2018.02.16 Fri |
POSデータ解析2(購買品目カテゴリからの来店予測)

前回に引き続きPOSデータ解析を行っていきます。
今回は、過去にどのカテゴリの商品をいくつ購入したかも説明変数に入れて、来店予測を行っていきたいと思います。
まずは前回同様、何年何月に何回来店したかと、年齢、居住地を、各顧客について、まとめます。
前回と同じところなので、コードだけ書きます。
#readrパッケージを使うのでロード。
library(readr)
#データセットがあるディレクトリに変更して、データを読み込む。
d = read_csv(“Tafeng.csv”)
#パッケージのロード
library(dplyr)
#顧客の属性
customer = d %>% select(CustID, Age, Area) %>% unique()
#来店履歴情報の作成。
#dから、Time列とCustID列を抽出。
visit = d %>% select(Time, CustID)
#時系列変数を扱うので、lubridateパッケージをロード。
library(lubridate)
#year列、month列、day列を作成。
visit1 = visit %>% mutate(Year = year(Time), Month = month(Time), Day = day(Time))
#CustID列、Year列、Month列に関して、グループ化して、各グループにおいて、
#日付の重複を取り除いた後に、何個ユニークな日付があるかを数える。
visit2 = visit1 %>%
group_by(CustID, Year, Month) %>%
summarise(Freq=length(unique(Time)))
#使用するパッケージをロード。
library(stringr)
#ym列を作成
visit3 = visit2 %>% mutate(ym = str_c(“x”,Year,”_”,Month))
#グループ化を解き、Year列とMonth列を消去。
visit4 = visit3 %>% ungroup() %>% select(-Year, -Month)
#パッケージをロード。
library(tidyr)
#long型からwide型へ変換
visit5 = visit4 %>% spread(key=ym, value=Freq, fill=0)
#各行に顧客の属性情報(Age列(年齢)、Area列(居住地域))を追加
visit6 = visit5 %>% left_join(customer, key=”CustID”)
#Age列と、Area列をFactor化。
visit6$Age = as.factor(visit6$Age)
visit6$Area = as.factor(visit6$Area)
 ここまでは、前回と同じです。
ここまでは、前回と同じです。
さて、次に購買履歴(何をいつ、いくつ買ったか)変数を作成します。
使用する変数は、
Time:購入日
CustID:顧客ID
ProductSubClass:商品のサブクラス
Amount:何個購入したか
です。
#dから、Time列とCustID列を抽出。
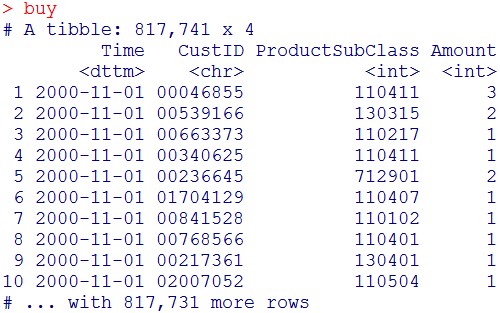
buy = d %>% select(Time, CustID, ProductSubClass, Amount)
buy
 #Year列とMonth列を作成
#Year列とMonth列を作成
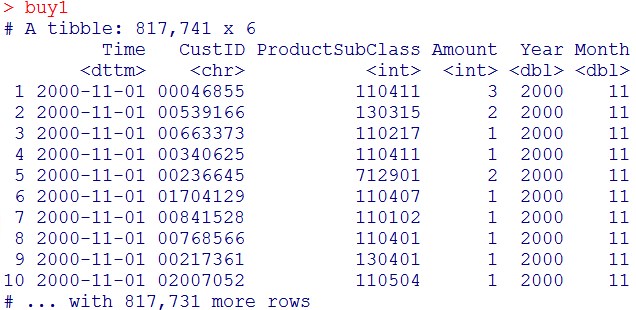
buy1 = buy %>% mutate(Year = year(Time), Month = month(Time))
buy1
 buy2 = buy1 %>% mutate(ymp = str_c(“x”,Year,”_”,Month,”_”,ProductSubClass))
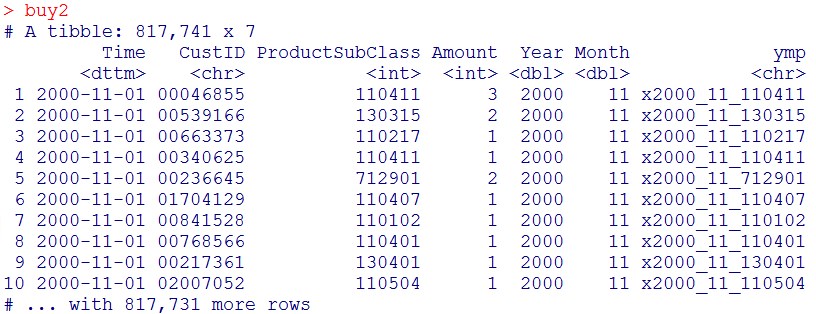
buy2 = buy1 %>% mutate(ymp = str_c(“x”,Year,”_”,Month,”_”,ProductSubClass))
buy2
 buy3 = buy2 %>% select(-Time, -ProductSubClass, -Year, -Month)
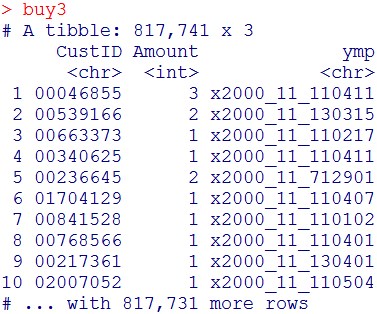
buy3 = buy2 %>% select(-Time, -ProductSubClass, -Year, -Month)
buy3
 buy4 = buy3 %>% group_by(CustID, ymp) %>% summarize(TotalAmount = sum(Amount))
buy4 = buy3 %>% group_by(CustID, ymp) %>% summarize(TotalAmount = sum(Amount))
buy4
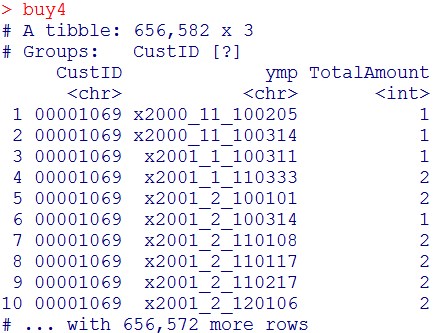 グループ化を解きます。
グループ化を解きます。
buy5 = ungroup(buy4)
buy5
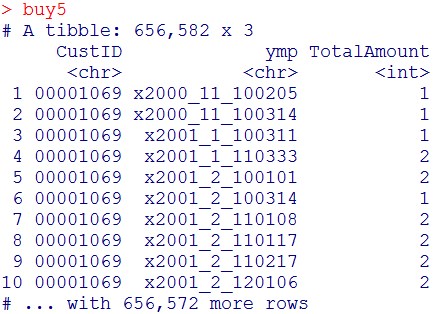 #パッケージのロード
#パッケージのロード
library(tidyr)
#long型からwide型へ変換します
buy6 = buy5 %>% spread(key=ymp, value=TotalAmount, fill=0)
buy6
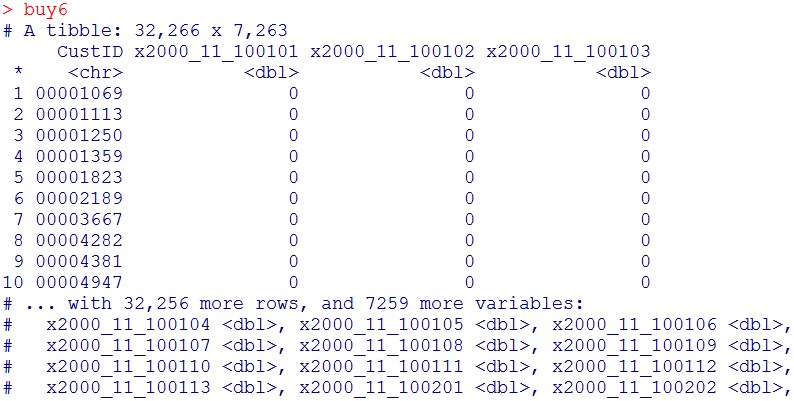 今回は、過去3か月分の購買情報を使って、次の1か月に来店するかどうかを予測したい。
今回は、過去3か月分の購買情報を使って、次の1か月に来店するかどうかを予測したい。
よって、2000年11月、2000年12月、2001年1月分の購買データ情報を持つ変数だけを選抜する。
(実際には、x2001_2で始まるもの以外を選抜)
buy7 = buy6 %>% select(-starts_with(“x2001_2”))
buy7
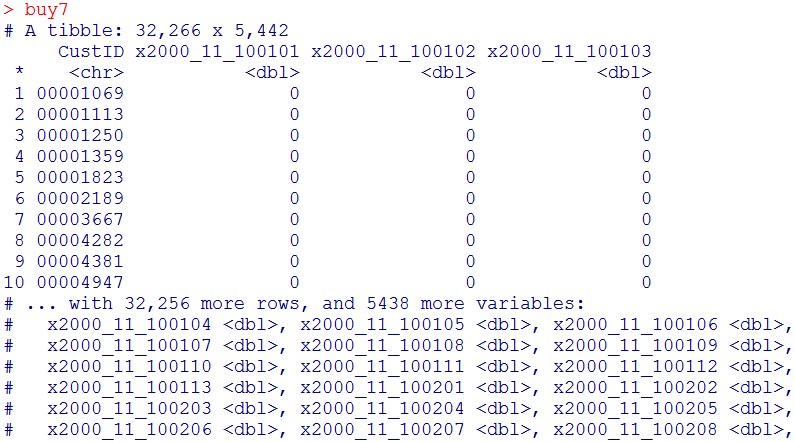 列数が7263から、5442に減ったのが分かります。
列数が7263から、5442に減ったのが分かります。
これで、2000年11月と2000年12月と2001年1月にどのカテゴリの商品をそれぞれいくつ購入したかのデータテーブルが出来上がりました。
CustIDをkeyとして、これを、visit6にleft_joinしましょう。
visit7 = visit6 %>% left_join(buy7, key=”CustID”)
visit7
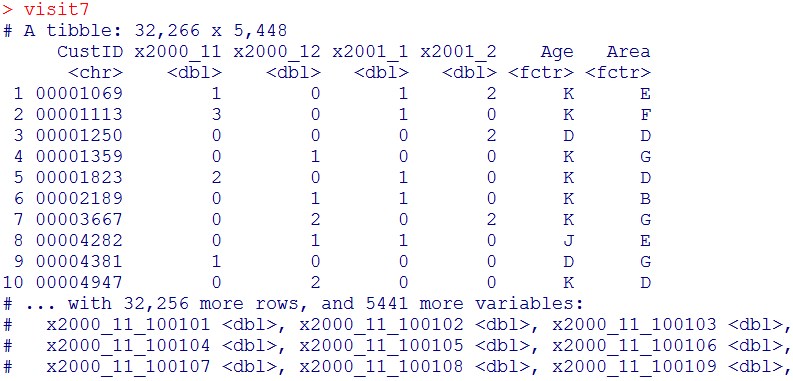 buy7が5442列、visit6が7列、visit7が5448列なので、上手く、CustIDをkeyとして、データテーブルをleft_joinできたのがわかるかなと思います。
buy7が5442列、visit6が7列、visit7が5448列なので、上手く、CustIDをkeyとして、データテーブルをleft_joinできたのがわかるかなと思います。
CustID列はいらないので消しましょう。
visit8 = visit7 %>% select(-CustID)
visit8
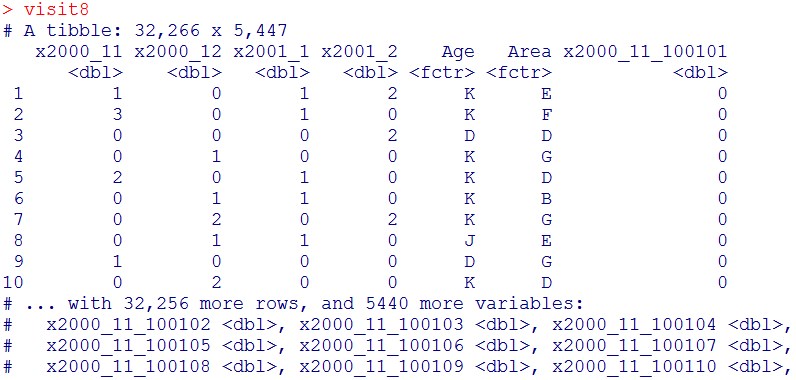 これで、前準備は完了しました。
これで、前準備は完了しました。
次に学習用データセットとテスト用データセットに分けます。
#再現性確保のために乱数の種をまきます。
set.seed(123)
#整数1~nrow(visit8)の中から、
#ランダムにnrow(visit8)*0.8個選択
ind = sample(nrow(visit8), nrow(visit8)*0.8)
#学習用データセット
train = visit8[ind,]
#テスト用データセット
test = visit8[-ind,]
#結果
dim(train)
dim(test)
 trainが、25812サンプル(行)、testが、6454サンプル(行)なので、確かに、8:2に分割されたのがわかるかなと思います。
trainが、25812サンプル(行)、testが、6454サンプル(行)なので、確かに、8:2に分割されたのがわかるかなと思います。
それでは、ランダムフォレストによる回帰を行っていきます。
今回は、rangerパッケージを使用します。
#rangerパッケージは、デフォルトでサーバのCPUをすべて使ってくれるので、
#randomForestパッケージと違って面倒な並列化設定の必要がありません。
#パッケージのロード
install.packages(“ranger”,dependencies=T)
library(ranger)
#モデル作成
rn = ranger(x2001_2 ~., data = train, importance = “impurity”, mtry = 30)
結果
rn

#テストデータでの予測
pred = predict(rn, test[,-4])
#予測結果の頭出し
head(pred$predictions)
![]()
#可視化用のデータフレームの作成
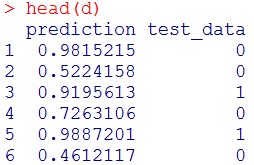
d = data.frame(prediction = pred$predictions, test_data = test$x2001_2)
#予測結果の頭出し
head(d)
#可視化用パッケージのロード
library(ggplot2)
#予測値と実際の値の散布図作成
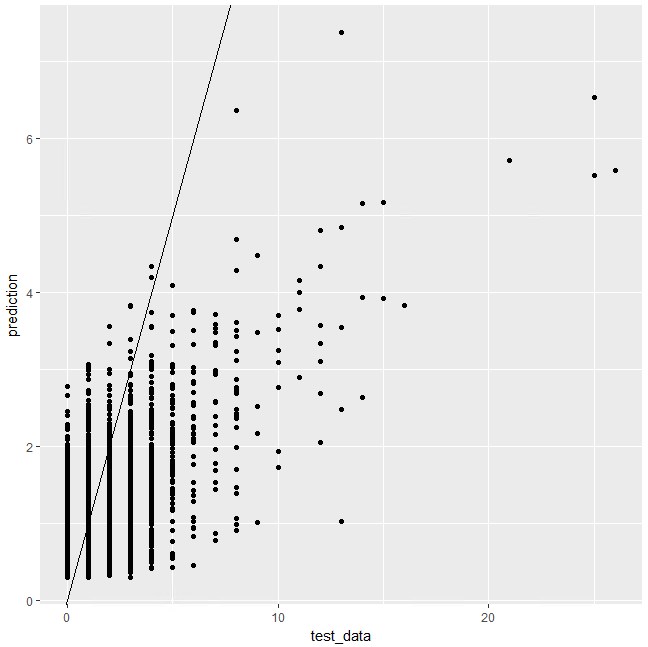
ggplot(d)+
geom_point(aes(x = test_data, y = prediction))+
geom_abline(intercept = 0, slope = 1)
#二乗平均平方根誤差(RMSE)
RMSE = sqrt(mean((pred$predictions – test$x2001_2)^2))
RMSE
![]() 前回、1,2,3か月前の来店回数だけから来店回数を予測したときは、RMSE=1.097でした。
前回、1,2,3か月前の来店回数だけから来店回数を予測したときは、RMSE=1.097でした。
どうやら精度は下がってしまったようです。
作成する木の数を4倍にしてみましょう。これは、num.trees引数に値を与えます。デフォルトだと、num.trees = 500なので、num.trees = 2000に変更してみます。
#モデル作成
rn = ranger(x2001_2 ~., data = train, importance = “impurity”, mtry = 30,num.trees = 2000)
#テストデータでの予測
pred = predict(rn, test[,-4])
#二乗平均平方根誤差(RMSE)
RMSE = sqrt(mean((pred$predictions – test$x2001_2)^2))
RMSE
![]() 先ほどとほとんど変わらないですね。。
先ほどとほとんど変わらないですね。。
mtryなどの引数をさらに振ってみると精度が上がることも考えられるのですが、特定の商品の購買が翌月の来店頻度に影響するかというと、しない気がするので今回はここまでにしましょう。
数千の説明変数と数万のデータサンプルに対してもrangerパッケージなら数十秒~数分で回帰を行うことができました。(CPUは16コア使用)
ということで今回はここまでにしたいと思います。
鈴木瑞人
東京大学大学院新領域創成科学研究科メディカル情報生命専攻博士課程
実践的機械学習勉強会 代表
株式会社パッパーレ 代表取締役社長
NPO法人Bizjapan テクノロジー部門BizXチームリーダー