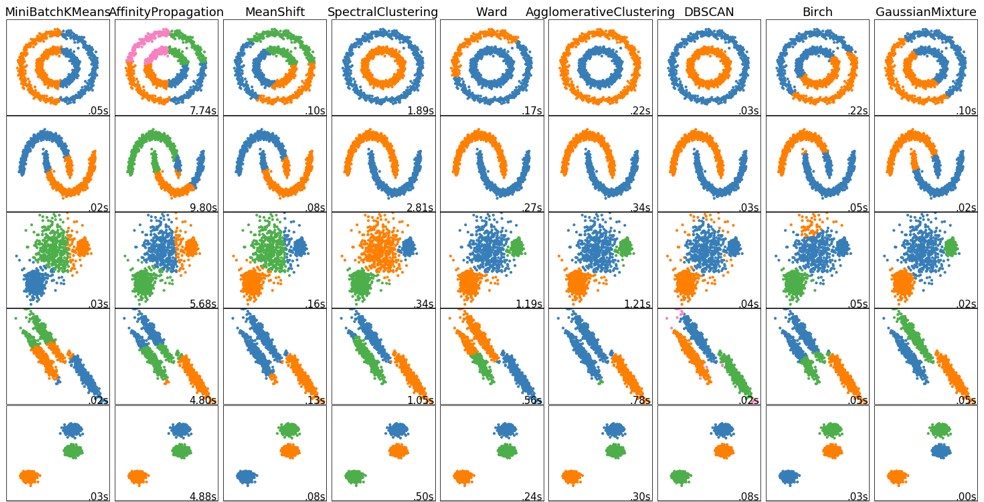
上にx軸y軸でプロットされた、2変数データが、青・緑・橙で色分けされています。
各列は、各クラスタリング手法で分けられており、各行は同一のデータセットになっています。
上の図からどの手法がどのデータセットに対して、どのようにクラスタリング(色で分けられている)するかをぱっと見でわかるようになっています。
もちろんハイパーパラメータをいじれば各手法でもクラスタリングの結果は大きく異なることがありますが、上の図はそのことはとりあえず無視しています。ただ、クラスタリングの結果を検証する一つの有力な方法であることは間違いないので、そういうものとして覚えておいて、損はないでしょう。
それでは、今回は、Pythonにおける古典的機械学習ライブラリであるsklearnライブラリのクラスタリング手法をいろいろ試してみたいと思います。
使用するデータは以下になります。
 https://www.kaggle.com/uciml/breast-cancer-wisconsin-data/data
https://www.kaggle.com/uciml/breast-cancer-wisconsin-data/data
このデータは、胸にしこりがある女性の腫瘍が悪性(Malignant)か良性(Benign)か、またそれぞれの特徴量(直径や硬さなど)はどのような値かを記録したものになります。
普通は教師あり機械学習の分類に使用する本データセットですが、今回は、ラベルを取ってクラスタリングしてみて、そのあとにラベルを見て、悪性と良性にどれくらい分類できているか(別のクラスターとして分けられているか)を見ていきたいと思います。
まずはjupyter notebookを起動し、上記websiteからデータセットをダウンロードいただき、今いるディレクトリへデータセットを移動してください。
今いるディレクトリは、
%pwd
を入力することで確認できます。
以下はコピペで実行できるようにコメントには#をつけます。
本wordpressの性質上、半角のダブルクオテーションも全角のダブルクオテーションとして表示されてしまうので、それは各自修正してください。
#データの読み込みに必要なPandasをimport
import pandas as pd
#データの読み込み
data = pd.read_csv(“data.csv”)
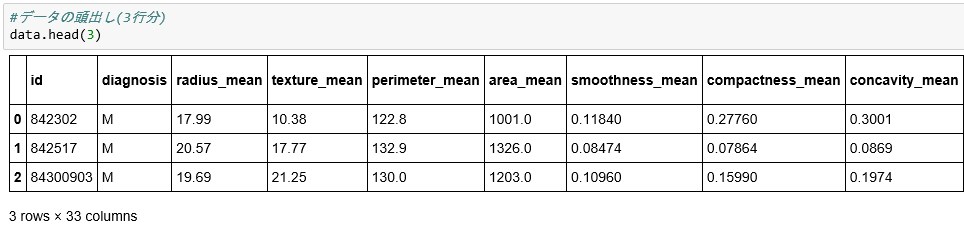
#データの頭出し(3行分)
data.head(3)
 #32列目をpandas.Dataframe.dropで消去(axis=1で列の指定。デフォルトだとaxis=0で行の指定。)
#32列目をpandas.Dataframe.dropで消去(axis=1で列の指定。デフォルトだとaxis=0で行の指定。)
data.drop(“Unnamed: 32”,axis=1,inplace=True)
#id列もいらないので消去
data.drop(“id”,axis=1,inplace=True)
#列名で削除を確認
data.columns
 #1列目のdiagnosis変数のMを1,Bを0に置き換え
#1列目のdiagnosis変数のMを1,Bを0に置き換え
data.diagnosis=data.diagnosis.map({‘M’:1,’B’:0})
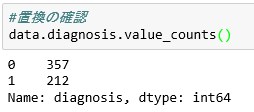
#置換の確認
data.diagnosis.value_counts()
#データ分割(学習用7割、テスト用3割)
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, test_size = 0.3,random_state=123)
#学習用説明変数の作成
train_X = train.iloc[:, 1:31]
#学習用目的変数の作成
train_y=train.diagnosis
#テスト用説明変数の作成
test_X= test.iloc[:, 1:31]
#テスト用目的変数の作成
test_y =test.diagnosis
#説明変数の標準化
#標準化に必要なモジュールのインポート
from sklearn import preprocessing
#標準化データの作成(各変数の平均を0、標準偏差を1にする)
train_X_scaled = preprocessing.scale(train_X)
test_X_scaled = preprocessing.scale(test_X)
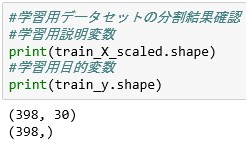
#学習用データセットの分割結果確認
#学習用説明変数
print(train_X_scaled.shape)
#学習用目的変数
print(train_y.shape)
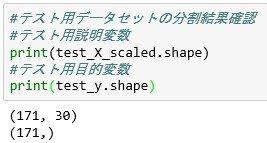
 #テスト用データセットの分割結果確認
#テスト用データセットの分割結果確認
#テスト用説明変数
print(test_X_scaled.shape)
#テスト用目的変数
print(test_y.shape)
 #学習用目的変数の頭出し
#学習用目的変数の頭出し
train_y.head()
 #テスト用目的変数の頭出し
#テスト用目的変数の頭出し
test_y.head()
 #それでは、まず、クラスタリングアルゴリズムとして最もシンプルなkmeans法から実行していきます。
#それでは、まず、クラスタリングアルゴリズムとして最もシンプルなkmeans法から実行していきます。
#KMeansモジュールのインポート
from sklearn.cluster import KMeans
#インスタンスの作成(今回は、悪性と良性の2クラスターに分かれることを予想し、n_cluster=2とします)
k_means = KMeans(n_clusters=2)
#学習用説明変数での学習
kmeans_fit = k_means.fit(train_X_scaled)
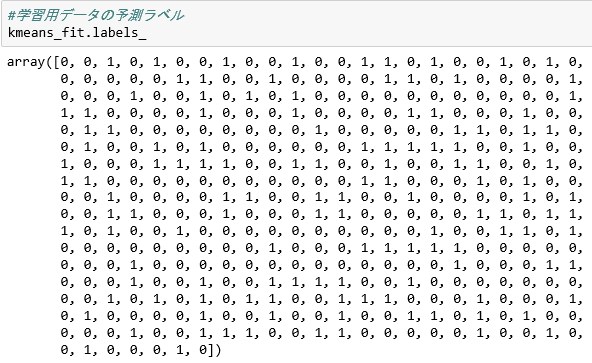
#学習用データの予測ラベル
kmeans_fit.labels_
 #metricsモジュールのインポート
#metricsモジュールのインポート
from sklearn import metrics
#混合行列の作成(各行がクラスタリング結果を表し、各列が、悪性か良性かを表す)
#対角成分の二つの数が大きければ、正確にクラスタリングできているといえる。
metrics.confusion_matrix(kmeans_fit.labels_,train_y)
 #テストデータのラベル予測
#テストデータのラベル予測
prediction = kmeans_fit.predict(test_X_scaled)
#テストデータの予測ラベル
print(prediction)
 #テストデータセットでの混合行列の作成
#テストデータセットでの混合行列の作成
#対角成分だけが大きいとクラスタリングは成功しているといえる。
metrics.confusion_matrix(prediction,test_y)
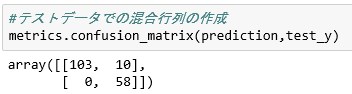
今回のデータセットに関しては、kmeans法で上手くクラスタリングできたようです。
次回以降に他のクラスタリング手法も試してみたいと思います。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカルゲノム専攻 博士課程
株式会社パッパーレ 代表取締役(https://www.pappare.co.jp/)
NPO法人Bizjapan テクノロジー部門BizXチームリーダー(http://bizjapan.org/en/)
実践的機械学習勉強会 代表( https://0f1304e65103e294f80c0307ba.doorkeeper.jp/ )