2017.09.26 Tue |
RのkerasパッケージでDeepLearning

データサイエンスの分野はR言語とPython言語が二大派閥となっており、最近特にブームとなっているDeepLearningのインターフェースが多くの場合Pythonであることから、Python勢力が日に日に大きくなってきています。
最近R言語の弱点であるDeepLearningの対応のためにRStudio社が、RでDeeplearningを行うためのkerasパッケージをリリースしました。
https://github.com/rstudio/keras
kerasパッケージは、良く知られた”keras”のR用インターフェースであり、バックエンドとして、TensorFlow, CNTK, Theanoを選択できます。CPUを使用するコードと同じコードでGPUを使用することも可能です。
今回は、MNIST datasetを隠れ層が二層のパーセプトロンで学習させてみたいと思います。MNISTは、0~9の数字の画像データで、このデータを学習させることで、次に数字の画像データを与えた時に、それが何の数字かをあてることができるようにすることが今回やることです。
それではやっていきましょう。
皆さんのノートパソコンでやっていただくことも可能なのですが、今回は、再現性確保のため、GoogleCloudPlatform ComputeEngineを使用します。AmazonWebServiceのElastic Compute Cloud(EC2)のようなものだとご理解ください。
今回は、
Machine Typeは、
n1-standard-2 (2 vCPUs, 7.5 GB memory)、
Zoneは、
us-central1-c(安かったので)
OSは、
Windows2016(Coreでない方)
を使用しています。
環境設定として、
R 3.4.1 for Windows
Rtools34
Anaconda 4.4.0 Python 3.6 version
をダウンロード・インストールしてあります。
それでは始めていきます。
#kerasパッケージのダウンロード・インストール
#cran mirrorはどこでもよいですがサーバーに近かったUSA CA1を選択しました。
install.packages(“keras”, dependencies=T)
#最新バージョンは、
#install.packages(“devtools”,dependencies=T)
#devtools::install_github(“rstudio/keras”)
#で得ることができます。この場合も不足パッケージがあるといわれるので
#reticulate,tensorflow,tfruns, magrittr, R6,toolsを入れてください。
#パッケージのメモリへのロード
library(keras)
#Tensorflowバックエンドのkerasコアライブラリをインストールするために、
#install_keras()コマンドが必要らしいです。
install_keras()
curlパッケージが入っていないと怒られるので、入れます。
install.packages(“curl”,dependencies=T)
再度、
install_keras()
を実行します。
これで、セットアップは完了です。
次にデータの準備をします。
KerasにMNISTデータセットが付属しているので、それをロードします。
mnist = dataset_mnist()
 AWSのs3からとってこられているみたいですね。
AWSのs3からとってこられているみたいですね。
読みこんだデータの構造を見てみましょう。
str(mnist)
 #学習用説明変数の作成
#学習用説明変数の作成
x_train = mnist$train$x
#学習用目的変数の作成
y_train = mnist$train$y
#テスト用説明変数の作成
x_test = mnist$test$x
#テスト用目的変数の作成
y_test = mnist$test$y
#試しに、学習用データの一つ目を見てみましょう。
mnist$train$x[1,,]
![mnist$train$x[1,,]](http://ritsuan.com/wp-content/uploads/2017/09/mnisttrainx1.png) 下と上が切れてしまっていますが、28行28列の行列となっており、白いところが0、大きな数字はより濃い黒となっています。
下と上が切れてしまっていますが、28行28列の行列となっており、白いところが0、大きな数字はより濃い黒となっています。
#学習用目的変数の頭出し
head(mnist$train$y)
#学習用目的変数の構成要素
unique(mnist$train$y)

さて次に説明変数の変形に移ります。
説明変数については変形が必要です。これは後でパーセプトロンの入力層にデータを入れやすくするために必要なことです。
どのように変形が必要かと言いますと、説明変数の各データが28行28列の行列になっているところを、28×28=784の計算から、1行784列に変えます。
まず元の次元数を確認します。
#元の次元数
dim(x_train)
dim(x_test)
#各データ28行28列の行列のところを
#各データ1行784列に変換します
dim(x_train) = c(nrow(x_train), 784)
dim(x_test) = c(nrow(x_test), 784)
#変換後の次元を確認します。
dim(x_train)
dim(x_test)
 #x_trainの最大値
#x_trainの最大値
max(x_train)
#x_trainの最小値
min(x_train)
#x_testの最大値
max(x_test)
#x_testの最小値
min(x_test)
 説明変数が、最小値0最大値255となっているため、最小値0最大値1になるように基準化する。
説明変数が、最小値0最大値255となっているため、最小値0最大値1になるように基準化する。
#説明変数の基準化
x_train = x_train / 255
x_test = x_test / 255
#基準化の結果
#x_trainの最大値
max(x_train)
#x_trainの最小値
min(x_train)
#x_testの最大値
max(x_test)
#x_testの最小値
min(x_test)
 つぎに目的変数の変換に移ります。
つぎに目的変数の変換に移ります。
目的変数は、各画像が数字の0-9のどれを指しているかの答えなので、現状、0-9の数字が格納されています。
この0-9の数字をone-hotベクトルに変換します。
たとえば、
数字の0なら、(1,0,0,0,0,0,0,0,0,0)
数字の1なら、(0,1,0,0,0,0,0,0,0,0)
数字の2なら、(0,0,1,0,0,0,0,0,0,0)
数字の3なら、(0,0,0,1,0,0,0,0,0,0)
・・・・
数字の9なら、(0,0,0,0,0,0,0,0,0,1)
といった具合です。
#目的変数のone-hotベクトル化
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
#目的変数変換の結果(それぞれ一つ目の成分)
y_train[1,]
y_test[1,]
 データの前処理は終わったので次は、neural networkを設計します。
データの前処理は終わったので次は、neural networkを設計します。
今回は、Sequential Modelを採用します。Sequential Modelとは、全結合層のことで、今回は全結合層を組み合わせた多層パーセプトロンを作成します。
まず、keras_model_sequential()関数を使用して、Sequential Modelを呼び出します。
#Sequential Modelの呼び出し
model = keras_model_sequential()
#784→32→relu→10→softmax
model %>%
layer_dense(units = 32, input_shape = c(784)) %>%
layer_activation(‘relu’) %>%
layer_dense(units = 10) %>%
layer_activation(‘softmax’)
この結果は、summary関数で確認できます。
summary(model)

Output Shapeの列を見てみると、たしかに、
784→32→relu→10→softmax
であることが分かります(reluとsoftmaxはActivationと表現されている)
次にモデルをコンパイルします。
今回は損失関数としてcategorical_crossentropy
最適化手法としてoptimizer_rmsprop()
評価基準としてaccuracyを指定しています。
#モデルのコンパイル
model %>% compile(
loss = ‘categorical_crossentropy’,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
学習はfit関数を用いる
#学習と評価
history = model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2
)
10秒くらいで計算が終わり、その結果であるhistoryをplotすると、
plot(history)
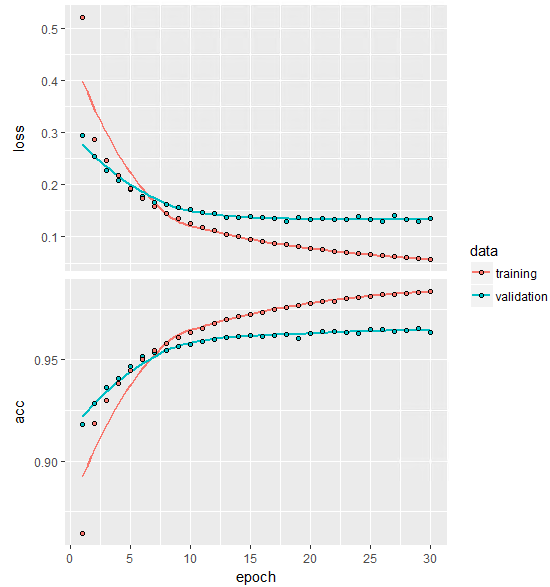 lossもaccも収束していますね。
lossもaccも収束していますね。
acc(accuracy)が0.96以上あり十分な精度が出ていることが分かります。
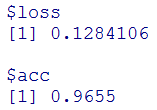
#テストデータを使った最終的な評価の結果
model %>% evaluate(x_test, y_test)
 #テストデータを使った予測値の算出
#テストデータを使った予測値の算出
prediction=model %>% predict_classes(x_test)

せっかくなのでもう一つモデルを作ってみます。
先ほどはノードをランダムに消すDropoutを設定しませんでした。
Dropoutは過学習を抑制するもので、非常によく用いられます。
今回も使用してみます。
Dropoutする比率は30%としてみます。
#Sequential Modelの呼び出し
model = keras_model_sequential()
#784→32→relu→Dropout(0.3)→10→Dropout(0.3)→softmax
model %>%
layer_dense(units = 32, input_shape = c(784)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10) %>%
layer_dropout(rate = 0.3) %>%
layer_activation(‘softmax’)
#summary関数でNeuralNetwork構造確認
summary(model)
 #モデルのコンパイル
#モデルのコンパイル
model %>% compile(
loss = ‘categorical_crossentropy’,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history = model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2
)
#lossとaccのプロット
plot(history)
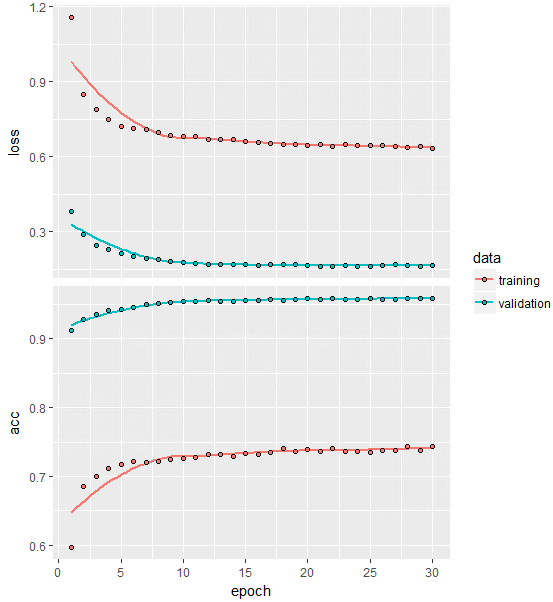 #テストデータを使った最終的な評価の結果
#テストデータを使った最終的な評価の結果
model %>% evaluate(x_test, y_test)
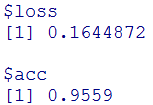 先ほどに比べると精度が下がっていますね(0.965→0.9559)。。
先ほどに比べると精度が下がっていますね(0.965→0.9559)。。
初めの層で、784→32としているため、dropoutはそれほど高くないほうがよさそうですね。dropoutの比率を10%をしてみましょう。
#Sequential Modelの呼び出し
model = keras_model_sequential()
#784→32→relu→Dropout(0.1)→10→Dropout(0.1)→softmax
model %>%
layer_dense(units = 32, input_shape = c(784)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.1) %>%
layer_dense(units = 10) %>%
layer_dropout(rate = 0.1) %>%
layer_activation(‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = ‘categorical_crossentropy’,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history = model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2
)
#lossとaccのプロット
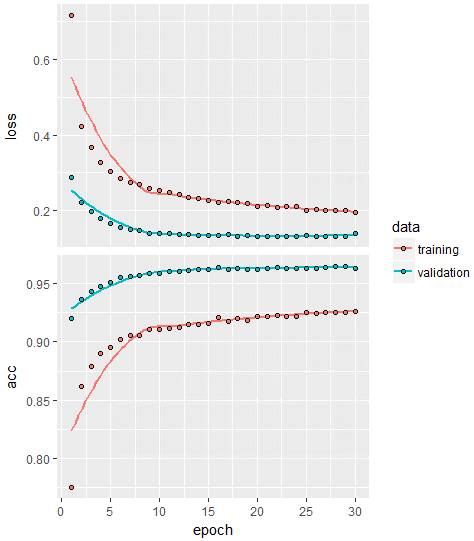
plot(history)
#テストデータを使った最終的な評価の結果
model %>% evaluate(x_test, y_test)
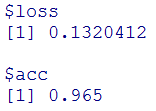 一番最初に行ったDropoutをいれないときのAccuracyは、0.9655で今回は0.965なので、0.005だけ減少し精度が悪くなりました。
一番最初に行ったDropoutをいれないときのAccuracyは、0.9655で今回は0.965なので、0.005だけ減少し精度が悪くなりました。
このモデルではこれ以上Dropoutを導入してもダメなようです。
では次にnetworkを別の観点から変えてみましょう。
先ほどの最高精度のnetworkは、
784→32→relu→10→softmaxでした。
今回は
784→256→relu→Dropout(0.4)→128→relu→Dropout(0.3)→10→softmax
というもう一層増やして、ノードの数を少しずつ下げていくことにします。
ノードの数が初め256と多いのでDropoutを40%とし、次のノードも128と多いのでDropoutを30%としています。
#Sequential Modelの呼び出し
model = keras_model_sequential()
#784→256→relu→Dropout(0.4)→128→relu→Dropout(0.3)→10→softmax
model %>%
layer_dense(units = 256, input_shape = c(784)) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128) %>%
layer_activation(‘relu’) %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10) %>%
layer_activation(‘softmax’)
#余談になりますが、ここでは、layer_denseとlayer_activationを分けて書いていますが、layer_denseの中に活性化関数の記述をすることもできその場合上のmodelは下のようにシンプルにかけます。
model %>%
layer_dense(units = 256, activation = “relu”, input_shape = c(784)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = “relu”) %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10, activation = “softmax”)
#モデルのコンパイル
model %>% compile(
loss = ‘categorical_crossentropy’,
optimizer = optimizer_rmsprop(),
metrics = c(‘accuracy’)
)
#学習と評価
history = model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2
)
#lossとaccのプロット
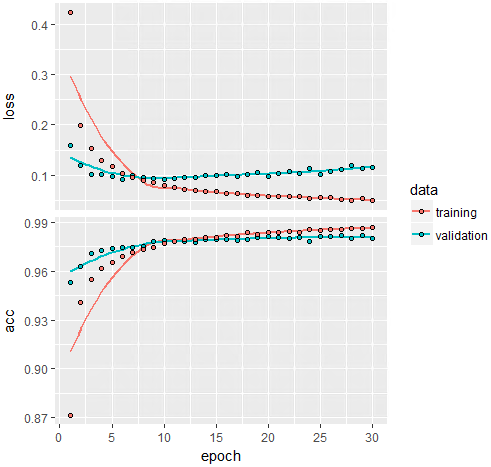
plot(history)
#テストデータを使った最終的な評価の結果
model %>% evaluate(x_test, y_test)
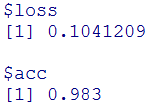 先ほどの一番良いモデルで、Accuracyが0.9655だったのに対し、今回は0.983とさらにアップしました!
先ほどの一番良いモデルで、Accuracyが0.9655だったのに対し、今回は0.983とさらにアップしました!
せっかくなので畳み込みneural network(CNN)でも試してみましょう。
ただ、CNNの場合、説明変数の次元を4次元の
(サンプル数、各サンプルの行数、各サンプルの列数、チャネル数)
※今回はグレースケールなのでチャネル数は1もしRGBならチャネル数3
にする必要があります。
今回は細かい説明は飛ばし、最終的な結果だけ出すことに専念します。
batch_size = 128
num_classes = 10
epochs = 12
#epochsは5くらいの方が早く終わってよいと思います。
#epochs12だと少なくとも60分かかります。
#入力次元
img_rows = 28
img_cols = 28
#データのロードと学習用データとテスト用データの作成
mnist = dataset_mnist()
x_train = mnist$train$x
y_train = mnist$train$y
x_test = mnist$test$x
y_test = mnist$test$y
dim(x_train) = c(nrow(x_train), img_rows, img_cols, 1)
dim(x_test) = c(nrow(x_test), img_rows, img_cols, 1)
input_shape = c(img_rows, img_cols, 1)
x_train = x_train / 255
x_test = x_test / 255
#目的変数をone-hotベクトルへ変換
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
#モデルの定義
model = keras_model_sequential()
model %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3), activation = ‘relu’,
input_shape = input_shape) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3), activation = ‘relu’) %>%
layer_max_pooling_2d(pool_size = c(2, 2)) %>%
layer_dropout(rate = 0.25) %>%
layer_flatten() %>%
layer_dense(units = 128, activation = ‘relu’) %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = num_classes, activation = ‘softmax’)
#モデルのコンパイル
model %>% compile(
loss = loss_categorical_crossentropy,
optimizer = optimizer_adadelta(),
metrics = c(‘accuracy’)
)
#学習と評価
model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = list(x_test, y_test)
)
#テストデータでの評価
model %>% evaluate(x_test, y_test)
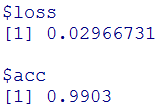 今までのAccuracyの最高値は、先ほどの、0.983だったので、今回0.9903はそれを上回る結果です。データが画像の場合は、畳み込みによる特徴量抽出が効いたみたいですね。ただ単純なパーセプトロンと比べ時間が20倍以上(合計1時間程度)かかってしまいました。CPUのコア数を増やすかGPUを使用するかしないと、PDCAは回しにくそうです。GCPのComputeEngine(GCPCE)ならCPUコアの数はより大きいものを選択できるのでそうするか、GCPCEでのGPU使用は申請してGPU使用するかですね。Rのコード自体は同じものが使えるので、大した労力ではありません。
今までのAccuracyの最高値は、先ほどの、0.983だったので、今回0.9903はそれを上回る結果です。データが画像の場合は、畳み込みによる特徴量抽出が効いたみたいですね。ただ単純なパーセプトロンと比べ時間が20倍以上(合計1時間程度)かかってしまいました。CPUのコア数を増やすかGPUを使用するかしないと、PDCAは回しにくそうです。GCPのComputeEngine(GCPCE)ならCPUコアの数はより大きいものを選択できるのでそうするか、GCPCEでのGPU使用は申請してGPU使用するかですね。Rのコード自体は同じものが使えるので、大した労力ではありません。
今回はここまでとします。
鈴木瑞人
東京大学大学院新領域創成科学研究科 メディカル情報生命専攻 博士課程
NPO法人Bizjapan テクノロジー部門BizXチームリーダー